 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubric-Guided Self-Distillation: Post-Training Without Rubric Verifiers
Jun 10, 2026Rubrics have emerged as an alternative to RLVR in open-ended domains where a single ground-truth final answer is not available. Existing rubric-based training methods rely on an LLM verifier that scores each rollout against rubrics. This introduces substantial training-time overhead, exposes optimization to verifier-specific biases, and reduces rubric feedback to a sparse end-of-trajectory signal. We propose Rubric-Guided Self-Distillation (RGSD), a verifier-free training method in which the base policy, conditioned on the rubric, serves as the teacher for the unconditioned student. RGSD distills the rubric-conditioned teacher distribution into the student token-by-token, replacing sparse trajectory-level rewards with dense per-token learning signals and removing the LLM judge from the training loop entirely. Across Qwen-2.5 (3B, 7B) and Qwen3-Thinking (4B, 8B) models on medical and science domains, RGSD achieves rubric satisfaction comparable to judge-based GRPO while using one on-policy rollout per prompt and no training-time verifier calls. Ablations show that raw rubrics provide a stronger teacher enrichment signal than self-generated reference responses, while a stronger GRPO judge can outperform RGSD in some settings, positioning RGSD as a complementary verifier-free alternative when verifier cost or reliability is the bottleneck.
Not Every Rubric Teaches Equally: Policy-Aware Rubric Rewards for RLVR
May 19, 2026Reinforcement learning with verifiable rewards has made post-training highly effective when correctness can be checked automatically. However, many important model behaviors require satisfying several qualitative criteria at once. Rubric-based rewards address this setting by grading prompt-specific criteria and aggregating them into a scalar reward. Yet standard static aggregations conflate a criterion's human-assigned importance with its current usefulness as an optimization signal. We show that this assumption breaks down in rubric RL: many important criteria are already saturated or currently unreachable, while criteria that distinguish rollouts are not necessarily those with the largest human weights. We introduce POW3R, a policy-aware rubric reward framework that preserves human weights and category balance as the rubric objective while adapting criterion-level reward weights during training. POW3R uses rollout-level contrast to emphasize criteria that currently separate the policy's outputs, making the GRPO reward more informative without changing the underlying evaluation target. Across three base policies on two datasets spanning multimodal and text-only settings, POW3R wins $24$ of $30$ base-policy/metric comparisons, improving both mean rubric reward and strict completion (the fraction of prompts whose response satisfies every required rubric criterion) over vanilla GRPO with rubric rewards, and reaches the same plateau in $2.5$--$4\times$ fewer training steps. Rubric rewards should therefore distinguish what should matter in the final answer from what can teach the current policy.
Reward Hacking in Rubric-Based Reinforcement Learning
May 12, 2026Reinforcement learning with verifiable rewards has enabled strong post-training gains in domains such as math and coding, though many open-ended settings rely on rubric-based rewards. We study reward hacking in rubric-based RL, where a policy is optimized against a training verifier but evaluated against a cross-family panel of three frontier judges, reducing dependence on any single evaluator. Our framework separates two sources of divergence: verifier failure, where the training verifier credits rubric criteria that reference verifiers reject, and rubric-design limitations, where even strong rubric-based verifiers favor responses that rubric-free judges rate worse overall. Across medical and science domains, weak verifiers produce large proxy-reward gains that do not transfer to the reference verifiers; exploitation grows over training and concentrates in recurring failures such as partial satisfaction of compound criteria, treating implicit content as explicit, and imprecise topical matching. Stronger verifiers substantially reduce, but do not eliminate, verifier exploitation. We also introduce a self-internalization gap, a verifier-free diagnostic based on policy log-probabilities, which tracks reference-verifier quality, detecting when the policy trained using the weak verifier stops improving. Finally, in our setting, stronger verification does not prevent reward hacking when the rubric leaves important failure modes unspecified: rubric-based verifiers prefer the RL checkpoint, while rubric-free judges prefer the base model. These disagreements coincide with gains concentrated in completeness and presence-based criteria, alongside declines in factual correctness, conciseness, relevance, and overall quality. Together, these results suggest that stronger verification reduces reward hacking, but does not by itself ensure that rubric gains correspond to broader quality gains.
Commonsense Knowledge with Negation: A Resource to Enhance Negation Understanding
Apr 21, 2026Negation is a common and important semantic feature in natural language, yet Large Language Models (LLMs) struggle when negation is involved in natural language understanding tasks. Commonsense knowledge, on the other hand, despite being a well-studied topic, lacks investigations involving negation. In this work, we show that commonsense knowledge with negation is challenging for models to understand. We present a novel approach to automatically augment existing commonsense knowledge corpora with negation, yielding two new corpora containing over 2M triples with if-then relations. In addition, pre-training LLMs on our corpora benefits negation understanding.
