 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Semantic Alphabet Size for LLM Uncertainty Quantification
Sep 17, 2025Many black-box techniques for quantifying the uncertainty of large language models (LLMs) rely on repeated LLM sampling, which can be computationally expensive. Therefore, practical applicability demands reliable estimation from few samples. Semantic entropy (SE) is a popular sample-based uncertainty estimator with a discrete formulation attractive for the black-box setting. Recent extensions of semantic entropy exhibit improved LLM hallucination detection, but do so with less interpretable methods that admit additional hyperparameters. For this reason, we revisit the canonical discrete semantic entropy estimator, finding that it underestimates the "true" semantic entropy, as expected from theory. We propose a modified semantic alphabet size estimator, and illustrate that using it to adjust discrete semantic entropy for sample coverage results in more accurate semantic entropy estimation in our setting of interest. Furthermore, our proposed alphabet size estimator flags incorrect LLM responses as well or better than recent top-performing approaches, with the added benefit of remaining highly interpretable.
Demystifying optimized prompts in language models
May 04, 2025Modern language models (LMs) are not robust to out-of-distribution inputs. Machine generated (``optimized'') prompts can be used to modulate LM outputs and induce specific behaviors while appearing completely uninterpretable. In this work, we investigate the composition of optimized prompts, as well as the mechanisms by which LMs parse and build predictions from optimized prompts. We find that optimized prompts primarily consist of punctuation and noun tokens which are more rare in the training data. Internally, optimized prompts are clearly distinguishable from natural language counterparts based on sparse subsets of the model's activations. Across various families of instruction-tuned models, optimized prompts follow a similar path in how their representations form through the network.
Improving Content Recommendation: Knowledge Graph-Based Semantic Contrastive Learning for Diversity and Cold-Start Users
Mar 27, 2024Addressing the challenges related to data sparsity, cold-start problems, and diversity in recommendation systems is both crucial and demanding. Many current solutions leverage knowledge graphs to tackle these issues by combining both item-based and user-item collaborative signals. A common trend in these approaches focuses on improving ranking performance at the cost of escalating model complexity, reducing diversity, and complicating the task. It is essential to provide recommendations that are both personalized and diverse, rather than solely relying on achieving high rank-based performance, such as Click-through Rate, Recall, etc. In this paper, we propose a hybrid multi-task learning approach, training on user-item and item-item interactions. We apply item-based contrastive learning on descriptive text, sampling positive and negative pairs based on item metadata. Our approach allows the model to better understand the relationships between entities within the knowledge graph by utilizing semantic information from text. It leads to more accurate, relevant, and diverse user recommendations and a benefit that extends even to cold-start users who have few interactions with items. We perform extensive experiments on two widely used datasets to validate the effectiveness of our approach. Our findings demonstrate that jointly training user-item interactions and item-based signals using synopsis text is highly effective. Furthermore, our results provide evidence that item-based contrastive learning enhances the quality of entity embeddings, as indicated by metrics such as uniformity and alignment.
PROPANE: Prompt design as an inverse problem
Nov 13, 2023
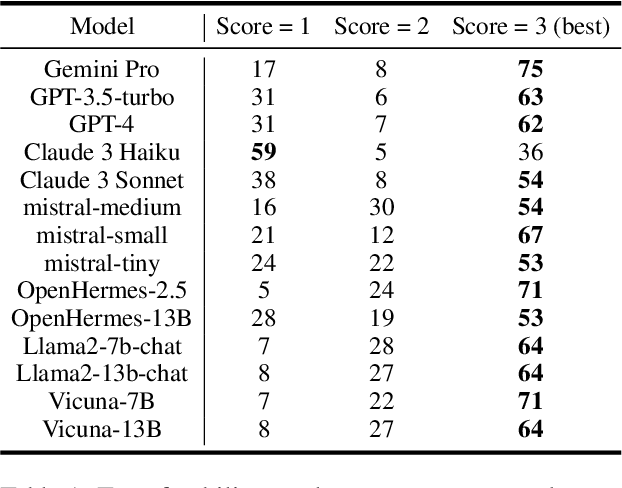
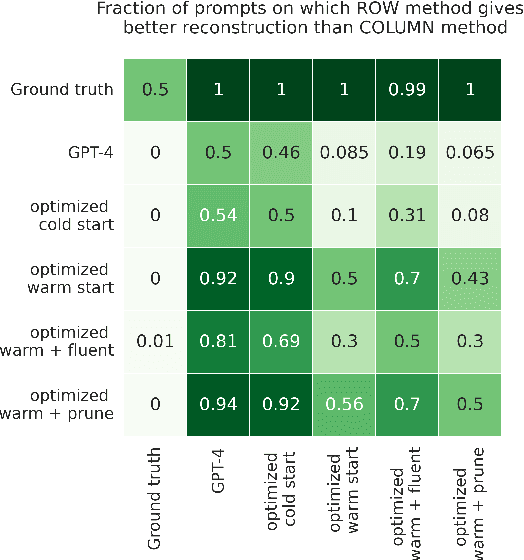
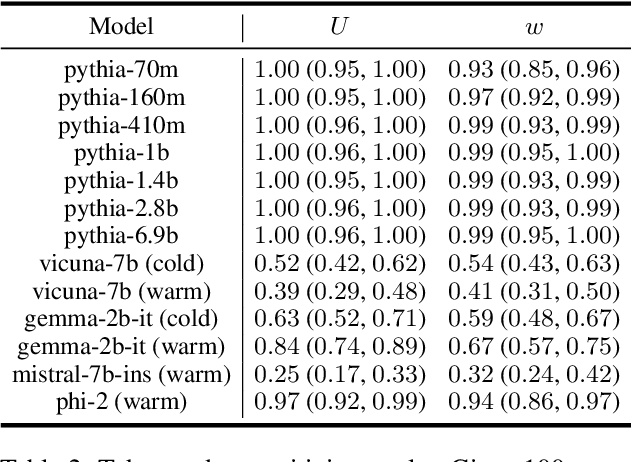
Carefully-designed prompts are key to inducing desired behavior in Large Language Models (LLMs). As a result, great effort has been dedicated to engineering prompts that guide LLMs toward particular behaviors. In this work, we propose an automatic prompt optimization framework, PROPANE, which aims to find a prompt that induces semantically similar outputs to a fixed set of examples without user intervention. We further demonstrate that PROPANE can be used to (a) improve existing prompts, and (b) discover semantically obfuscated prompts that transfer between models.