 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositive Distribution Shift as a Framework for Understanding Tractable Learning
Feb 09, 2026We study a setting where the goal is to learn a target function f(x) with respect to a target distribution D(x), but training is done on i.i.d. samples from a different training distribution D'(x), labeled by the true target f(x). Such a distribution shift (here in the form of covariate shift) is usually viewed negatively, as hurting or making learning harder, and the traditional distribution shift literature is mostly concerned with limiting or avoiding this negative effect. In contrast, we argue that with a well-chosen D'(x), the shift can be positive and make learning easier -- a perspective called Positive Distribution Shift (PDS). Such a perspective is central to contemporary machine learning, where much of the innovation is in finding good training distributions D'(x), rather than changing the training algorithm. We further argue that the benefit is often computational rather than statistical, and that PDS allows computationally hard problems to become tractable even using standard gradient-based training. We formalize different variants of PDS, show how certain hard classes are easily learnable under PDS, and make connections with membership query learning.
Learning single-index models via harmonic decomposition
Jun 11, 2025We study the problem of learning single-index models, where the label $y \in \mathbb{R}$ depends on the input $\boldsymbol{x} \in \mathbb{R}^d$ only through an unknown one-dimensional projection $\langle \boldsymbol{w}_*,\boldsymbol{x}\rangle$. Prior work has shown that under Gaussian inputs, the statistical and computational complexity of recovering $\boldsymbol{w}_*$ is governed by the Hermite expansion of the link function. In this paper, we propose a new perspective: we argue that "spherical harmonics" -- rather than "Hermite polynomials" -- provide the natural basis for this problem, as they capture its intrinsic "rotational symmetry". Building on this insight, we characterize the complexity of learning single-index models under arbitrary spherically symmetric input distributions. We introduce two families of estimators -- based on tensor unfolding and online SGD -- that respectively achieve either optimal sample complexity or optimal runtime, and argue that estimators achieving both may not exist in general. When specialized to Gaussian inputs, our theory not only recovers and clarifies existing results but also reveals new phenomena that had previously been overlooked.
An Optimized Franz-Parisi Criterion and its Equivalence with SQ Lower Bounds
Jun 06, 2025Bandeira et al. (2022) introduced the Franz-Parisi (FP) criterion for characterizing the computational hard phases in statistical detection problems. The FP criterion, based on an annealed version of the celebrated Franz-Parisi potential from statistical physics, was shown to be equivalent to low-degree polynomial (LDP) lower bounds for Gaussian additive models, thereby connecting two distinct approaches to understanding the computational hardness in statistical inference. In this paper, we propose a refined FP criterion that aims to better capture the geometric ``overlap" structure of statistical models. Our main result establishes that this optimized FP criterion is equivalent to Statistical Query (SQ) lower bounds -- another foundational framework in computational complexity of statistical inference. Crucially, this equivalence holds under a mild, verifiable assumption satisfied by a broad class of statistical models, including Gaussian additive models, planted sparse models, as well as non-Gaussian component analysis (NGCA), single-index (SI) models, and convex truncation detection settings. For instance, in the case of convex truncation tasks, the assumption is equivalent with the Gaussian correlation inequality (Royen, 2014) from convex geometry. In addition to the above, our equivalence not only unifies and simplifies the derivation of several known SQ lower bounds -- such as for the NGCA model (Diakonikolas et al., 2017) and the SI model (Damian et al., 2024) -- but also yields new SQ lower bounds of independent interest, including for the computational gaps in mixed sparse linear regression (Arpino et al., 2023) and convex truncation (De et al., 2023).
A Theory of Learning with Autoregressive Chain of Thought
Mar 11, 2025For a given base class of sequence-to-next-token generators, we consider learning prompt-to-answer mappings obtained by iterating a fixed, time-invariant generator for multiple steps, thus generating a chain-of-thought, and then taking the final token as the answer. We formalize the learning problems both when the chain-of-thought is observed and when training only on prompt-answer pairs, with the chain-of-thought latent. We analyze the sample and computational complexity both in terms of general properties of the base class (e.g. its VC dimension) and for specific base classes such as linear thresholds. We present a simple base class that allows for universal representability and computationally tractable chain-of-thought learning. Central to our development is that time invariance allows for sample complexity that is independent of the length of the chain-of-thought. Attention arises naturally in our construction.
On the Complexity of Learning Sparse Functions with Statistical and Gradient Queries
Jul 08, 2024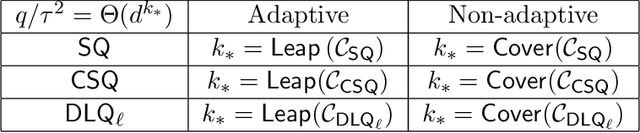
The goal of this paper is to investigate the complexity of gradient algorithms when learning sparse functions (juntas). We introduce a type of Statistical Queries ($\mathsf{SQ}$), which we call Differentiable Learning Queries ($\mathsf{DLQ}$), to model gradient queries on a specified loss with respect to an arbitrary model. We provide a tight characterization of the query complexity of $\mathsf{DLQ}$ for learning the support of a sparse function over generic product distributions. This complexity crucially depends on the loss function. For the squared loss, $\mathsf{DLQ}$ matches the complexity of Correlation Statistical Queries $(\mathsf{CSQ})$--potentially much worse than $\mathsf{SQ}$. But for other simple loss functions, including the $\ell_1$ loss, $\mathsf{DLQ}$ always achieves the same complexity as $\mathsf{SQ}$. We also provide evidence that $\mathsf{DLQ}$ can indeed capture learning with (stochastic) gradient descent by showing it correctly describes the complexity of learning with a two-layer neural network in the mean field regime and linear scaling.
Dimension-free deterministic equivalents for random feature regression
May 24, 2024



