 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCA recovery thresholds in low-rank matrix inference with sparse noise
Nov 14, 2025We study the high-dimensional inference of a rank-one signal corrupted by sparse noise. The noise is modelled as the adjacency matrix of a weighted undirected graph with finite average connectivity in the large size limit. Using the replica method from statistical physics, we analytically compute the typical value of the top eigenvalue, the top eigenvector component density, and the overlap between the signal vector and the top eigenvector. The solution is given in terms of recursive distributional equations for auxiliary probability density functions which can be efficiently solved using a population dynamics algorithm. Specialising the noise matrix to Poissonian and Random Regular degree distributions, the critical signal strength is analytically identified at which a transition happens for the recovery of the signal via the top eigenvector, thus generalising the celebrated BBP transition to the sparse noise case. In the large-connectivity limit, known results for dense noise are recovered. Analytical results are in agreement with numerical diagonalisation of large matrices.
High-dimensional robust regression under heavy-tailed data: Asymptotics and Universality
Sep 28, 2023
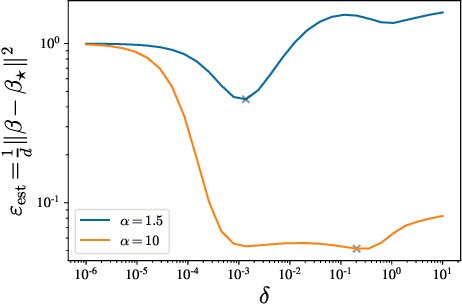
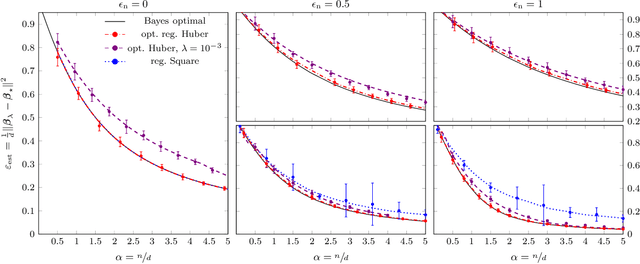
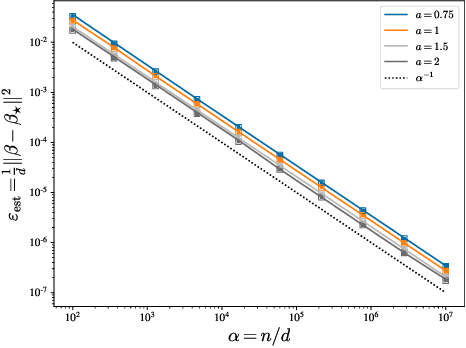
We investigate the high-dimensional properties of robust regression estimators in the presence of heavy-tailed contamination of both the covariates and response functions. In particular, we provide a sharp asymptotic characterisation of M-estimators trained on a family of elliptical covariate and noise data distributions including cases where second and higher moments do not exist. We show that, despite being consistent, the Huber loss with optimally tuned location parameter $\delta$ is suboptimal in the high-dimensional regime in the presence of heavy-tailed noise, highlighting the necessity of further regularisation to achieve optimal performance. This result also uncovers the existence of a curious transition in $\delta$ as a function of the sample complexity and contamination. Moreover, we derive the decay rates for the excess risk of ridge regression. We show that, while it is both optimal and universal for noise distributions with finite second moment, its decay rate can be considerably faster when the covariates' second moment does not exist. Finally, we show that our formulas readily generalise to a richer family of models and data distributions, such as generalised linear estimation with arbitrary convex regularisation trained on mixture models.
Classification of Superstatistical Features in High Dimensions
Apr 06, 2023We characterise the learning of a mixture of two clouds of data points with generic centroids via empirical risk minimisation in the high dimensional regime, under the assumptions of generic convex loss and convex regularisation. Each cloud of data points is obtained by sampling from a possibly uncountable superposition of Gaussian distributions, whose variance has a generic probability density $\varrho$. Our analysis covers therefore a large family of data distributions, including the case of power-law-tailed distributions with no covariance. We study the generalisation performance of the obtained estimator, we analyse the role of regularisation, and the dependence of the separability transition on the distribution scale parameters.
