 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrism: Semi-Supervised Multi-View Stereo with Monocular Structure Priors
Dec 08, 2024



The promise of unsupervised multi-view-stereo (MVS) is to leverage large unlabeled datasets, yet current methods underperform when training on difficult data, such as handheld smartphone videos of indoor scenes. Meanwhile, high-quality synthetic datasets are available but MVS networks trained on these datasets fail to generalize to real-world examples. To bridge this gap, we propose a semi-supervised learning framework that allows us to train on real and rendered images jointly, capturing structural priors from synthetic data while ensuring parity with the real-world domain. Central to our framework is a novel set of losses that leverages powerful existing monocular relative-depth estimators trained on the synthetic dataset, transferring the rich structure of this relative depth to the MVS predictions on unlabeled data. Inspired by perceptual image metrics, we compare the MVS and monocular predictions via a deep feature loss and a multi-scale statistical loss. Our full framework, which we call Prism, achieves large quantitative and qualitative improvements over current unsupervised and synthetic-supervised MVS networks. This is a best-case-scenario result, opening the door to using both unlabeled smartphone videos and photorealistic synthetic datasets for training MVS networks.
Multimodal 3D Fusion and In-Situ Learning for Spatially Aware AI
Oct 06, 2024
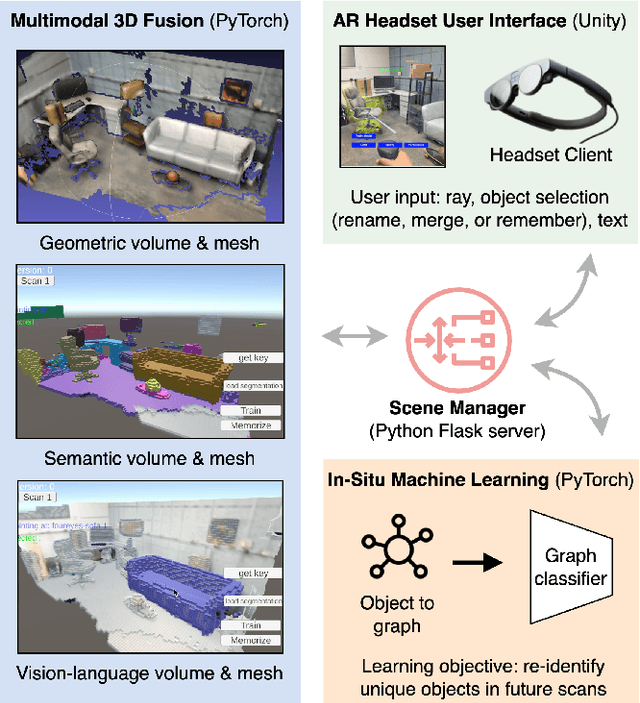

Seamless integration of virtual and physical worlds in augmented reality benefits from the system semantically "understanding" the physical environment. AR research has long focused on the potential of context awareness, demonstrating novel capabilities that leverage the semantics in the 3D environment for various object-level interactions. Meanwhile, the computer vision community has made leaps in neural vision-language understanding to enhance environment perception for autonomous tasks. In this work, we introduce a multimodal 3D object representation that unifies both semantic and linguistic knowledge with the geometric representation, enabling user-guided machine learning involving physical objects. We first present a fast multimodal 3D reconstruction pipeline that brings linguistic understanding to AR by fusing CLIP vision-language features into the environment and object models. We then propose "in-situ" machine learning, which, in conjunction with the multimodal representation, enables new tools and interfaces for users to interact with physical spaces and objects in a spatially and linguistically meaningful manner. We demonstrate the usefulness of the proposed system through two real-world AR applications on Magic Leap 2: a) spatial search in physical environments with natural language and b) an intelligent inventory system that tracks object changes over time. We also make our full implementation and demo data available at (https://github.com/cy-xu/spatially_aware_AI) to encourage further exploration and research in spatially aware AI.
FineRecon: Depth-aware Feed-forward Network for Detailed 3D Reconstruction
Apr 04, 2023