In this work we investigate the generalization performance of random feature ridge regression (RFRR). Our main contribution is a general deterministic equivalent for the test error of RFRR. Specifically, under a certain concentration property, we show that the test error is well approximated by a closed-form expression that only depends on the feature map eigenvalues. Notably, our approximation guarantee is non-asymptotic, multiplicative, and independent of the feature map dimension -- allowing for infinite-dimensional features. We expect this deterministic equivalent to hold broadly beyond our theoretical analysis, and we empirically validate its predictions on various real and synthetic datasets. As an application, we derive sharp excess error rates under standard power-law assumptions of the spectrum and target decay. In particular, we provide a tight result for the smallest number of features achieving optimal minimax error rate.
A non-asymptotic theory of Kernel Ridge Regression: deterministic equivalents, test error, and GCV estimator
Mar 13, 2024



We consider learning an unknown target function $f_*$ using kernel ridge regression (KRR) given i.i.d. data $(u_i,y_i)$, $i\leq n$, where $u_i \in U$ is a covariate vector and $y_i = f_* (u_i) +\varepsilon_i \in \mathbb{R}$. A recent string of work has empirically shown that the test error of KRR can be well approximated by a closed-form estimate derived from an `equivalent' sequence model that only depends on the spectrum of the kernel operator. However, a theoretical justification for this equivalence has so far relied either on restrictive assumptions -- such as subgaussian independent eigenfunctions -- , or asymptotic derivations for specific kernels in high dimensions. In this paper, we prove that this equivalence holds for a general class of problems satisfying some spectral and concentration properties on the kernel eigendecomposition. Specifically, we establish in this setting a non-asymptotic deterministic approximation for the test error of KRR -- with explicit non-asymptotic bounds -- that only depends on the eigenvalues and the target function alignment to the eigenvectors of the kernel. Our proofs rely on a careful derivation of deterministic equivalents for random matrix functionals in the dimension free regime pioneered by Cheng and Montanari (2022). We apply this setting to several classical examples and show an excellent agreement between theoretical predictions and numerical simulations. These results rely on having access to the eigendecomposition of the kernel operator. Alternatively, we prove that, under this same setting, the generalized cross-validation (GCV) estimator concentrates on the test error uniformly over a range of ridge regularization parameter that includes zero (the interpolating solution). As a consequence, the GCV estimator can be used to estimate from data the test error and optimal regularization parameter for KRR.
Asymptotics of Random Feature Regression Beyond the Linear Scaling Regime
Mar 13, 2024



Recent advances in machine learning have been achieved by using overparametrized models trained until near interpolation of the training data. It was shown, e.g., through the double descent phenomenon, that the number of parameters is a poor proxy for the model complexity and generalization capabilities. This leaves open the question of understanding the impact of parametrization on the performance of these models. How does model complexity and generalization depend on the number of parameters $p$? How should we choose $p$ relative to the sample size $n$ to achieve optimal test error? In this paper, we investigate the example of random feature ridge regression (RFRR). This model can be seen either as a finite-rank approximation to kernel ridge regression (KRR), or as a simplified model for neural networks trained in the so-called lazy regime. We consider covariates uniformly distributed on the $d$-dimensional sphere and compute sharp asymptotics for the RFRR test error in the high-dimensional polynomial scaling, where $p,n,d \to \infty$ while $p/ d^{\kappa_1}$ and $n / d^{\kappa_2}$ stay constant, for all $\kappa_1 , \kappa_2 \in \mathbb{R}_{>0}$. These asymptotics precisely characterize the impact of the number of random features and regularization parameter on the test performance. In particular, RFRR exhibits an intuitive trade-off between approximation and generalization power. For $n = o(p)$, the sample size $n$ is the bottleneck and RFRR achieves the same performance as KRR (which is equivalent to taking $p = \infty$). On the other hand, if $p = o(n)$, the number of random features $p$ is the limiting factor and RFRR test error matches the approximation error of the random feature model class (akin to taking $n = \infty$). Finally, a double descent appears at $n= p$, a phenomenon that was previously only characterized in the linear scaling $\kappa_1 = \kappa_2 = 1$.
Six Lectures on Linearized Neural Networks
Aug 25, 2023