Online Rubrics Elicitation from Pairwise Comparisons
Oct 08, 2025
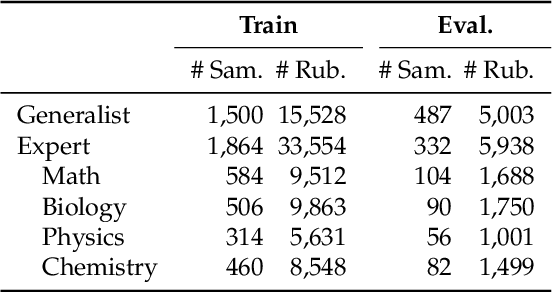
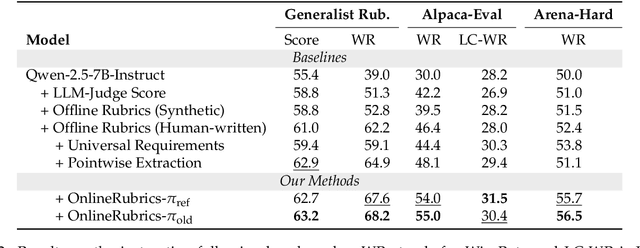
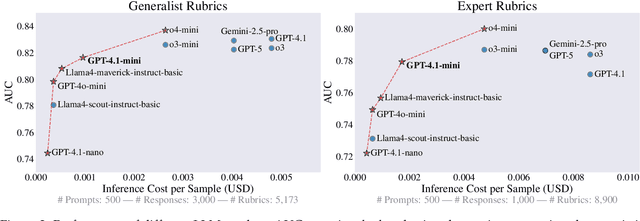
Rubrics provide a flexible way to train LLMs on open-ended long-form answers where verifiable rewards are not applicable and human preferences provide coarse signals. Prior work shows that reinforcement learning with rubric-based rewards leads to consistent gains in LLM post-training. Most existing approaches rely on rubrics that remain static over the course of training. Such static rubrics, however, are vulnerable to reward-hacking type behaviors and fail to capture emergent desiderata that arise during training. We introduce Online Rubrics Elicitation (OnlineRubrics), a method that dynamically curates evaluation criteria in an online manner through pairwise comparisons of responses from current and reference policies. This online process enables continuous identification and mitigation of errors as training proceeds. Empirically, this approach yields consistent improvements of up to 8% over training exclusively with static rubrics across AlpacaEval, GPQA, ArenaHard as well as the validation sets of expert questions and rubrics. We qualitatively analyze the elicited criteria and identify prominent themes such as transparency, practicality, organization, and reasoning.
EgoNormia: Benchmarking Physical Social Norm Understanding
Feb 27, 2025Human activity is moderated by norms. When performing actions in the real world, humans not only follow norms, but also consider the trade-off between different norms However, machines are often trained without explicit supervision on norm understanding and reasoning, especially when the norms are grounded in a physical and social context. To improve and evaluate the normative reasoning capability of vision-language models (VLMs), we present EgoNormia $\|\epsilon\|$, consisting of 1,853 ego-centric videos of human interactions, each of which has two related questions evaluating both the prediction and justification of normative actions. The normative actions encompass seven categories: safety, privacy, proxemics, politeness, cooperation, coordination/proactivity, and communication/legibility. To compile this dataset at scale, we propose a novel pipeline leveraging video sampling, automatic answer generation, filtering, and human validation. Our work demonstrates that current state-of-the-art vision-language models lack robust norm understanding, scoring a maximum of 45% on EgoNormia (versus a human bench of 92%). Our analysis of performance in each dimension highlights the significant risks of safety, privacy, and the lack of collaboration and communication capability when applied to real-world agents. We additionally show that through a retrieval-based generation method, it is possible to use EgoNomia to enhance normative reasoning in VLMs.
Making Language Models Robust Against Negation
Feb 11, 2025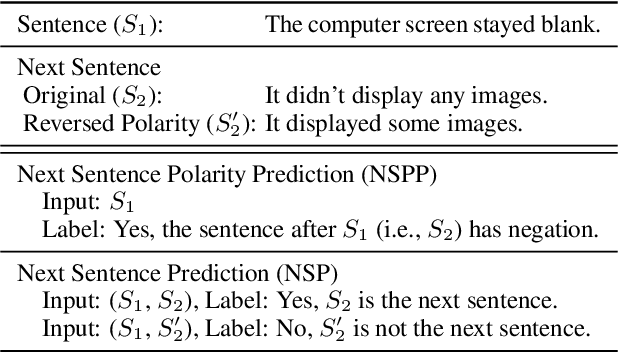
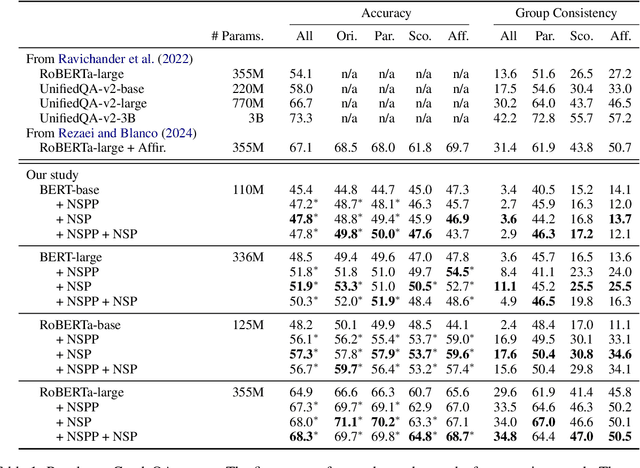
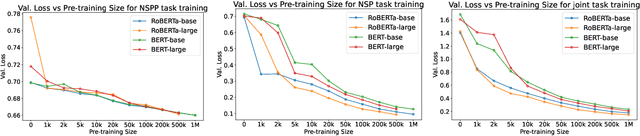

Negation has been a long-standing challenge for language models. Previous studies have shown that they struggle with negation in many natural language understanding tasks. In this work, we propose a self-supervised method to make language models more robust against negation. We introduce a novel task, Next Sentence Polarity Prediction (NSPP), and a variation of the Next Sentence Prediction (NSP) task. We show that BERT and RoBERTa further pre-trained on our tasks outperform the off-the-shelf versions on nine negation-related benchmarks. Most notably, our pre-training tasks yield between 1.8% and 9.1% improvement on CondaQA, a large question-answering corpus requiring reasoning over negation.
