 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBranchConnect: Large-Scale Visual Recognition with Learned Branch Connections
Jul 29, 2018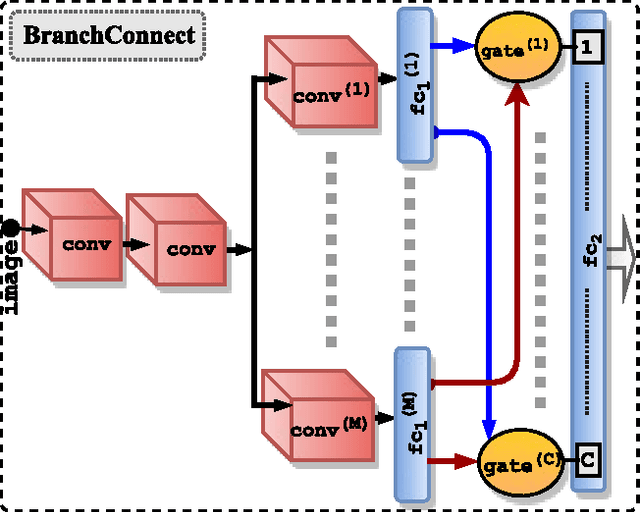
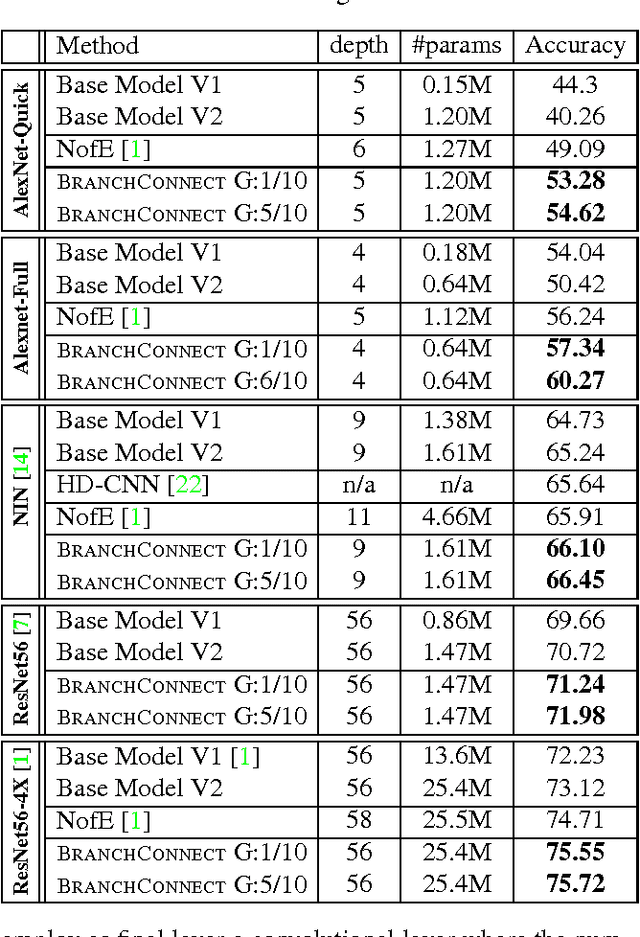
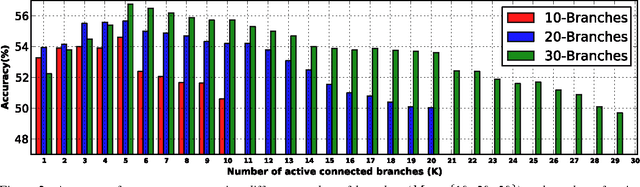

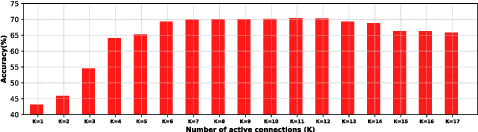
We introduce an architecture for large-scale image categorization that enables the end-to-end learning of separate visual features for the different classes to distinguish. The proposed model consists of a deep CNN shaped like a tree. The stem of the tree includes a sequence of convolutional layers common to all classes. The stem then splits into multiple branches implementing parallel feature extractors, which are ultimately connected to the final classification layer via learned gated connections. These learned gates determine for each individual class the subset of features to use. Such a scheme naturally encourages the learning of a heterogeneous set of specialized features through the separate branches and it allows each class to use the subset of features that are optimal for its recognition. We show the generality of our proposed method by reshaping several popular CNNs from the literature into our proposed architecture. Our experiments on the CIFAR100, CIFAR10, and Synth datasets show that in each case our resulting model yields a substantial improvement in accuracy over the original CNN. Our empirical analysis also suggests that our scheme acts as a form of beneficial regularization improving generalization performance.
