 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Complexity of Learning Sparse Functions with Statistical and Gradient Queries
Paper and Code
Jul 08, 2024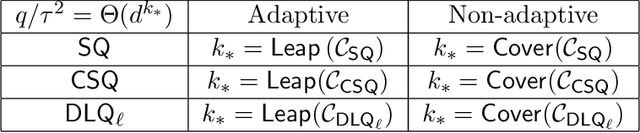
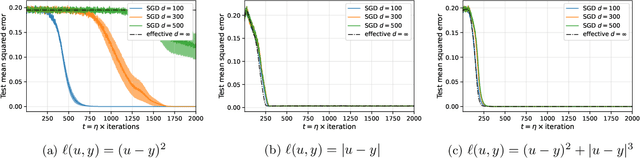
The goal of this paper is to investigate the complexity of gradient algorithms when learning sparse functions (juntas). We introduce a type of Statistical Queries ($\mathsf{SQ}$), which we call Differentiable Learning Queries ($\mathsf{DLQ}$), to model gradient queries on a specified loss with respect to an arbitrary model. We provide a tight characterization of the query complexity of $\mathsf{DLQ}$ for learning the support of a sparse function over generic product distributions. This complexity crucially depends on the loss function. For the squared loss, $\mathsf{DLQ}$ matches the complexity of Correlation Statistical Queries $(\mathsf{CSQ})$--potentially much worse than $\mathsf{SQ}$. But for other simple loss functions, including the $\ell_1$ loss, $\mathsf{DLQ}$ always achieves the same complexity as $\mathsf{SQ}$. We also provide evidence that $\mathsf{DLQ}$ can indeed capture learning with (stochastic) gradient descent by showing it correctly describes the complexity of learning with a two-layer neural network in the mean field regime and linear scaling.