 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
Paper and Code

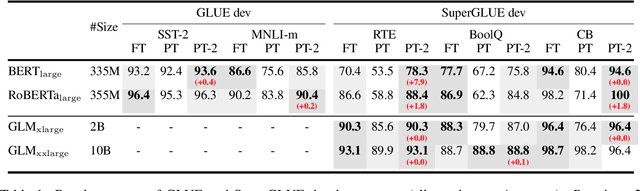


Prompt tuning, which only tunes continuous prompts with a frozen language model, substantially reduces per-task storage and memory usage at training. However, in the context of NLU, prior work reveals that prompt tuning does not perform well for normal-sized pre-trained models. We also find that existing methods of prompt tuning cannot handle hard sequence tagging tasks, indicating a lack of universality. We present a novel empirical finding that properly optimized prompt tuning can be universally effective across a wide range of model scales and NLU tasks. It matches the performance of fine-tuning while having only 0.1\%-3\% tuned parameters. Our method P-Tuning v2 is not a new method, but a version of prefix-tuning \cite{li2021prefix} optimized and adapted for NLU. Given the universality and simplicity of P-Tuning v2, we believe it can serve as an alternative to fine-tuning and a strong baseline for future research.