Recent works on 3D reconstruction from posed images have demonstrated that direct inference of scene-level 3D geometry without iterative optimization is feasible using a deep neural network, showing remarkable promise and high efficiency. However, the reconstructed geometries, typically represented as a 3D truncated signed distance function (TSDF), are often coarse without fine geometric details. To address this problem, we propose three effective solutions for improving the fidelity of inference-based 3D reconstructions. We first present a resolution-agnostic TSDF supervision strategy to provide the network with a more accurate learning signal during training, avoiding the pitfalls of TSDF interpolation seen in previous work. We then introduce a depth guidance strategy using multi-view depth estimates to enhance the scene representation and recover more accurate surfaces. Finally, we develop a novel architecture for the final layers of the network, conditioning the output TSDF prediction on high-resolution image features in addition to coarse voxel features, enabling sharper reconstruction of fine details. Our method produces smooth and highly accurate reconstructions, showing significant improvements across multiple depth and 3D reconstruction metrics.
LivePose: Online 3D Reconstruction from Monocular Video with Dynamic Camera Poses
Mar 31, 2023



Dense 3D reconstruction from RGB images traditionally assumes static camera pose estimates. This assumption has endured, even as recent works have increasingly focused on real-time methods for mobile devices. However, the assumption of one pose per image does not hold for online execution: poses from real-time SLAM are dynamic and may be updated following events such as bundle adjustment and loop closure. This has been addressed in the RGB-D setting, by de-integrating past views and re-integrating them with updated poses, but it remains largely untreated in the RGB-only setting. We formalize this problem to define the new task of online reconstruction from dynamically-posed images. To support further research, we introduce a dataset called LivePose containing the dynamic poses from a SLAM system running on ScanNet. We select three recent reconstruction systems and apply a framework based on de-integration to adapt each one to the dynamic-pose setting. In addition, we propose a novel, non-linear de-integration module that learns to remove stale scene content. We show that responding to pose updates is critical for high-quality reconstruction, and that our de-integration framework is an effective solution.
Interactive Segmentation and Visualization for Tiny Objects in Multi-megapixel Images
Apr 21, 2022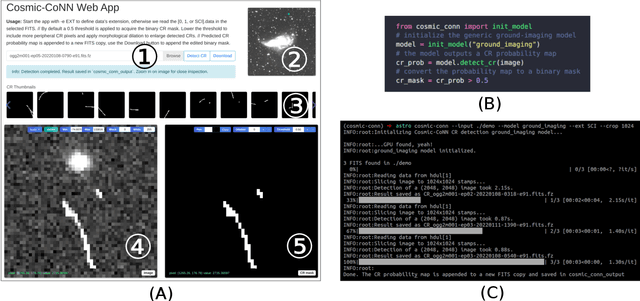
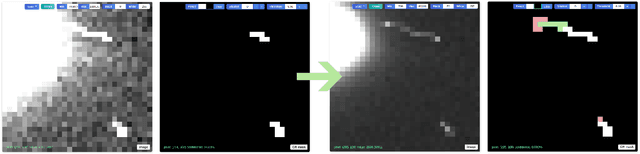
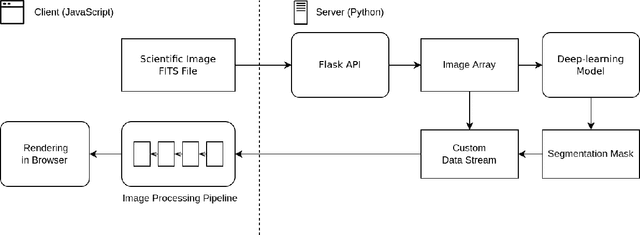
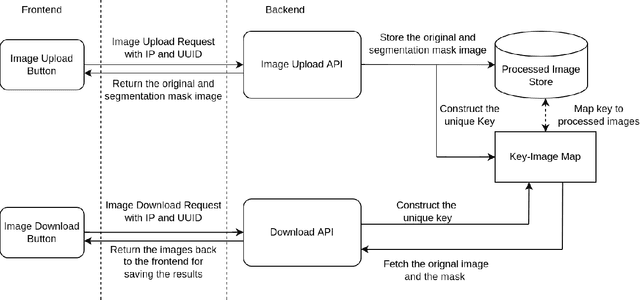
We introduce an interactive image segmentation and visualization framework for identifying, inspecting, and editing tiny objects (just a few pixels wide) in large multi-megapixel high-dynamic-range (HDR) images. Detecting cosmic rays (CRs) in astronomical observations is a cumbersome workflow that requires multiple tools, so we developed an interactive toolkit that unifies model inference, HDR image visualization, segmentation mask inspection and editing into a single graphical user interface. The feature set, initially designed for astronomical data, makes this work a useful research-supporting tool for human-in-the-loop tiny-object segmentation in scientific areas like biomedicine, materials science, remote sensing, etc., as well as computer vision. Our interface features mouse-controlled, synchronized, dual-window visualization of the image and the segmentation mask, a critical feature for locating tiny objects in multi-megapixel images. The browser-based tool can be readily hosted on the web to provide multi-user access and GPU acceleration for any device. The toolkit can also be used as a high-precision annotation tool, or adapted as the frontend for an interactive machine learning framework. Our open-source dataset, CR detection model, and visualization toolkit are available at https://github.com/cy-xu/cosmic-conn.
VoRTX: Volumetric 3D Reconstruction With Transformers for Voxelwise View Selection and Fusion
Dec 01, 2021

