 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing JEPAs with Spatial Conditioning: Robust and Efficient Representation Learning
Paper and Code
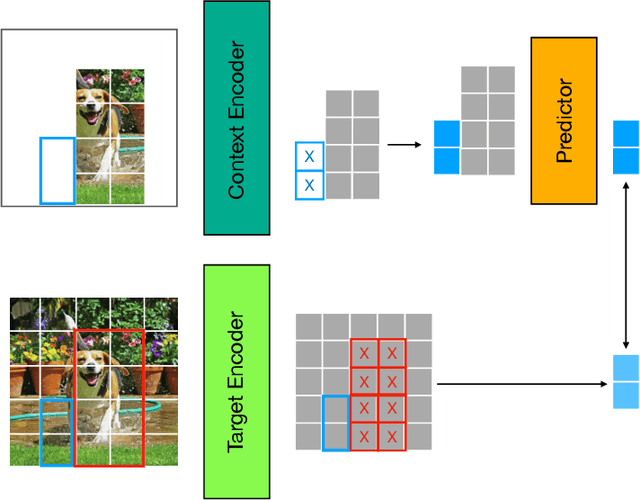
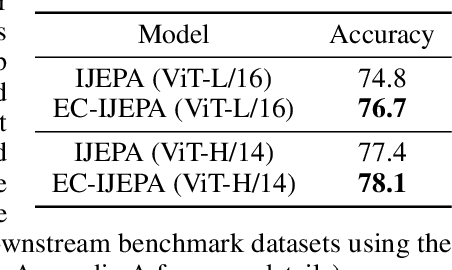
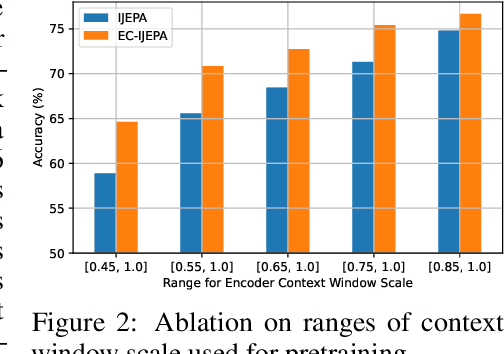
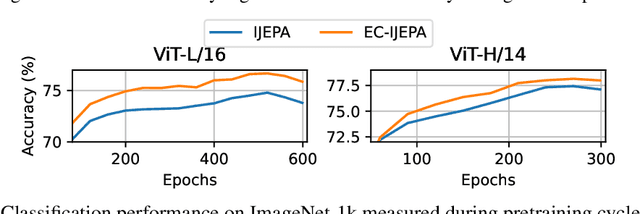
Image-based Joint-Embedding Predictive Architecture (IJEPA) offers an attractive alternative to Masked Autoencoder (MAE) for representation learning using the Masked Image Modeling framework. IJEPA drives representations to capture useful semantic information by predicting in latent rather than input space. However, IJEPA relies on carefully designed context and target windows to avoid representational collapse. The encoder modules in IJEPA cannot adaptively modulate the type of predicted and/or target features based on the feasibility of the masked prediction task as they are not given sufficient information of both context and targets. Based on the intuition that in natural images, information has a strong spatial bias with spatially local regions being highly predictive of one another compared to distant ones. We condition the target encoder and context encoder modules in IJEPA with positions of context and target windows respectively. Our "conditional" encoders show performance gains on several image classification benchmark datasets, improved robustness to context window size and sample-efficiency during pretraining.