 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInnovator-VL: A Multimodal Large Language Model for Scientific Discovery
Jan 27, 2026We present Innovator-VL, a scientific multimodal large language model designed to advance understanding and reasoning across diverse scientific domains while maintaining excellent performance on general vision tasks. Contrary to the trend of relying on massive domain-specific pretraining and opaque pipelines, our work demonstrates that principled training design and transparent methodology can yield strong scientific intelligence with substantially reduced data requirements. (i) First, we provide a fully transparent, end-to-end reproducible training pipeline, covering data collection, cleaning, preprocessing, supervised fine-tuning, reinforcement learning, and evaluation, along with detailed optimization recipes. This facilitates systematic extension by the community. (ii) Second, Innovator-VL exhibits remarkable data efficiency, achieving competitive performance on various scientific tasks using fewer than five million curated samples without large-scale pretraining. These results highlight that effective reasoning can be achieved through principled data selection rather than indiscriminate scaling. (iii) Third, Innovator-VL demonstrates strong generalization, achieving competitive performance on general vision, multimodal reasoning, and scientific benchmarks. This indicates that scientific alignment can be integrated into a unified model without compromising general-purpose capabilities. Our practices suggest that efficient, reproducible, and high-performing scientific multimodal models can be built even without large-scale data, providing a practical foundation for future research.
CooperBench: Why Coding Agents Cannot be Your Teammates Yet
Jan 19, 2026Resolving team conflicts requires not only task-specific competence, but also social intelligence to find common ground and build consensus. As AI agents increasingly collaborate on complex work, they must develop coordination capabilities to function as effective teammates. Yet we hypothesize that current agents lack these capabilities. To test this, we introduce CooperBench, a benchmark of over 600 collaborative coding tasks across 12 libraries in 4 programming languages. Each task assigns two agents different features that can be implemented independently but may conflict without proper coordination. Tasks are grounded in real open-source repositories with expert-written tests. Evaluating state-of-the-art coding agents, we observe the curse of coordination: agents achieve on average 30% lower success rates when working together compared to performing both tasks individually. This contrasts sharply with human teams, where adding teammates typically improves productivity. Our analysis reveals three key issues: (1) communication channels become jammed with vague, ill-timed, and inaccurate messages; (2) even with effective communication, agents deviate from their commitments; and (3) agents often hold incorrect expectations about others' plans and communication. Through large-scale simulation, we also observe rare but interesting emergent coordination behavior including role division, resource division, and negotiation. Our research presents a novel benchmark for collaborative coding and calls for a shift from pursuing individual agent capability to developing social intelligence.
Direct Confidence Alignment: Aligning Verbalized Confidence with Internal Confidence In Large Language Models
Dec 12, 2025



Producing trustworthy and reliable Large Language Models (LLMs) has become increasingly important as their usage becomes more widespread. Calibration seeks to achieve this by improving the alignment between the model's confidence and the actual likelihood of its responses being correct or desirable. However, it has been observed that the internal confidence of a model, derived from token probabilities, is not well aligned with its verbalized confidence, leading to misleading results with different calibration methods. In this paper, we propose Direct Confidence Alignment (DCA), a method using Direct Preference Optimization to align an LLM's verbalized confidence with its internal confidence rather than ground-truth accuracy, enhancing model transparency and reliability by ensuring closer alignment between the two confidence measures. We evaluate DCA across multiple open-weight LLMs on a wide range of datasets. To further assess this alignment, we also introduce three new calibration error-based metrics. Our results show that DCA improves alignment metrics on certain model architectures, reducing inconsistencies in a model's confidence expression. However, we also show that it can be ineffective on others, highlighting the need for more model-aware approaches in the pursuit of more interpretable and trustworthy LLMs.