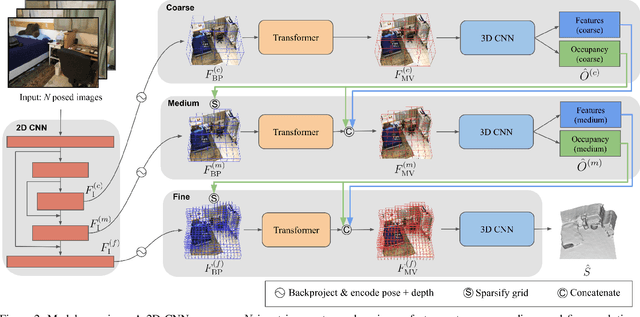

Recent volumetric 3D reconstruction methods can produce very accurate results, with plausible geometry even for unobserved surfaces. However, they face an undesirable trade-off when it comes to multi-view fusion. They can fuse all available view information by global averaging, thus losing fine detail, or they can heuristically cluster views for local fusion, thus restricting their ability to consider all views jointly. Our key insight is that greater detail can be retained without restricting view diversity by learning a view-fusion function conditioned on camera pose and image content. We propose to learn this multi-view fusion using a transformer. To this end, we introduce VoRTX, an end-to-end volumetric 3D reconstruction network using transformers for wide-baseline, multi-view feature fusion. Our model is occlusion-aware, leveraging the transformer architecture to predict an initial, projective scene geometry estimate. This estimate is used to avoid backprojecting image features through surfaces into occluded regions. We train our model on ScanNet and show that it produces better reconstructions than state-of-the-art methods. We also demonstrate generalization without any fine-tuning, outperforming the same state-of-the-art methods on two other datasets, TUM-RGBD and ICL-NUIM.
3DVNet: Multi-View Depth Prediction and Volumetric Refinement
Dec 01, 2021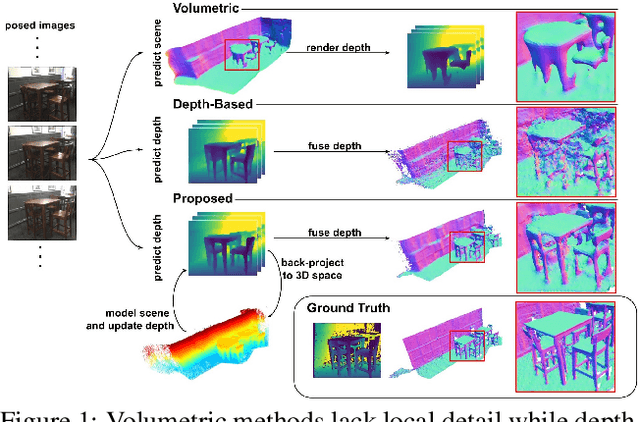

