 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal 3D Fusion and In-Situ Learning for Spatially Aware AI
Oct 06, 2024
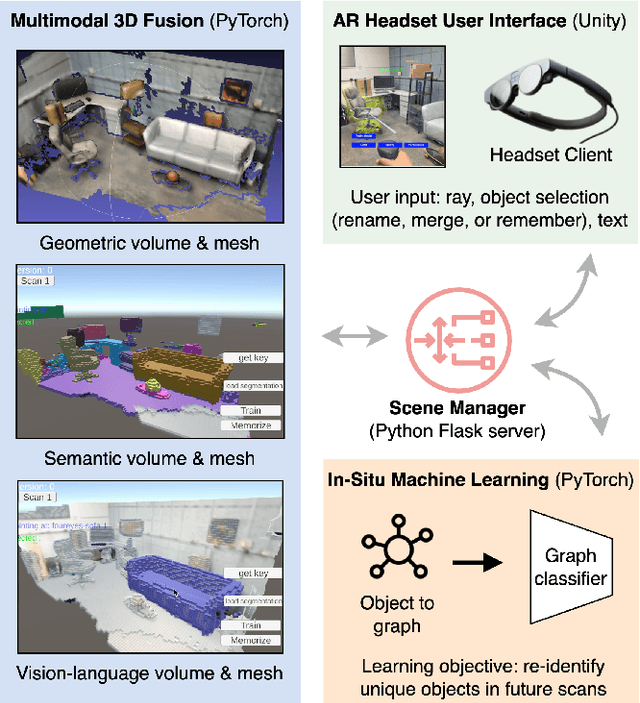

Seamless integration of virtual and physical worlds in augmented reality benefits from the system semantically "understanding" the physical environment. AR research has long focused on the potential of context awareness, demonstrating novel capabilities that leverage the semantics in the 3D environment for various object-level interactions. Meanwhile, the computer vision community has made leaps in neural vision-language understanding to enhance environment perception for autonomous tasks. In this work, we introduce a multimodal 3D object representation that unifies both semantic and linguistic knowledge with the geometric representation, enabling user-guided machine learning involving physical objects. We first present a fast multimodal 3D reconstruction pipeline that brings linguistic understanding to AR by fusing CLIP vision-language features into the environment and object models. We then propose "in-situ" machine learning, which, in conjunction with the multimodal representation, enables new tools and interfaces for users to interact with physical spaces and objects in a spatially and linguistically meaningful manner. We demonstrate the usefulness of the proposed system through two real-world AR applications on Magic Leap 2: a) spatial search in physical environments with natural language and b) an intelligent inventory system that tracks object changes over time. We also make our full implementation and demo data available at (https://github.com/cy-xu/spatially_aware_AI) to encourage further exploration and research in spatially aware AI.