 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGD learning on neural networks: leap complexity and saddle-to-saddle dynamics
Paper and Code
Feb 21, 2023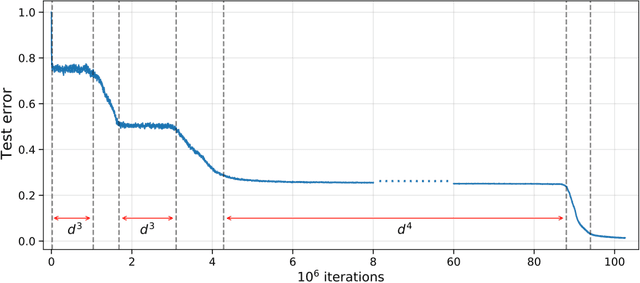
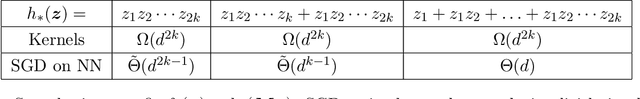
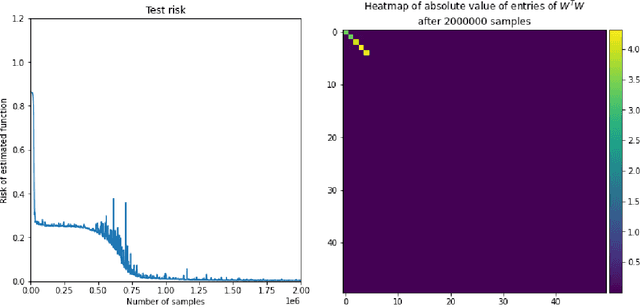
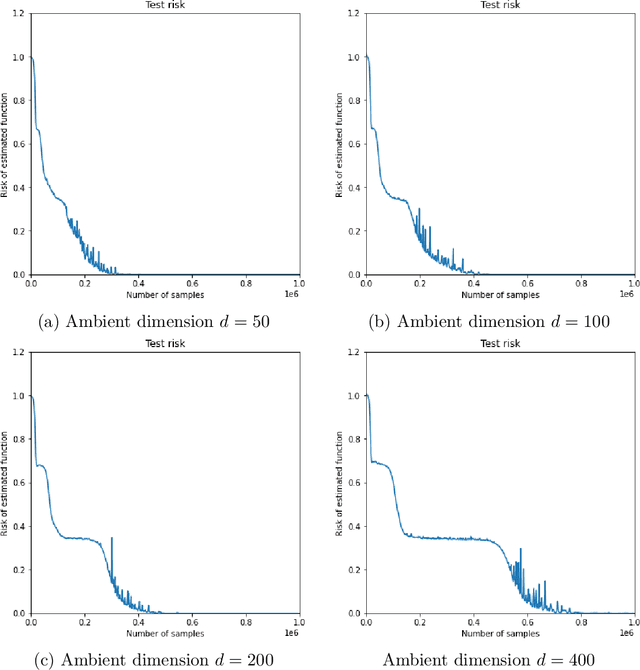
We investigate the time complexity of SGD learning on fully-connected neural networks with isotropic data. We put forward a complexity measure -- the leap -- which measures how "hierarchical" target functions are. For $d$-dimensional uniform Boolean or isotropic Gaussian data, our main conjecture states that the time complexity to learn a function $f$ with low-dimensional support is $\tilde\Theta (d^{\max(\mathrm{Leap}(f),2)})$. We prove a version of this conjecture for a class of functions on Gaussian isotropic data and 2-layer neural networks, under additional technical assumptions on how SGD is run. We show that the training sequentially learns the function support with a saddle-to-saddle dynamic. Our result departs from [Abbe et al. 2022] by going beyond leap 1 (merged-staircase functions), and by going beyond the mean-field and gradient flow approximations that prohibit the full complexity control obtained here. Finally, we note that this gives an SGD complexity for the full training trajectory that matches that of Correlational Statistical Query (CSQ) lower-bounds.