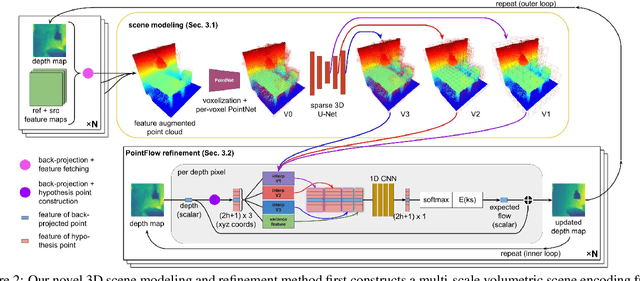

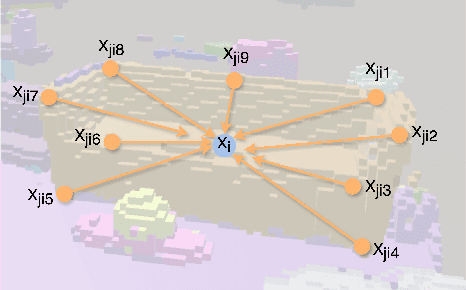
We present 3DVNet, a novel multi-view stereo (MVS) depth-prediction method that combines the advantages of previous depth-based and volumetric MVS approaches. Our key idea is the use of a 3D scene-modeling network that iteratively updates a set of coarse depth predictions, resulting in highly accurate predictions which agree on the underlying scene geometry. Unlike existing depth-prediction techniques, our method uses a volumetric 3D convolutional neural network (CNN) that operates in world space on all depth maps jointly. The network can therefore learn meaningful scene-level priors. Furthermore, unlike existing volumetric MVS techniques, our 3D CNN operates on a feature-augmented point cloud, allowing for effective aggregation of multi-view information and flexible iterative refinement of depth maps. Experimental results show our method exceeds state-of-the-art accuracy in both depth prediction and 3D reconstruction metrics on the ScanNet dataset, as well as a selection of scenes from the TUM-RGBD and ICL-NUIM datasets. This shows that our method is both effective and generalizes to new settings.
Sparse Fusion for Multimodal Transformers
Nov 24, 2021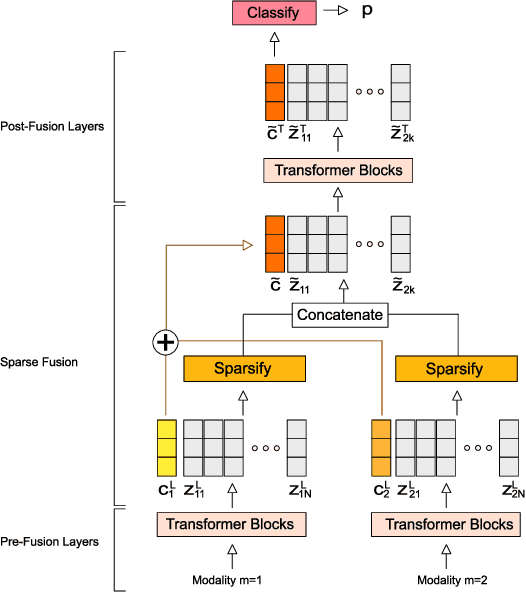
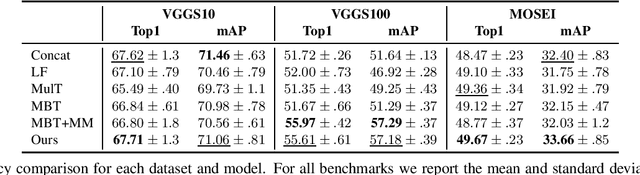
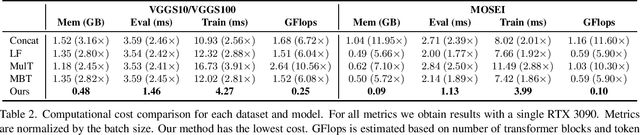
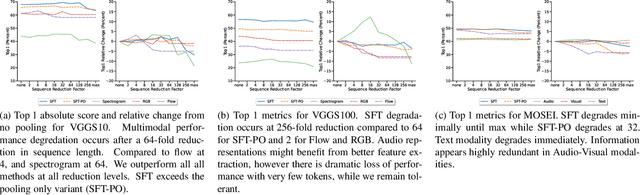
Multimodal classification is a core task in human-centric machine learning. We observe that information is highly complementary across modalities, thus unimodal information can be drastically sparsified prior to multimodal fusion without loss of accuracy. To this end, we present Sparse Fusion Transformers (SFT), a novel multimodal fusion method for transformers that performs comparably to existing state-of-the-art methods while having greatly reduced memory footprint and computation cost. Key to our idea is a sparse-pooling block that reduces unimodal token sets prior to cross-modality modeling. Evaluations are conducted on multiple multimodal benchmark datasets for a wide range of classification tasks. State-of-the-art performance is obtained on multiple benchmarks under similar experiment conditions, while reporting up to six-fold reduction in computational cost and memory requirements. Extensive ablation studies showcase our benefits of combining sparsification and multimodal learning over naive approaches. This paves the way for enabling multimodal learning on low-resource devices.