 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Effectiveness of Convolutional Neural Networks for Answer Selection in End-to-End Question Answering
Jul 25, 2017
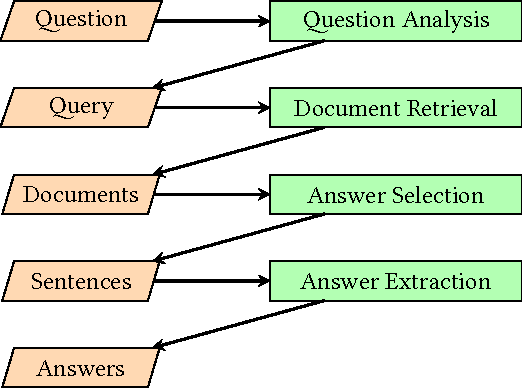

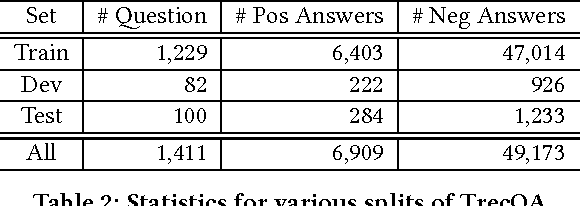
Most work on natural language question answering today focuses on answer selection: given a candidate list of sentences, determine which contains the answer. Although important, answer selection is only one stage in a standard end-to-end question answering pipeline. This paper explores the effectiveness of convolutional neural networks (CNNs) for answer selection in an end-to-end context using the standard TrecQA dataset. We observe that a simple idf-weighted word overlap algorithm forms a very strong baseline, and that despite substantial efforts by the community in applying deep learning to tackle answer selection, the gains are modest at best on this dataset. Furthermore, it is unclear if a CNN is more effective than the baseline in an end-to-end context based on standard retrieval metrics. To further explore this finding, we conducted a manual user evaluation, which confirms that answers from the CNN are detectably better than those from idf-weighted word overlap. This result suggests that users are sensitive to relatively small differences in answer selection quality.