ERGO: Entropy-guided Resetting for Generation Optimization in Multi-turn Language Models
Oct 15, 2025Large Language Models (LLMs) suffer significant performance degradation in multi-turn conversations when information is presented incrementally. Given that multi-turn conversations characterize everyday interactions with LLMs, this degradation poses a severe challenge to real world usability. We hypothesize that abrupt increases in model uncertainty signal misalignment in multi-turn LLM interactions, and we exploit this insight to dynamically realign conversational context. We introduce ERGO (Entropy-guided Resetting for Generation Optimization), which continuously quantifies internal uncertainty via Shannon entropy over next token distributions and triggers adaptive prompt consolidation when a sharp spike in entropy is detected. By treating uncertainty as a first class signal rather than a nuisance to eliminate, ERGO embraces variability in language and modeling, representing and responding to uncertainty. In multi-turn tasks with incrementally revealed instructions, ERGO yields a 56.6% average performance gain over standard baselines, increases aptitude (peak performance capability) by 24.7%, and decreases unreliability (variability in performance) by 35.3%, demonstrating that uncertainty aware interventions can improve both accuracy and reliability in conversational AI.
FAIRE: Assessing Racial and Gender Bias in AI-Driven Resume Evaluations
Apr 02, 2025In an era where AI-driven hiring is transforming recruitment practices, concerns about fairness and bias have become increasingly important. To explore these issues, we introduce a benchmark, FAIRE (Fairness Assessment In Resume Evaluation), to test for racial and gender bias in large language models (LLMs) used to evaluate resumes across different industries. We use two methods-direct scoring and ranking-to measure how model performance changes when resumes are slightly altered to reflect different racial or gender identities. Our findings reveal that while every model exhibits some degree of bias, the magnitude and direction vary considerably. This benchmark provides a clear way to examine these differences and offers valuable insights into the fairness of AI-based hiring tools. It highlights the urgent need for strategies to reduce bias in AI-driven recruitment. Our benchmark code and dataset are open-sourced at our repository: https://github.com/athenawen/FAIRE-Fairness-Assessment-In-Resume-Evaluation.git.
ConQuer: A Framework for Concept-Based Quiz Generation
Mar 18, 2025



Quizzes play a crucial role in education by reinforcing students' understanding of key concepts and encouraging self-directed exploration. However, compiling high-quality quizzes can be challenging and require deep expertise and insight into specific subject matter. Although LLMs have greatly enhanced the efficiency of quiz generation, concerns remain regarding the quality of these AI-generated quizzes and their educational impact on students. To address these issues, we introduce ConQuer, a concept-based quiz generation framework that leverages external knowledge sources. We employ comprehensive evaluation dimensions to assess the quality of the generated quizzes, using LLMs as judges. Our experiment results demonstrate a 4.8% improvement in evaluation scores and a 77.52% win rate in pairwise comparisons against baseline quiz sets. Ablation studies further underscore the effectiveness of each component in our framework. Code available at https://github.com/sofyc/ConQuer.
EgoNormia: Benchmarking Physical Social Norm Understanding
Feb 27, 2025Human activity is moderated by norms. When performing actions in the real world, humans not only follow norms, but also consider the trade-off between different norms However, machines are often trained without explicit supervision on norm understanding and reasoning, especially when the norms are grounded in a physical and social context. To improve and evaluate the normative reasoning capability of vision-language models (VLMs), we present EgoNormia $\|\epsilon\|$, consisting of 1,853 ego-centric videos of human interactions, each of which has two related questions evaluating both the prediction and justification of normative actions. The normative actions encompass seven categories: safety, privacy, proxemics, politeness, cooperation, coordination/proactivity, and communication/legibility. To compile this dataset at scale, we propose a novel pipeline leveraging video sampling, automatic answer generation, filtering, and human validation. Our work demonstrates that current state-of-the-art vision-language models lack robust norm understanding, scoring a maximum of 45% on EgoNormia (versus a human bench of 92%). Our analysis of performance in each dimension highlights the significant risks of safety, privacy, and the lack of collaboration and communication capability when applied to real-world agents. We additionally show that through a retrieval-based generation method, it is possible to use EgoNomia to enhance normative reasoning in VLMs.
