 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECEPTICON: How Dark Patterns Manipulate Web Agents
Dec 28, 2025Deceptive UI designs, widely instantiated across the web and commonly known as dark patterns, manipulate users into performing actions misaligned with their goals. In this paper, we show that dark patterns are highly effective in steering agent trajectories, posing a significant risk to agent robustness. To quantify this risk, we introduce DECEPTICON, an environment for testing individual dark patterns in isolation. DECEPTICON includes 700 web navigation tasks with dark patterns -- 600 generated tasks and 100 real-world tasks, designed to measure instruction-following success and dark pattern effectiveness. Across state-of-the-art agents, we find dark patterns successfully steer agent trajectories towards malicious outcomes in over 70% of tested generated and real-world tasks -- compared to a human average of 31%. Moreover, we find that dark pattern effectiveness correlates positively with model size and test-time reasoning, making larger, more capable models more susceptible. Leading countermeasures against adversarial attacks, including in-context prompting and guardrail models, fail to consistently reduce the success rate of dark pattern interventions. Our findings reveal dark patterns as a latent and unmitigated risk to web agents, highlighting the urgent need for robust defenses against manipulative designs.
AutoLibra: Agent Metric Induction from Open-Ended Feedback
May 05, 2025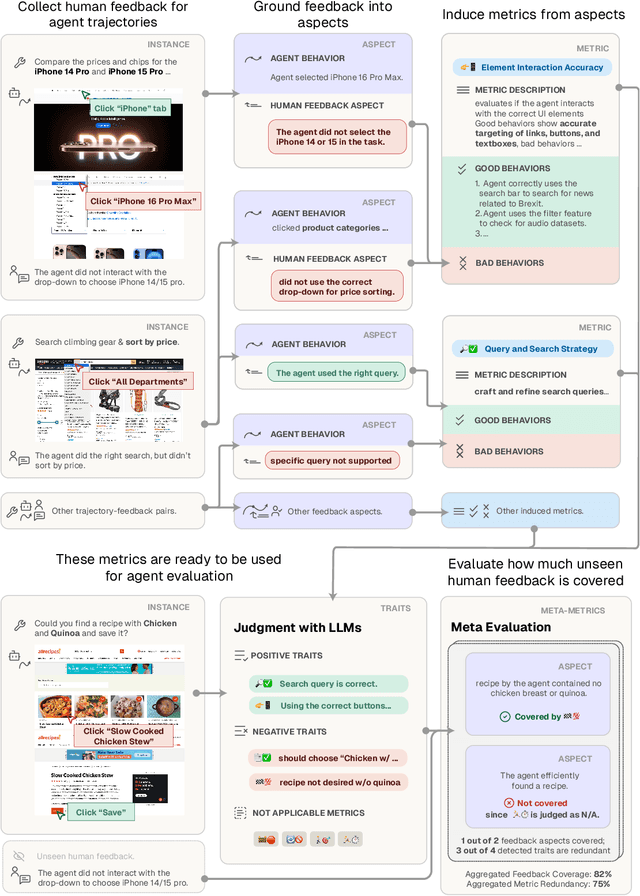



Agents are predominantly evaluated and optimized via task success metrics, which are coarse, rely on manual design from experts, and fail to reward intermediate emergent behaviors. We propose AutoLibra, a framework for agent evaluation, that transforms open-ended human feedback, e.g., "If you find that the button is disabled, don't click it again", or "This agent has too much autonomy to decide what to do on its own", into metrics for evaluating fine-grained behaviors in agent trajectories. AutoLibra accomplishes this by grounding feedback to an agent's behavior, clustering similar positive and negative behaviors, and creating concrete metrics with clear definitions and concrete examples, which can be used for prompting LLM-as-a-Judge as evaluators. We further propose two meta-metrics to evaluate the alignment of a set of (induced) metrics with open feedback: "coverage" and "redundancy". Through optimizing these meta-metrics, we experimentally demonstrate AutoLibra's ability to induce more concrete agent evaluation metrics than the ones proposed in previous agent evaluation benchmarks and discover new metrics to analyze agents. We also present two applications of AutoLibra in agent improvement: First, we show that AutoLibra-induced metrics serve as better prompt-engineering targets than the task success rate on a wide range of text game tasks, improving agent performance over baseline by a mean of 20%. Second, we show that AutoLibra can iteratively select high-quality fine-tuning data for web navigation agents. Our results suggest that AutoLibra is a powerful task-agnostic tool for evaluating and improving language agents.
EgoNormia: Benchmarking Physical Social Norm Understanding
Feb 27, 2025Human activity is moderated by norms. When performing actions in the real world, humans not only follow norms, but also consider the trade-off between different norms However, machines are often trained without explicit supervision on norm understanding and reasoning, especially when the norms are grounded in a physical and social context. To improve and evaluate the normative reasoning capability of vision-language models (VLMs), we present EgoNormia $\|\epsilon\|$, consisting of 1,853 ego-centric videos of human interactions, each of which has two related questions evaluating both the prediction and justification of normative actions. The normative actions encompass seven categories: safety, privacy, proxemics, politeness, cooperation, coordination/proactivity, and communication/legibility. To compile this dataset at scale, we propose a novel pipeline leveraging video sampling, automatic answer generation, filtering, and human validation. Our work demonstrates that current state-of-the-art vision-language models lack robust norm understanding, scoring a maximum of 45% on EgoNormia (versus a human bench of 92%). Our analysis of performance in each dimension highlights the significant risks of safety, privacy, and the lack of collaboration and communication capability when applied to real-world agents. We additionally show that through a retrieval-based generation method, it is possible to use EgoNomia to enhance normative reasoning in VLMs.