 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Content Recommendation: Knowledge Graph-Based Semantic Contrastive Learning for Diversity and Cold-Start Users
Mar 27, 2024Addressing the challenges related to data sparsity, cold-start problems, and diversity in recommendation systems is both crucial and demanding. Many current solutions leverage knowledge graphs to tackle these issues by combining both item-based and user-item collaborative signals. A common trend in these approaches focuses on improving ranking performance at the cost of escalating model complexity, reducing diversity, and complicating the task. It is essential to provide recommendations that are both personalized and diverse, rather than solely relying on achieving high rank-based performance, such as Click-through Rate, Recall, etc. In this paper, we propose a hybrid multi-task learning approach, training on user-item and item-item interactions. We apply item-based contrastive learning on descriptive text, sampling positive and negative pairs based on item metadata. Our approach allows the model to better understand the relationships between entities within the knowledge graph by utilizing semantic information from text. It leads to more accurate, relevant, and diverse user recommendations and a benefit that extends even to cold-start users who have few interactions with items. We perform extensive experiments on two widely used datasets to validate the effectiveness of our approach. Our findings demonstrate that jointly training user-item interactions and item-based signals using synopsis text is highly effective. Furthermore, our results provide evidence that item-based contrastive learning enhances the quality of entity embeddings, as indicated by metrics such as uniformity and alignment.
Sparse multiresolution representations with adaptive kernels
May 07, 2019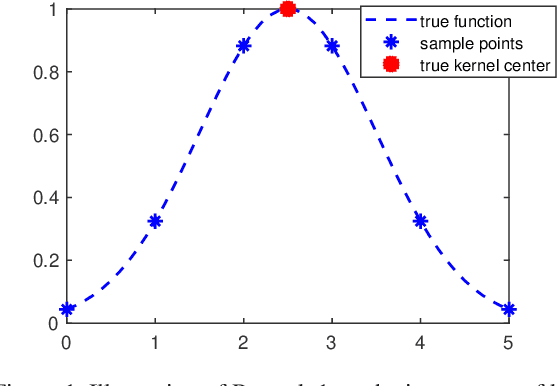
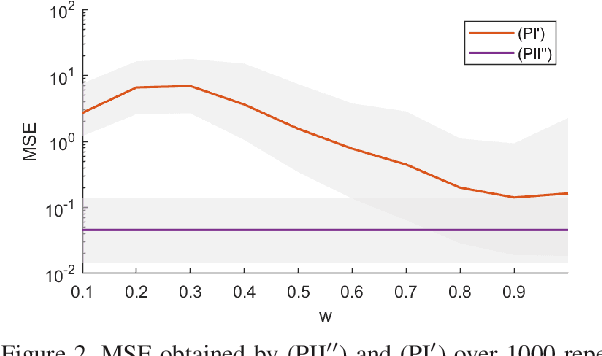
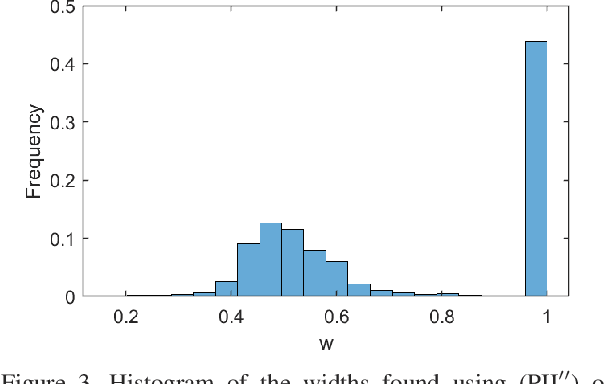
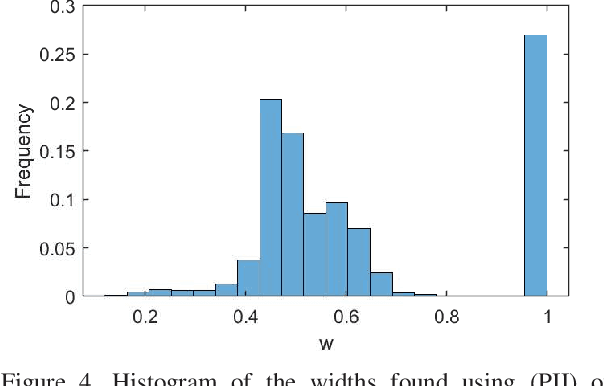
Reproducing kernel Hilbert spaces (RKHSs) are key elements of many non-parametric tools successfully used in signal processing, statistics, and machine learning. In this work, we aim to address three issues of the classical RKHS based techniques. First, they require the RKHS to be known a priori, which is unrealistic in many applications. Furthermore, the choice of RKHS affects the shape and smoothness of the solution, thus impacting its performance. Second, RKHSs are ill-equipped to deal with heterogeneous degrees of smoothness, i.e., with functions that are smooth in some parts of their domain but vary rapidly in others. Finally, the computational complexity of evaluating the solution of these methods grows with the number of data points, rendering these techniques infeasible for many applications. Though kernel learning, local kernel adaptation, and sparsity have been used to address these issues, many of these approaches are computationally intensive or forgo optimality guarantees. We tackle these problems by leveraging a novel integral representation of functions in RKHSs that allows for arbitrary centers and different kernels at each center. To address the complexity issues, we then write the function estimation problem as a sparse functional program that explicitly minimizes the support of the representation leading to low complexity solutions. Despite their non-convexity and infinite dimensionality, we show these problems can be solved exactly and efficiently by leveraging duality, and we illustrate this new approach in simulated and real data.