 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSliced Wasserstein Discrepancy for Unsupervised Domain Adaptation
Mar 10, 2019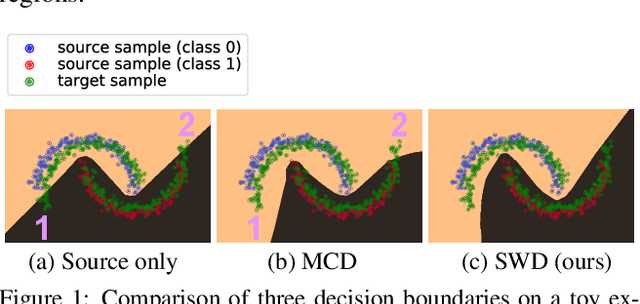
In this work, we connect two distinct concepts for unsupervised domain adaptation: feature distribution alignment between domains by utilizing the task-specific decision boundary and the Wasserstein metric. Our proposed sliced Wasserstein discrepancy (SWD) is designed to capture the natural notion of dissimilarity between the outputs of task-specific classifiers. It provides a geometrically meaningful guidance to detect target samples that are far from the support of the source and enables efficient distribution alignment in an end-to-end trainable fashion. In the experiments, we validate the effectiveness and genericness of our method on digit and sign recognition, image classification, semantic segmentation, and object detection.
Learning to Inpaint for Image Compression
Nov 10, 2017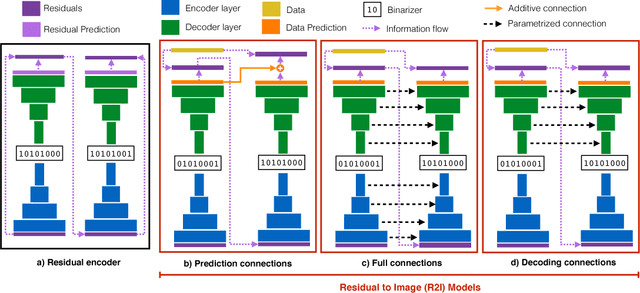

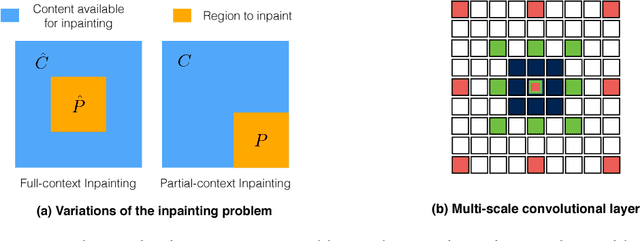

We study the design of deep architectures for lossy image compression. We present two architectural recipes in the context of multi-stage progressive encoders and empirically demonstrate their importance on compression performance. Specifically, we show that: (a) predicting the original image data from residuals in a multi-stage progressive architecture facilitates learning and leads to improved performance at approximating the original content and (b) learning to inpaint (from neighboring image pixels) before performing compression reduces the amount of information that must be stored to achieve a high-quality approximation. Incorporating these design choices in a baseline progressive encoder yields an average reduction of over $60\%$ in file size with similar quality compared to the original residual encoder.
Network of Experts for Large-Scale Image Categorization
Apr 19, 2017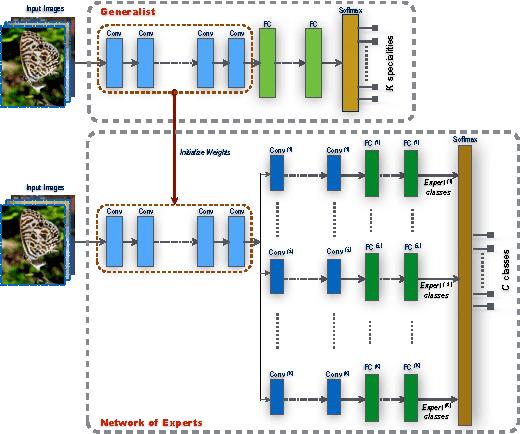


