 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecret mixtures of experts inside your LLM
Dec 20, 2025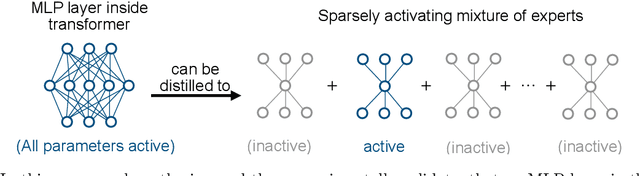

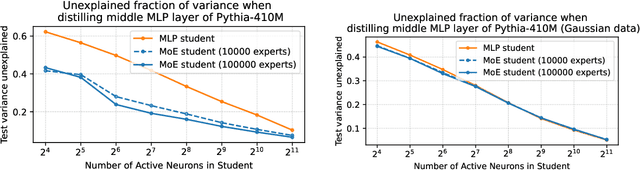
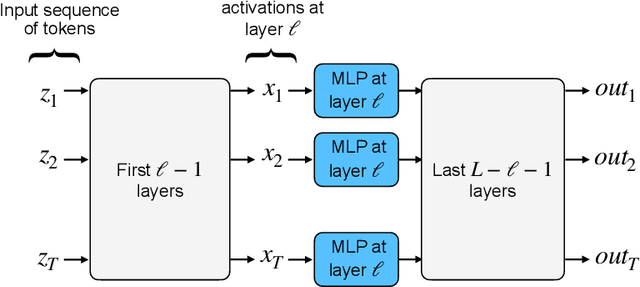
Despite being one of the earliest neural network layers, the Multilayer Perceptron (MLP) is arguably one of the least understood parts of the transformer architecture due to its dense computation and lack of easy visualization. This paper seeks to understand the MLP layers in dense LLM models by hypothesizing that these layers secretly approximately perform a sparse computation -- namely, that they can be well approximated by sparsely-activating Mixture of Experts (MoE) layers. Our hypothesis is based on a novel theoretical connection between MoE models and Sparse Autoencoder (SAE) structure in activation space. We empirically validate the hypothesis on pretrained LLMs, and demonstrate that the activation distribution matters -- these results do not hold for Gaussian data, but rather rely crucially on structure in the distribution of neural network activations. Our results shine light on a general principle at play in MLP layers inside LLMs, and give an explanation for the effectiveness of modern MoE-based transformers. Additionally, our experimental explorations suggest new directions for more efficient MoE architecture design based on low-rank routers.
Let Me Think! A Long Chain-of-Thought Can Be Worth Exponentially Many Short Ones
May 27, 2025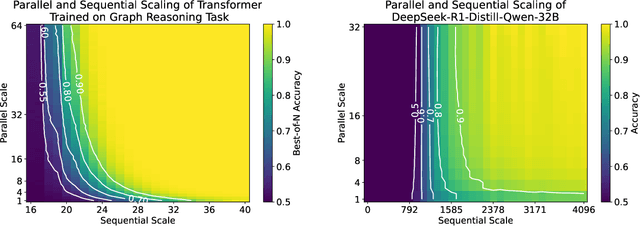

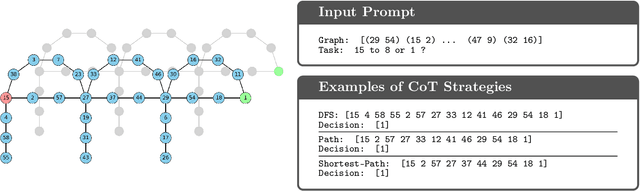
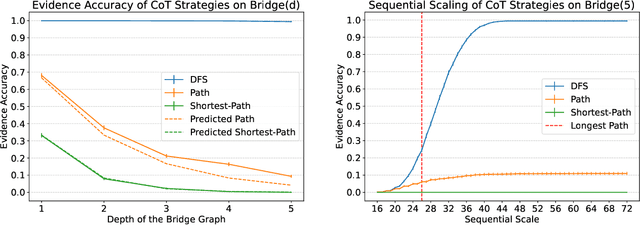
Inference-time computation has emerged as a promising scaling axis for improving large language model reasoning. However, despite yielding impressive performance, the optimal allocation of inference-time computation remains poorly understood. A central question is whether to prioritize sequential scaling (e.g., longer chains of thought) or parallel scaling (e.g., majority voting across multiple short chains of thought). In this work, we seek to illuminate the landscape of test-time scaling by demonstrating the existence of reasoning settings where sequential scaling offers an exponential advantage over parallel scaling. These settings are based on graph connectivity problems in challenging distributions of graphs. We validate our theoretical findings with comprehensive experiments across a range of language models, including models trained from scratch for graph connectivity with different chain of thought strategies as well as large reasoning models.
