 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Rank Intents in Voice Assistants
May 04, 2020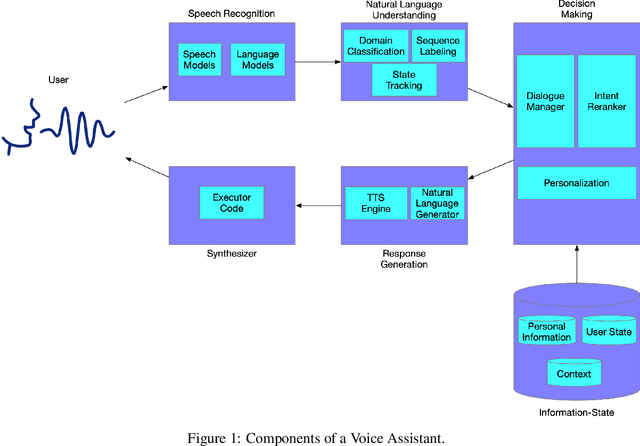

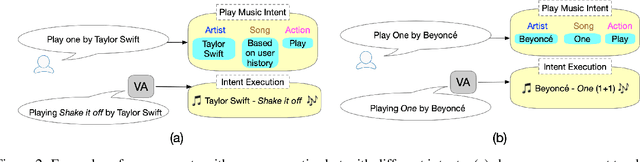
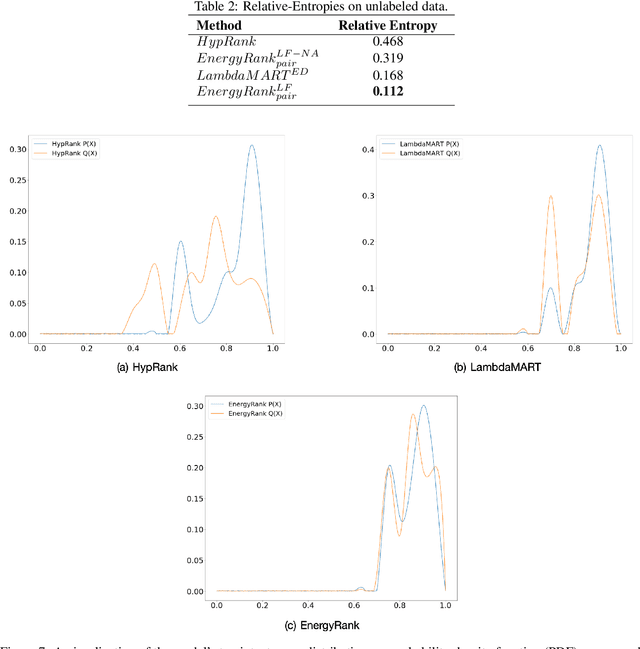
Voice Assistants aim to fulfill user requests by choosing the best intent from multiple options generated by its Automated Speech Recognition and Natural Language Understanding sub-systems. However, voice assistants do not always produce the expected results. This can happen because voice assistants choose from ambiguous intents - user-specific or domain-specific contextual information reduces the ambiguity of the user request. Additionally the user information-state can be leveraged to understand how relevant/executable a specific intent is for a user request. In this work, we propose a novel Energy-based model for the intent ranking task, where we learn an affinity metric and model the trade-off between extracted meaning from speech utterances and relevance/executability aspects of the intent. Furthermore we present a Multisource Denoising Autoencoder based pretraining that is capable of learning fused representations of data from multiple sources. We empirically show our approach outperforms existing state of the art methods by reducing the error-rate by 3.8%, which in turn reduces ambiguity and eliminates undesired dead-ends leading to better user experience. Finally, we evaluate the robustness of our algorithm on the intent ranking task and show our algorithm improves the robustness by 33.3%.