* WACV 2018
MaskConnect: Connectivity Learning by Gradient Descent
Jul 28, 2018

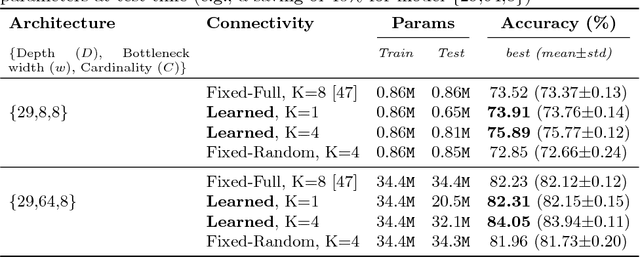
Although deep networks have recently emerged as the model of choice for many computer vision problems, in order to yield good results they often require time-consuming architecture search. To combat the complexity of design choices, prior work has adopted the principle of modularized design which consists in defining the network in terms of a composition of topologically identical or similar building blocks (a.k.a. modules). This reduces architecture search to the problem of determining the number of modules to compose and how to connect such modules. Again, for reasons of design complexity and training cost, previous approaches have relied on simple rules of connectivity, e.g., connecting each module to only the immediately preceding module or perhaps to all of the previous ones. Such simple connectivity rules are unlikely to yield the optimal architecture for the given problem. In this work we remove these predefined choices and propose an algorithm to learn the connections between modules in the network. Instead of being chosen a priori by the human designer, the connectivity is learned simultaneously with the weights of the network by optimizing the loss function of the end task using a modified version of gradient descent. We demonstrate our connectivity learning method on the problem of multi-class image classification using two popular architectures: ResNet and ResNeXt. Experiments on four different datasets show that connectivity learning using our approach yields consistently higher accuracy compared to relying on traditional predefined rules of connectivity. Furthermore, in certain settings it leads to significant savings in number of parameters.
Connectivity Learning in Multi-Branch Networks
Dec 07, 2017
While much of the work in the design of convolutional networks over the last five years has revolved around the empirical investigation of the importance of depth, filter sizes, and number of feature channels, recent studies have shown that branching, i.e., splitting the computation along parallel but distinct threads and then aggregating their outputs, represents a new promising dimension for significant improvements in performance. To combat the complexity of design choices in multi-branch architectures, prior work has adopted simple strategies, such as a fixed branching factor, the same input being fed to all parallel branches, and an additive combination of the outputs produced by all branches at aggregation points. In this work we remove these predefined choices and propose an algorithm to learn the connections between branches in the network. Instead of being chosen a priori by the human designer, the multi-branch connectivity is learned simultaneously with the weights of the network by optimizing a single loss function defined with respect to the end task. We demonstrate our approach on the problem of multi-class image classification using three different datasets where it yields consistently higher accuracy compared to the state-of-the-art "ResNeXt" multi-branch network given the same learning capacity.