The power of fine-grained experts: Granularity boosts expressivity in Mixture of Experts
May 11, 2025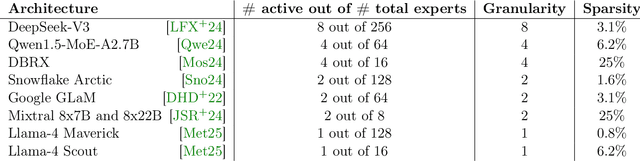
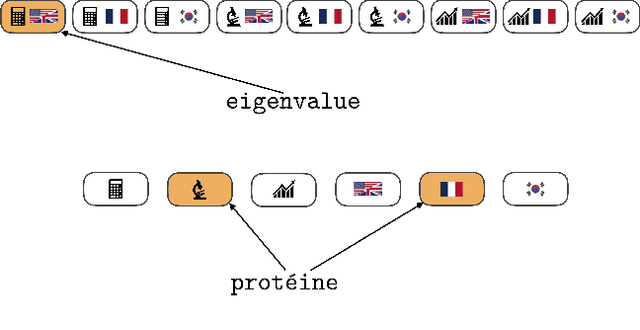
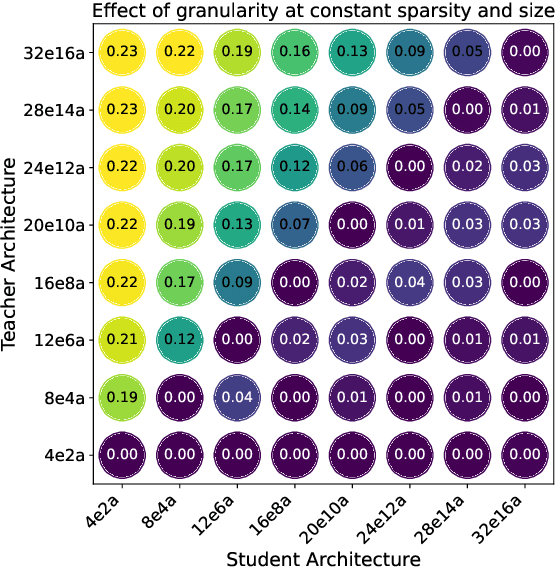
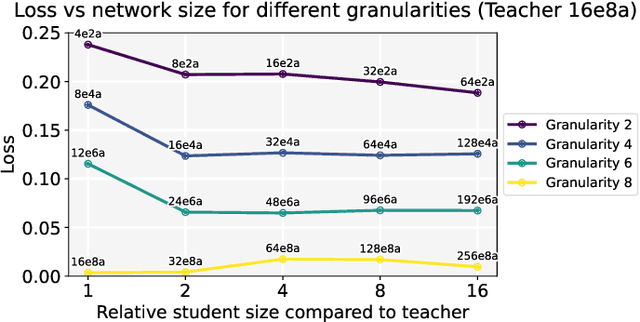
Mixture-of-Experts (MoE) layers are increasingly central to frontier model architectures. By selectively activating parameters, they reduce computational cost while scaling total parameter count. This paper investigates the impact of the number of active experts, termed granularity, comparing architectures with many (e.g., 8 per layer in DeepSeek) to those with fewer (e.g., 1 per layer in Llama-4 models). We prove an exponential separation in network expressivity based on this design parameter, suggesting that models benefit from higher granularity. Experimental results corroborate our theoretical findings and illustrate this separation.
On the inductive bias of infinite-depth ResNets and the bottleneck rank
Jan 31, 2025We compute the minimum-norm weights of a deep linear ResNet, and find that the inductive bias of this architecture lies between minimizing nuclear norm and rank. This implies that, with appropriate hyperparameters, deep nonlinear ResNets have an inductive bias towards minimizing bottleneck rank.
Towards a theory of model distillation
Mar 14, 2024Distillation is the task of replacing a complicated machine learning model with a simpler model that approximates the original [BCNM06,HVD15]. Despite many practical applications, basic questions about the extent to which models can be distilled, and the runtime and amount of data needed to distill, remain largely open. To study these questions, we initiate a general theory of distillation, defining PAC-distillation in an analogous way to PAC-learning [Val84]. As applications of this theory: (1) we propose new algorithms to extract the knowledge stored in the trained weights of neural networks -- we show how to efficiently distill neural networks into succinct, explicit decision tree representations when possible by using the ``linear representation hypothesis''; and (2) we prove that distillation can be much cheaper than learning from scratch, and make progress on characterizing its complexity.