Fluctuations, Bias, Variance & Ensemble of Learners: Exact Asymptotics for Convex Losses in High-Dimension
Jan 31, 2022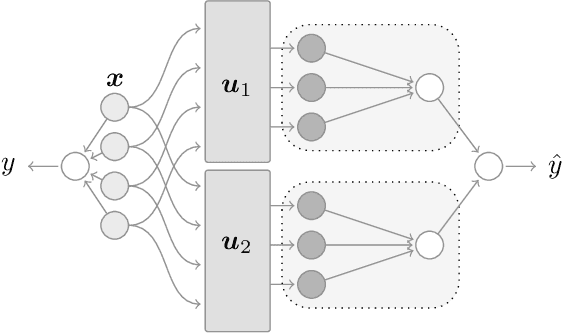
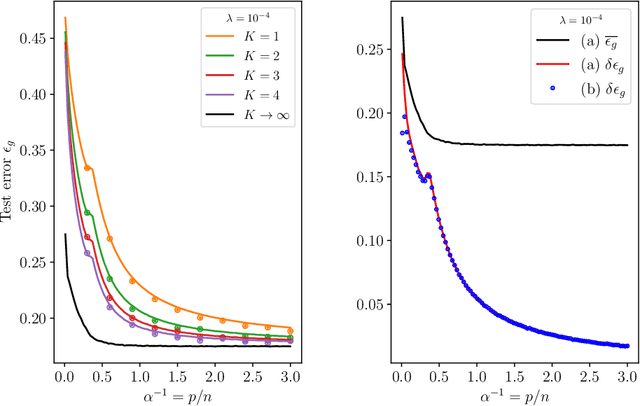
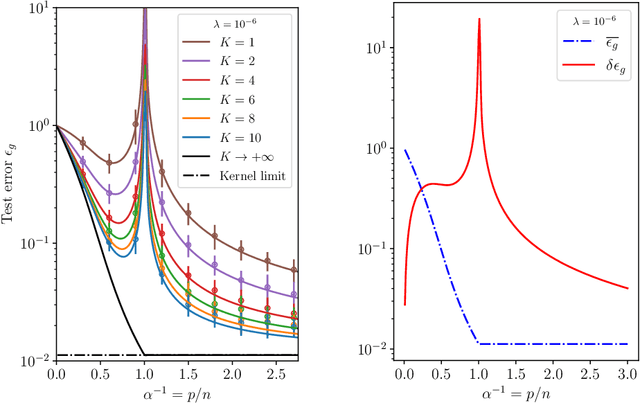
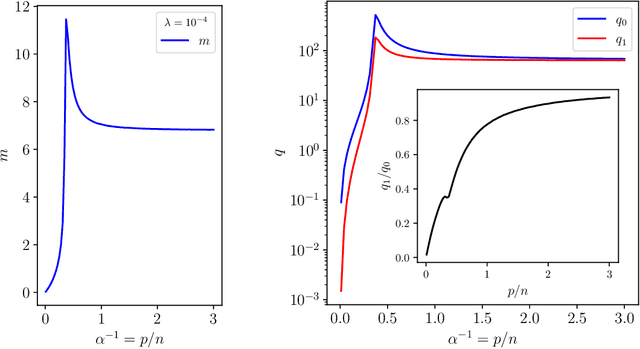
From the sampling of data to the initialisation of parameters, randomness is ubiquitous in modern Machine Learning practice. Understanding the statistical fluctuations engendered by the different sources of randomness in prediction is therefore key to understanding robust generalisation. In this manuscript we develop a quantitative and rigorous theory for the study of fluctuations in an ensemble of generalised linear models trained on different, but correlated, features in high-dimensions. In particular, we provide a complete description of the asymptotic joint distribution of the empirical risk minimiser for generic convex loss and regularisation in the high-dimensional limit. Our result encompasses a rich set of classification and regression tasks, such as the lazy regime of overparametrised neural networks, or equivalently the random features approximation of kernels. While allowing to study directly the mitigating effect of ensembling (or bagging) on the bias-variance decomposition of the test error, our analysis also helps disentangle the contribution of statistical fluctuations, and the singular role played by the interpolation threshold that are at the roots of the "double-descent" phenomenon.
Learning Gaussian Mixtures with Generalised Linear Models: Precise Asymptotics in High-dimensions
Jun 07, 2021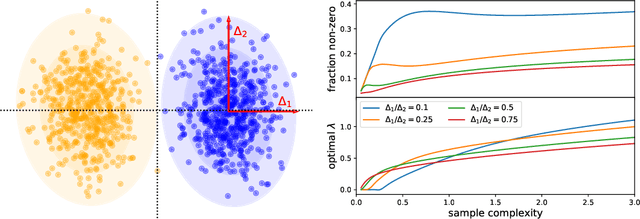
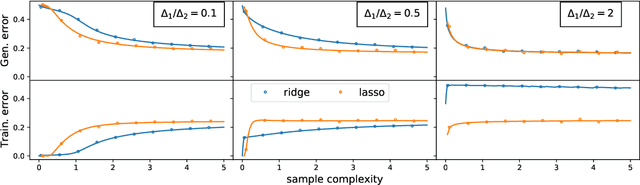
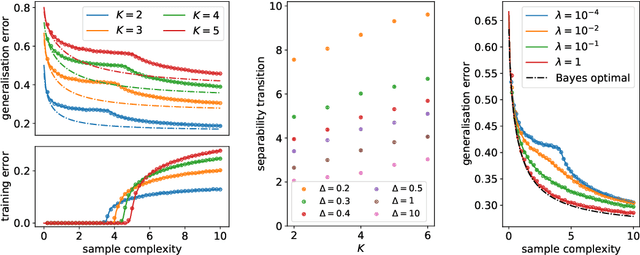
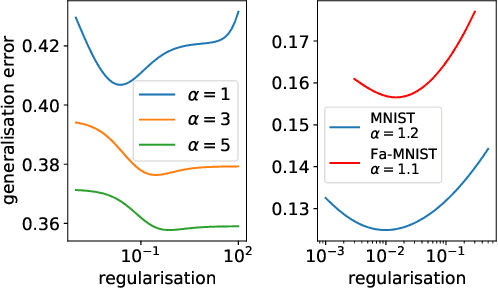
Generalised linear models for multi-class classification problems are one of the fundamental building blocks of modern machine learning tasks. In this manuscript, we characterise the learning of a mixture of $K$ Gaussians with generic means and covariances via empirical risk minimisation (ERM) with any convex loss and regularisation. In particular, we prove exact asymptotics characterising the ERM estimator in high-dimensions, extending several previous results about Gaussian mixture classification in the literature. We exemplify our result in two tasks of interest in statistical learning: a) classification for a mixture with sparse means, where we study the efficiency of $\ell_1$ penalty with respect to $\ell_2$; b) max-margin multi-class classification, where we characterise the phase transition on the existence of the multi-class logistic maximum likelihood estimator for $K>2$. Finally, we discuss how our theory can be applied beyond the scope of synthetic data, showing that in different cases Gaussian mixtures capture closely the learning curve of classification tasks in real data sets.