Paraphrasing in Affirmative Terms Improves Negation Understanding
Jun 11, 2024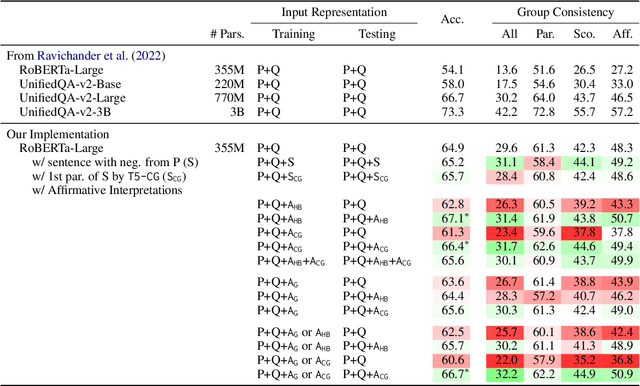


Negation is a common linguistic phenomenon. Yet language models face challenges with negation in many natural language understanding tasks such as question answering and natural language inference. In this paper, we experiment with seamless strategies that incorporate affirmative interpretations (i.e., paraphrases without negation) to make models more robust against negation. Crucially, our affirmative interpretations are obtained automatically. We show improvements with CondaQA, a large corpus requiring reasoning with negation, and five natural language understanding tasks.
Interpreting Indirect Answers to Yes-No Questions in Multiple Languages
Oct 20, 2023
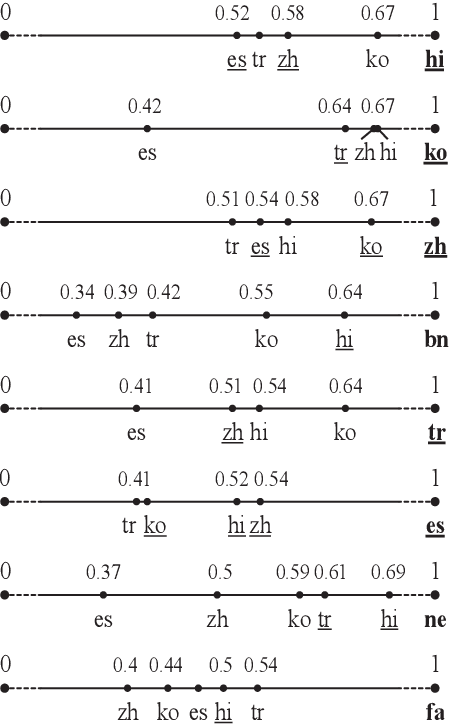
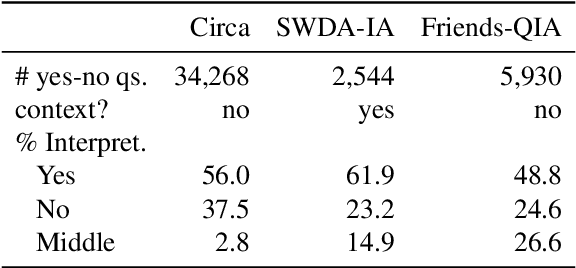

Yes-no questions expect a yes or no for an answer, but people often skip polar keywords. Instead, they answer with long explanations that must be interpreted. In this paper, we focus on this challenging problem and release new benchmarks in eight languages. We present a distant supervision approach to collect training data. We also demonstrate that direct answers (i.e., with polar keywords) are useful to train models to interpret indirect answers (i.e., without polar keywords). Experimental results demonstrate that monolingual fine-tuning is beneficial if training data can be obtained via distant supervision for the language of interest (5 languages). Additionally, we show that cross-lingual fine-tuning is always beneficial (8 languages).