PROPANE: Prompt design as an inverse problem
Nov 13, 2023
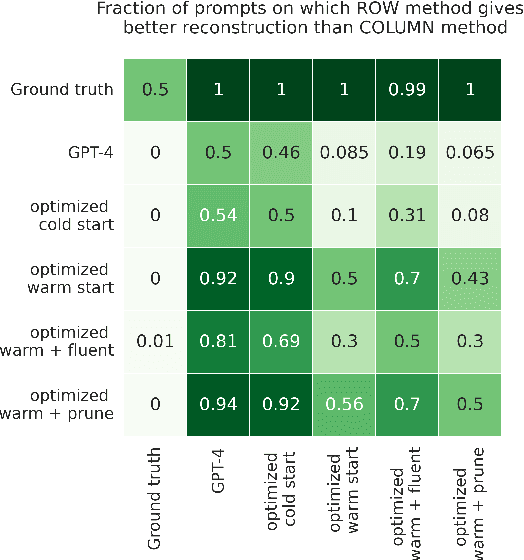
Carefully-designed prompts are key to inducing desired behavior in Large Language Models (LLMs). As a result, great effort has been dedicated to engineering prompts that guide LLMs toward particular behaviors. In this work, we propose an automatic prompt optimization framework, PROPANE, which aims to find a prompt that induces semantically similar outputs to a fixed set of examples without user intervention. We further demonstrate that PROPANE can be used to (a) improve existing prompts, and (b) discover semantically obfuscated prompts that transfer between models.
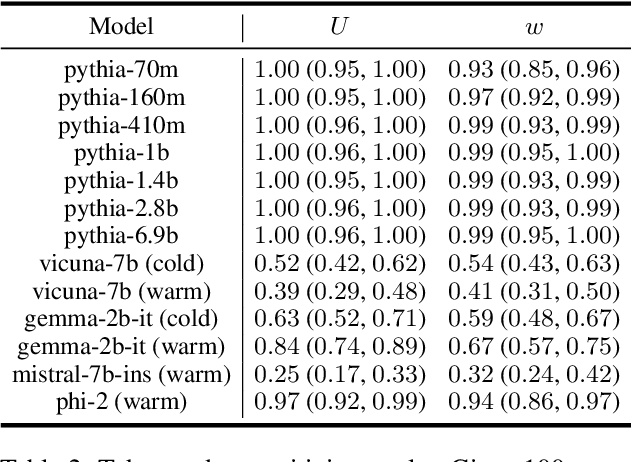
When can transformers reason with abstract symbols?
Oct 15, 2023

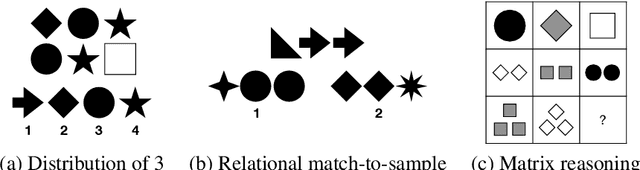
We investigate the capabilities of transformer large language models (LLMs) on relational reasoning tasks involving abstract symbols. Such tasks have long been studied in the neuroscience literature as fundamental building blocks for more complex abilities in programming, mathematics, and verbal reasoning. For (i) regression tasks, we prove that transformers generalize when trained, but require astonishingly large quantities of training data. For (ii) next-token-prediction tasks with symbolic labels, we show an "inverse scaling law": transformers fail to generalize as their embedding dimension increases. For both settings (i) and (ii), we propose subtle transformer modifications which can reduce the amount of data needed by adding two trainable parameters per head.
Transformers learn through gradual rank increase
Jun 12, 2023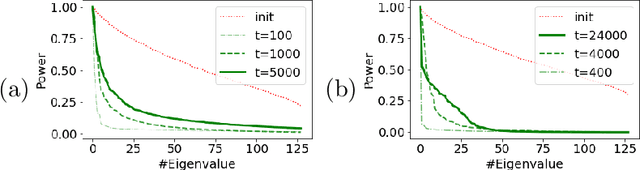
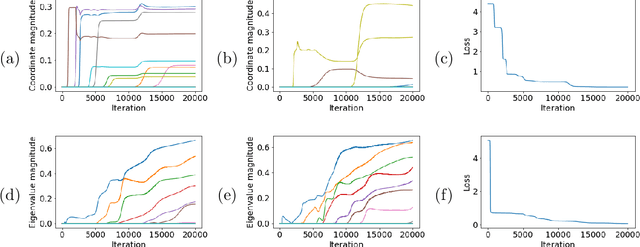
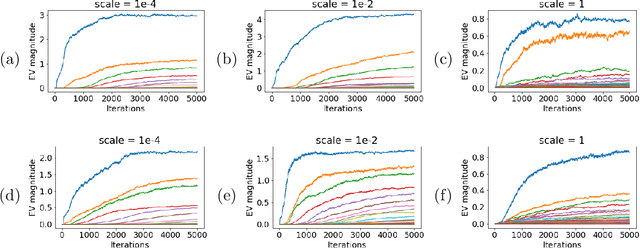

We identify incremental learning dynamics in transformers, where the difference between trained and initial weights progressively increases in rank. We rigorously prove this occurs under the simplifying assumptions of diagonal weight matrices and small initialization. Our experiments support the theory and also show that phenomenon can occur in practice without the simplifying assumptions.