CAMPHOR: Collaborative Agents for Multi-input Planning and High-Order Reasoning On Device
Oct 12, 2024While server-side Large Language Models (LLMs) demonstrate proficiency in function calling and complex reasoning, deploying Small Language Models (SLMs) directly on devices brings opportunities to improve latency and privacy but also introduces unique challenges for accuracy and memory. We introduce CAMPHOR, an innovative on-device SLM multi-agent framework designed to handle multiple user inputs and reason over personal context locally, ensuring privacy is maintained. CAMPHOR employs a hierarchical architecture where a high-order reasoning agent decomposes complex tasks and coordinates expert agents responsible for personal context retrieval, tool interaction, and dynamic plan generation. By implementing parameter sharing across agents and leveraging prompt compression, we significantly reduce model size, latency, and memory usage. To validate our approach, we present a novel dataset capturing multi-agent task trajectories centered on personalized mobile assistant use-cases. Our experiments reveal that fine-tuned SLM agents not only surpass closed-source LLMs in task completion F1 by~35\% but also eliminate the need for server-device communication, all while enhancing privacy.
UI-JEPA: Towards Active Perception of User Intent through Onscreen User Activity
Sep 06, 2024
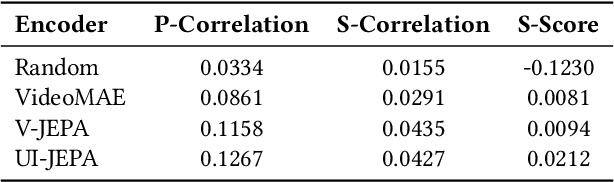


Generating user intent from a sequence of user interface (UI) actions is a core challenge in comprehensive UI understanding. Recent advancements in multimodal large language models (MLLMs) have led to substantial progress in this area, but their demands for extensive model parameters, computing power, and high latency makes them impractical for scenarios requiring lightweight, on-device solutions with low latency or heightened privacy. Additionally, the lack of high-quality datasets has hindered the development of such lightweight models. To address these challenges, we propose UI-JEPA, a novel framework that employs masking strategies to learn abstract UI embeddings from unlabeled data through self-supervised learning, combined with an LLM decoder fine-tuned for user intent prediction. We also introduce two new UI-grounded multimodal datasets, "Intent in the Wild" (IIW) and "Intent in the Tame" (IIT), designed for few-shot and zero-shot UI understanding tasks. IIW consists of 1.7K videos across 219 intent categories, while IIT contains 914 videos across 10 categories. We establish the first baselines for these datasets, showing that representations learned using a JEPA-style objective, combined with an LLM decoder, can achieve user intent predictions that match the performance of state-of-the-art large MLLMs, but with significantly reduced annotation and deployment resources. Measured by intent similarity scores, UI-JEPA outperforms GPT-4 Turbo and Claude 3.5 Sonnet by 10.0% and 7.2% respectively, averaged across two datasets. Notably, UI-JEPA accomplishes the performance with a 50.5x reduction in computational cost and a 6.6x improvement in latency in the IIW dataset. These results underscore the effectiveness of UI-JEPA, highlighting its potential for lightweight, high-performance UI understanding.