We present a tree-structured network architecture for large scale image classification. The trunk of the network contains convolutional layers optimized over all classes. At a given depth, the trunk splits into separate branches, each dedicated to discriminate a different subset of classes. Each branch acts as an expert classifying a set of categories that are difficult to tell apart, while the trunk provides common knowledge to all experts in the form of shared features. The training of our "network of experts" is completely end-to-end: the partition of categories into disjoint subsets is learned simultaneously with the parameters of the network trunk and the experts are trained jointly by minimizing a single learning objective over all classes. The proposed structure can be built from any existing convolutional neural network (CNN). We demonstrate its generality by adapting 4 popular CNNs for image categorization into the form of networks of experts. Our experiments on CIFAR100 and ImageNet show that in every case our method yields a substantial improvement in accuracy over the base CNN, and gives the best result achieved so far on CIFAR100. Finally, the improvement in accuracy comes at little additional cost: compared to the base network, the training time is only moderately increased and the number of parameters is comparable or in some cases even lower.
Multiple Hypothesis Colorization
Mar 01, 2017



In this work we focus on the problem of colorization for image compression. Since color information occupies a large proportion of the total storage size of an image, a method that can predict accurate color from its grayscale version can produce dramatic reduction in image file size. But colorization for compression poses several challenges. First, while colorization for artistic purposes simply involves predicting plausible chroma, colorization for compression requires generating output colors that are as close as possible to the ground truth. Second, many objects in the real world exhibit multiple possible colors. Thus, to disambiguate the colorization problem some additional information must be stored to reproduce the true colors with good accuracy. To account for the multimodal color distribution of objects we propose a deep tree-structured network that generates multiple color hypotheses for every pixel from a grayscale picture (as opposed to a single color produced by most prior colorization approaches). We show how to leverage the multimodal output of our model to reproduce with high fidelity the true colors of an image by storing very little additional information. In the experiments we show that our proposed method outperforms traditional JPEG color coding by a large margin, producing colors that are nearly indistinguishable from the ground truth at the storage cost of just a few hundred bytes for high-resolution pictures!
Coupled Depth Learning
Feb 09, 2016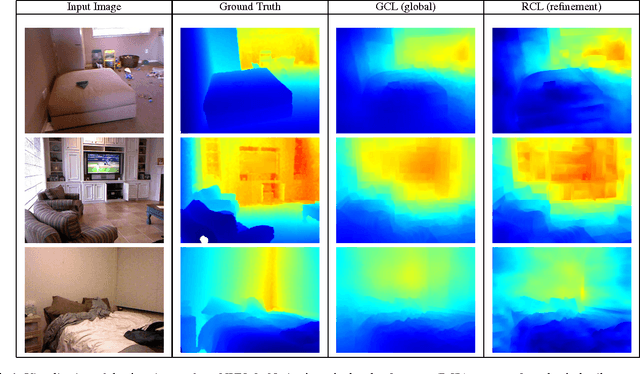


In this paper we propose a method for estimating depth from a single image using a coarse to fine approach. We argue that modeling the fine depth details is easier after a coarse depth map has been computed. We express a global (coarse) depth map of an image as a linear combination of a depth basis learned from training examples. The depth basis captures spatial and statistical regularities and reduces the problem of global depth estimation to the task of predicting the input-specific coefficients in the linear combination. This is formulated as a regression problem from a holistic representation of the image. Crucially, the depth basis and the regression function are {\bf coupled} and jointly optimized by our learning scheme. We demonstrate that this results in a significant improvement in accuracy compared to direct regression of depth pixel values or approaches learning the depth basis disjointly from the regression function. The global depth estimate is then used as a guidance by a local refinement method that introduces depth details that were not captured at the global level. Experiments on the NYUv2 and KITTI datasets show that our method outperforms the existing state-of-the-art at a considerably lower computational cost for both training and testing.