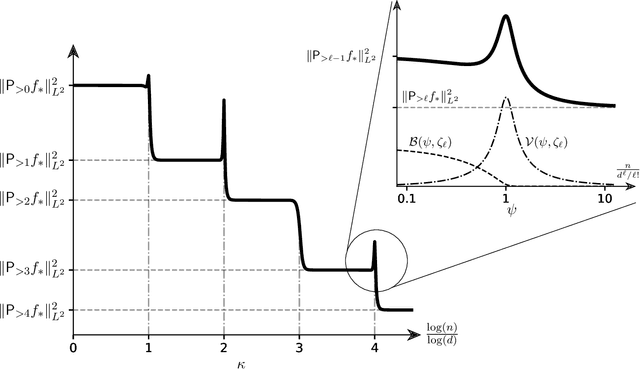

In these six lectures, we examine what can be learnt about the behavior of multi-layer neural networks from the analysis of linear models. We first recall the correspondence between neural networks and linear models via the so-called lazy regime. We then review four models for linearized neural networks: linear regression with concentrated features, kernel ridge regression, random feature model and neural tangent model. Finally, we highlight the limitations of the linear theory and discuss how other approaches can overcome them.
SGD learning on neural networks: leap complexity and saddle-to-saddle dynamics
Feb 21, 2023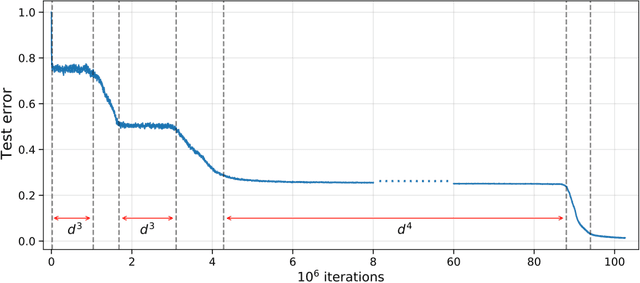
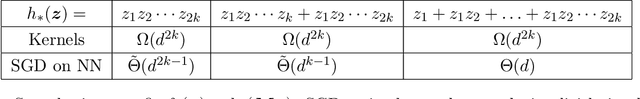
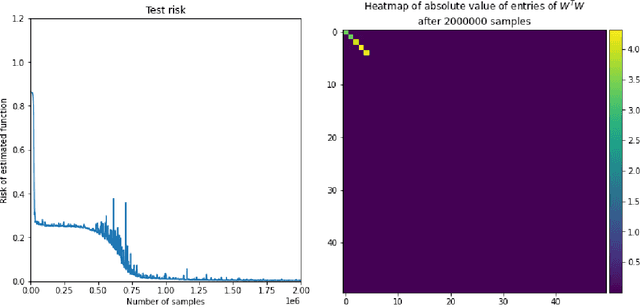
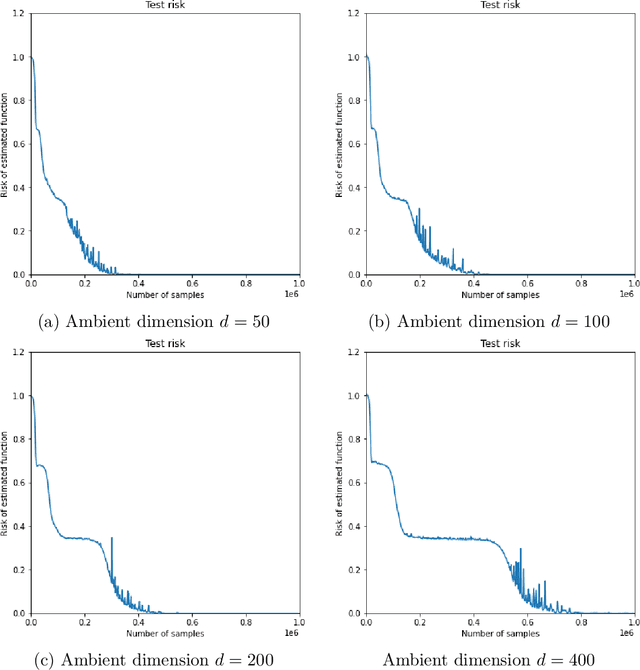
We investigate the time complexity of SGD learning on fully-connected neural networks with isotropic data. We put forward a complexity measure -- the leap -- which measures how "hierarchical" target functions are. For $d$-dimensional uniform Boolean or isotropic Gaussian data, our main conjecture states that the time complexity to learn a function $f$ with low-dimensional support is $\tilde\Theta (d^{\max(\mathrm{Leap}(f),2)})$. We prove a version of this conjecture for a class of functions on Gaussian isotropic data and 2-layer neural networks, under additional technical assumptions on how SGD is run. We show that the training sequentially learns the function support with a saddle-to-saddle dynamic. Our result departs from [Abbe et al. 2022] by going beyond leap 1 (merged-staircase functions), and by going beyond the mean-field and gradient flow approximations that prohibit the full complexity control obtained here. Finally, we note that this gives an SGD complexity for the full training trajectory that matches that of Correlational Statistical Query (CSQ) lower-bounds.