The NTK approximation is valid for longer than you think
May 22, 2023We study when the neural tangent kernel (NTK) approximation is valid for training a model with the square loss. In the lazy training setting of Chizat et al. 2019, we show that rescaling the model by a factor of $\alpha = O(T)$ suffices for the NTK approximation to be valid until training time $T$. Our bound is tight and improves on the previous bound of Chizat et al. 2019, which required a larger rescaling factor of $\alpha = O(T^2)$.
SGD learning on neural networks: leap complexity and saddle-to-saddle dynamics
Feb 21, 2023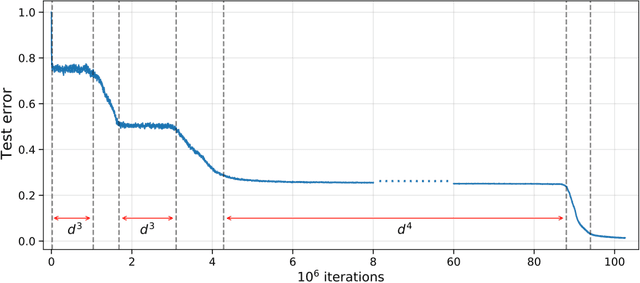
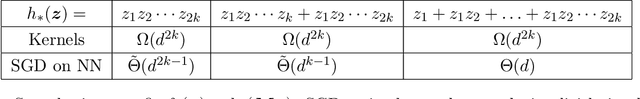
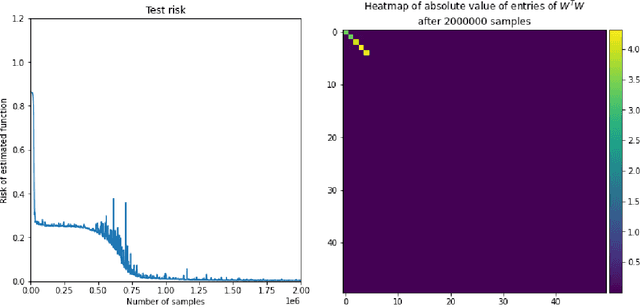
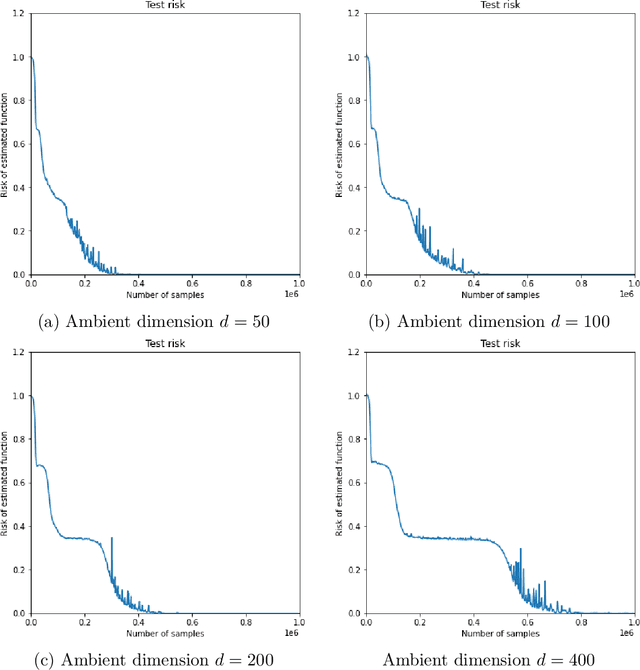
We investigate the time complexity of SGD learning on fully-connected neural networks with isotropic data. We put forward a complexity measure -- the leap -- which measures how "hierarchical" target functions are. For $d$-dimensional uniform Boolean or isotropic Gaussian data, our main conjecture states that the time complexity to learn a function $f$ with low-dimensional support is $\tilde\Theta (d^{\max(\mathrm{Leap}(f),2)})$. We prove a version of this conjecture for a class of functions on Gaussian isotropic data and 2-layer neural networks, under additional technical assumptions on how SGD is run. We show that the training sequentially learns the function support with a saddle-to-saddle dynamic. Our result departs from [Abbe et al. 2022] by going beyond leap 1 (merged-staircase functions), and by going beyond the mean-field and gradient flow approximations that prohibit the full complexity control obtained here. Finally, we note that this gives an SGD complexity for the full training trajectory that matches that of Correlational Statistical Query (CSQ) lower-bounds.