 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen can transformers reason with abstract symbols?
Paper and Code


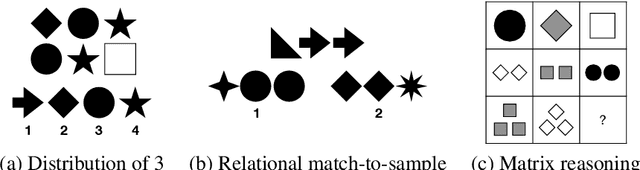
We investigate the capabilities of transformer large language models (LLMs) on relational reasoning tasks involving abstract symbols. Such tasks have long been studied in the neuroscience literature as fundamental building blocks for more complex abilities in programming, mathematics, and verbal reasoning. For (i) regression tasks, we prove that transformers generalize when trained, but require astonishingly large quantities of training data. For (ii) next-token-prediction tasks with symbolic labels, we show an "inverse scaling law": transformers fail to generalize as their embedding dimension increases. For both settings (i) and (ii), we propose subtle transformer modifications which can reduce the amount of data needed by adding two trainable parameters per head.