SwiftSage: A Generative Agent with Fast and Slow Thinking for Complex Interactive Tasks
May 27, 2023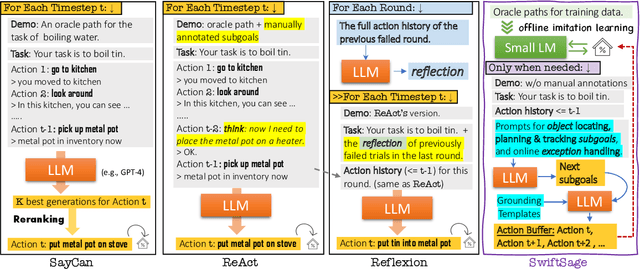
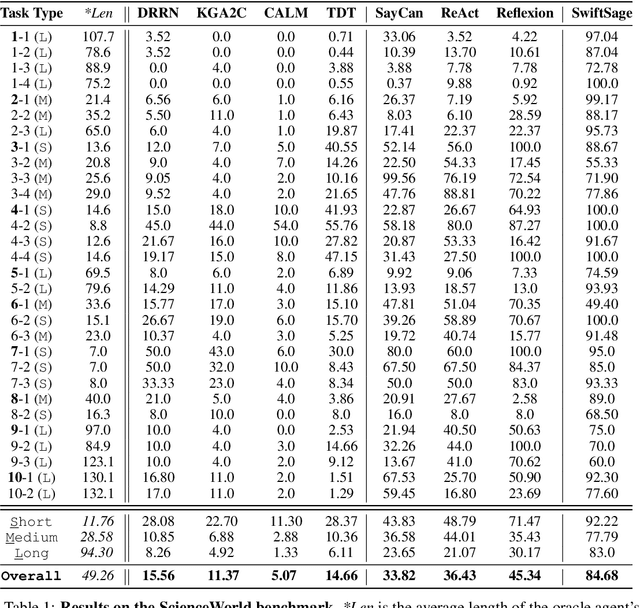
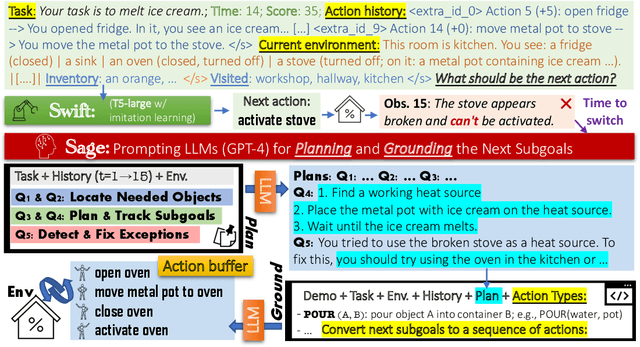
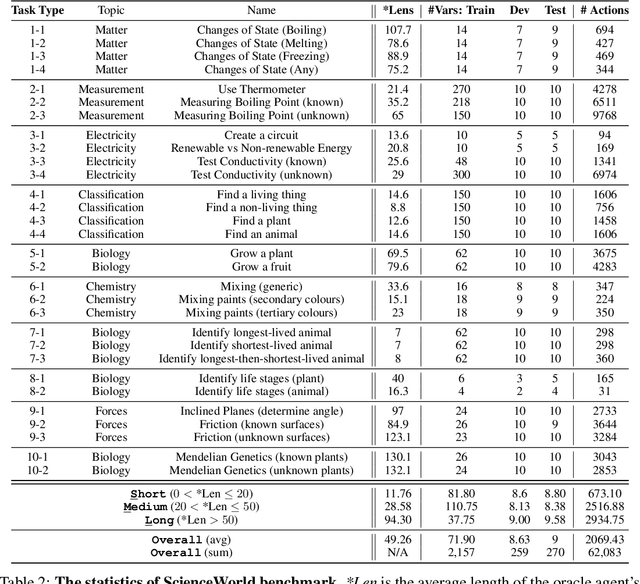
We introduce SwiftSage, a novel agent framework inspired by the dual-process theory of human cognition, designed to excel in action planning for complex interactive reasoning tasks. SwiftSage integrates the strengths of behavior cloning and prompting large language models (LLMs) to enhance task completion performance. The framework comprises two primary modules: the Swift module, representing fast and intuitive thinking, and the Sage module, emulating deliberate thought processes. The Swift module is a small encoder-decoder LM fine-tuned on the oracle agent's action trajectories, while the Sage module employs LLMs such as GPT-4 for subgoal planning and grounding. We develop a heuristic method to harmoniously integrate the two modules, resulting in a more efficient and robust problem-solving process. In 30 tasks from the ScienceWorld benchmark, SwiftSage significantly outperforms other methods such as SayCan, ReAct, and Reflexion, demonstrating its effectiveness in solving complex real-world tasks.