Weighted Transformer Network for Machine Translation
Nov 06, 2017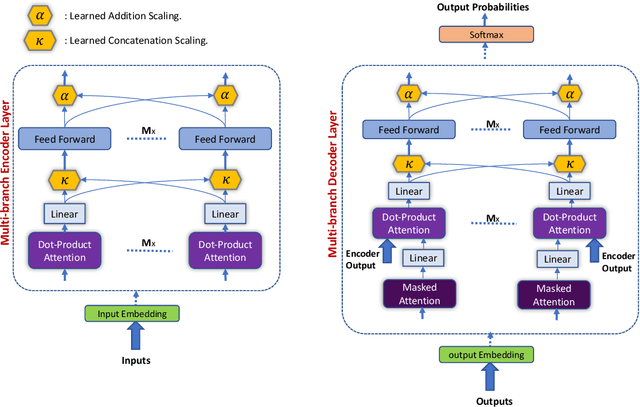
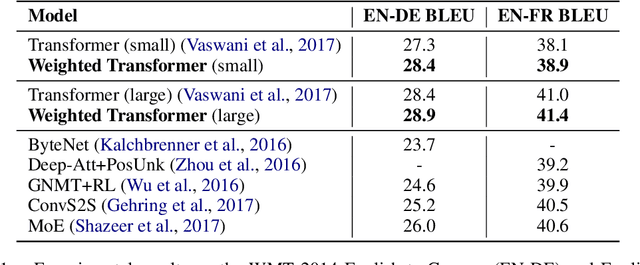
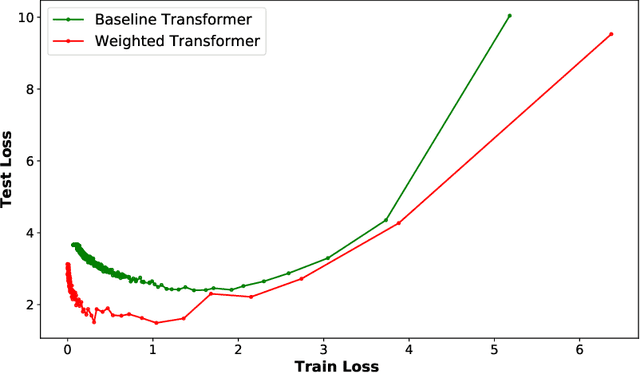
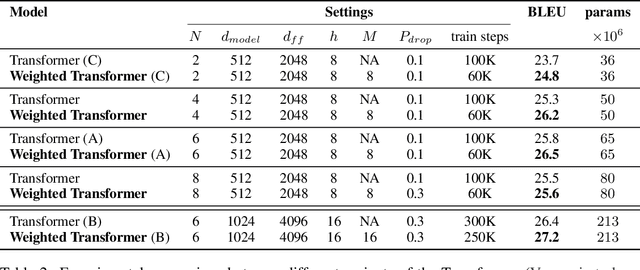
State-of-the-art results on neural machine translation often use attentional sequence-to-sequence models with some form of convolution or recursion. Vaswani et al. (2017) propose a new architecture that avoids recurrence and convolution completely. Instead, it uses only self-attention and feed-forward layers. While the proposed architecture achieves state-of-the-art results on several machine translation tasks, it requires a large number of parameters and training iterations to converge. We propose Weighted Transformer, a Transformer with modified attention layers, that not only outperforms the baseline network in BLEU score but also converges 15-40% faster. Specifically, we replace the multi-head attention by multiple self-attention branches that the model learns to combine during the training process. Our model improves the state-of-the-art performance by 0.5 BLEU points on the WMT 2014 English-to-German translation task and by 0.4 on the English-to-French translation task.
Network of Experts for Large-Scale Image Categorization
Apr 19, 2017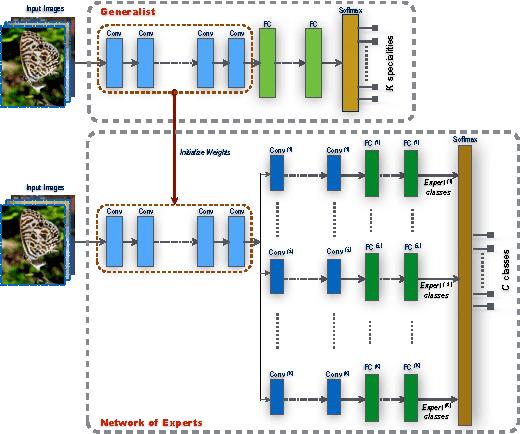


We present a tree-structured network architecture for large scale image classification. The trunk of the network contains convolutional layers optimized over all classes. At a given depth, the trunk splits into separate branches, each dedicated to discriminate a different subset of classes. Each branch acts as an expert classifying a set of categories that are difficult to tell apart, while the trunk provides common knowledge to all experts in the form of shared features. The training of our "network of experts" is completely end-to-end: the partition of categories into disjoint subsets is learned simultaneously with the parameters of the network trunk and the experts are trained jointly by minimizing a single learning objective over all classes. The proposed structure can be built from any existing convolutional neural network (CNN). We demonstrate its generality by adapting 4 popular CNNs for image categorization into the form of networks of experts. Our experiments on CIFAR100 and ImageNet show that in every case our method yields a substantial improvement in accuracy over the base CNN, and gives the best result achieved so far on CIFAR100. Finally, the improvement in accuracy comes at little additional cost: compared to the base network, the training time is only moderately increased and the number of parameters is comparable or in some cases even lower.