 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Noise Sensitivity Exponent Controls Large Statistical-to-Computational Gaps in Single- and Multi-Index Models
Mar 18, 2026Understanding when learning is statistically possible yet computationally hard is a central challenge in high-dimensional statistics. In this work, we investigate this question in the context of single- and multi-index models, classes of functions widely studied as benchmarks to probe the ability of machine learning methods to discover features in high-dimensional data. Our main contribution is to show that a Noise Sensitivity Exponent (NSE) - a simple quantity determined by the activation function - governs the existence and magnitude of statistical-to-computational gaps within a broad regime of these models. We first establish that, in single-index models with large additive noise, the onset of a computational bottleneck is fully characterized by the NSE. We then demonstrate that the same exponent controls a statistical-computational gap in the specialization transition of large separable multi-index models, where individual components become learnable. Finally, in hierarchical multi-index models, we show that the NSE governs the optimal computational rate in which different directions are sequentially learned. Taken together, our results identify the NSE as a unifying property linking noise robustness, computational hardness, and feature specialization in high-dimensional learning.
Optimal scaling laws in learning hierarchical multi-index models
Feb 05, 2026In this work, we provide a sharp theory of scaling laws for two-layer neural networks trained on a class of hierarchical multi-index targets, in a genuinely representation-limited regime. We derive exact information-theoretic scaling laws for subspace recovery and prediction error, revealing how the hierarchical features of the target are sequentially learned through a cascade of phase transitions. We further show that these optimal rates are achieved by a simple, target-agnostic spectral estimator, which can be interpreted as the small learning-rate limit of gradient descent on the first-layer weights. Once an adapted representation is identified, the readout can be learned statistically optimally, using an efficient procedure. As a consequence, we provide a unified and rigorous explanation of scaling laws, plateau phenomena, and spectral structure in shallow neural networks trained on such hierarchical targets.
Optimal Spectral Transitions in High-Dimensional Multi-Index Models
Feb 04, 2025We consider the problem of how many samples from a Gaussian multi-index model are required to weakly reconstruct the relevant index subspace. Despite its increasing popularity as a testbed for investigating the computational complexity of neural networks, results beyond the single-index setting remain elusive. In this work, we introduce spectral algorithms based on the linearization of a message passing scheme tailored to this problem. Our main contribution is to show that the proposed methods achieve the optimal reconstruction threshold. Leveraging a high-dimensional characterization of the algorithms, we show that above the critical threshold the leading eigenvector correlates with the relevant index subspace, a phenomenon reminiscent of the Baik-Ben Arous-Peche (BBP) transition in spiked models arising in random matrix theory. Supported by numerical experiments and a rigorous theoretical framework, our work bridges critical gaps in the computational limits of weak learnability in multi-index model.
Dimension-free deterministic equivalents for random feature regression
May 24, 2024



In this work we investigate the generalization performance of random feature ridge regression (RFRR). Our main contribution is a general deterministic equivalent for the test error of RFRR. Specifically, under a certain concentration property, we show that the test error is well approximated by a closed-form expression that only depends on the feature map eigenvalues. Notably, our approximation guarantee is non-asymptotic, multiplicative, and independent of the feature map dimension -- allowing for infinite-dimensional features. We expect this deterministic equivalent to hold broadly beyond our theoretical analysis, and we empirically validate its predictions on various real and synthetic datasets. As an application, we derive sharp excess error rates under standard power-law assumptions of the spectrum and target decay. In particular, we provide a tight result for the smallest number of features achieving optimal minimax error rate.
Fundamental limits of weak learnability in high-dimensional multi-index models
May 24, 2024Multi-index models -- functions which only depend on the covariates through a non-linear transformation of their projection on a subspace -- are a useful benchmark for investigating feature learning with neural networks. This paper examines the theoretical boundaries of learnability in this hypothesis class, focusing particularly on the minimum sample complexity required for weakly recovering their low-dimensional structure with first-order iterative algorithms, in the high-dimensional regime where the number of samples is $n=\alpha d$ is proportional to the covariate dimension $d$. Our findings unfold in three parts: (i) first, we identify under which conditions a \textit{trivial subspace} can be learned with a single step of a first-order algorithm for any $\alpha\!>\!0$; (ii) second, in the case where the trivial subspace is empty, we provide necessary and sufficient conditions for the existence of an {\it easy subspace} consisting of directions that can be learned only above a certain sample complexity $\alpha\!>\!\alpha_c$. The critical threshold $\alpha_{c}$ marks the presence of a computational phase transition, in the sense that no efficient iterative algorithm can succeed for $\alpha\!<\!\alpha_c$. In a limited but interesting set of really hard directions -- akin to the parity problem -- $\alpha_c$ is found to diverge. Finally, (iii) we demonstrate that interactions between different directions can result in an intricate hierarchical learning phenomenon, where some directions can be learned sequentially when coupled to easier ones. Our analytical approach is built on the optimality of approximate message-passing algorithms among first-order iterative methods, delineating the fundamental learnability limit across a broad spectrum of algorithms, including neural networks trained with gradient descent.
High-dimensional robust regression under heavy-tailed data: Asymptotics and Universality
Sep 28, 2023
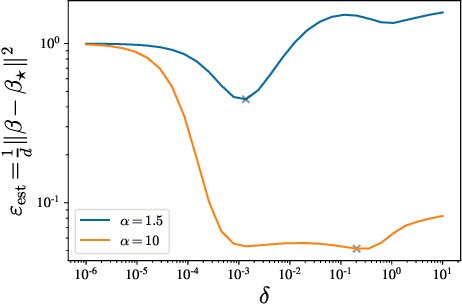
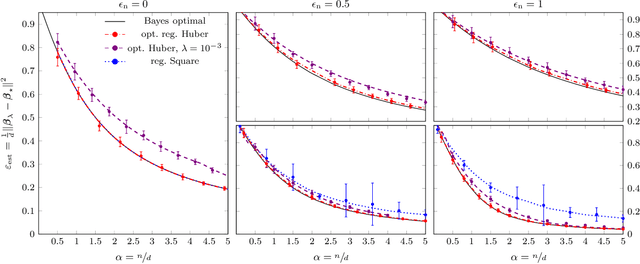
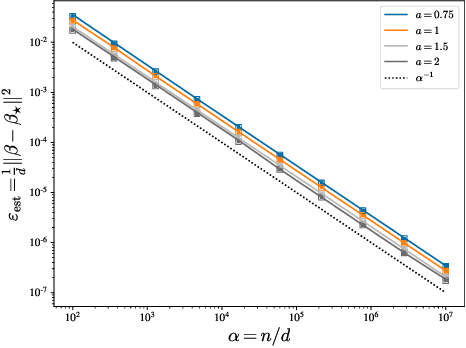
We investigate the high-dimensional properties of robust regression estimators in the presence of heavy-tailed contamination of both the covariates and response functions. In particular, we provide a sharp asymptotic characterisation of M-estimators trained on a family of elliptical covariate and noise data distributions including cases where second and higher moments do not exist. We show that, despite being consistent, the Huber loss with optimally tuned location parameter $\delta$ is suboptimal in the high-dimensional regime in the presence of heavy-tailed noise, highlighting the necessity of further regularisation to achieve optimal performance. This result also uncovers the existence of a curious transition in $\delta$ as a function of the sample complexity and contamination. Moreover, we derive the decay rates for the excess risk of ridge regression. We show that, while it is both optimal and universal for noise distributions with finite second moment, its decay rate can be considerably faster when the covariates' second moment does not exist. Finally, we show that our formulas readily generalise to a richer family of models and data distributions, such as generalised linear estimation with arbitrary convex regularisation trained on mixture models.