 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Zealous and Restrained AI Recommendations in a Real-World Human-AI Collaboration Task
Oct 06, 2024



When designing an AI-assisted decision-making system, there is often a tradeoff between precision and recall in the AI's recommendations. We argue that careful exploitation of this tradeoff can harness the complementary strengths in the human-AI collaboration to significantly improve team performance. We investigate a real-world video anonymization task for which recall is paramount and more costly to improve. We analyze the performance of 78 professional annotators working with a) no AI assistance, b) a high-precision "restrained" AI, and c) a high-recall "zealous" AI in over 3,466 person-hours of annotation work. In comparison, the zealous AI helps human teammates achieve significantly shorter task completion time and higher recall. In a follow-up study, we remove AI assistance for everyone and find negative training effects on annotators trained with the restrained AI. These findings and our analysis point to important implications for the design of AI assistance in recall-demanding scenarios.
* 15 pages, 14 figures, accepted to ACM CHI 2023
Multimodal 3D Fusion and In-Situ Learning for Spatially Aware AI
Oct 06, 2024
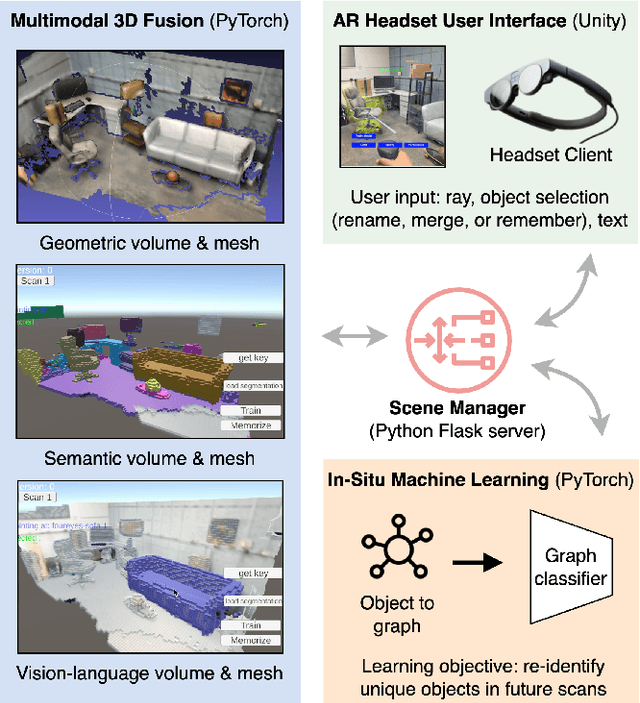
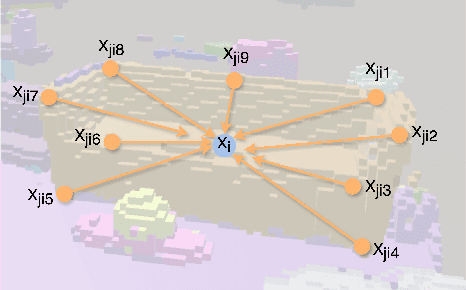

Seamless integration of virtual and physical worlds in augmented reality benefits from the system semantically "understanding" the physical environment. AR research has long focused on the potential of context awareness, demonstrating novel capabilities that leverage the semantics in the 3D environment for various object-level interactions. Meanwhile, the computer vision community has made leaps in neural vision-language understanding to enhance environment perception for autonomous tasks. In this work, we introduce a multimodal 3D object representation that unifies both semantic and linguistic knowledge with the geometric representation, enabling user-guided machine learning involving physical objects. We first present a fast multimodal 3D reconstruction pipeline that brings linguistic understanding to AR by fusing CLIP vision-language features into the environment and object models. We then propose "in-situ" machine learning, which, in conjunction with the multimodal representation, enables new tools and interfaces for users to interact with physical spaces and objects in a spatially and linguistically meaningful manner. We demonstrate the usefulness of the proposed system through two real-world AR applications on Magic Leap 2: a) spatial search in physical environments with natural language and b) an intelligent inventory system that tracks object changes over time. We also make our full implementation and demo data available at (https://github.com/cy-xu/spatially_aware_AI) to encourage further exploration and research in spatially aware AI.
Interactive Segmentation and Visualization for Tiny Objects in Multi-megapixel Images
Apr 21, 2022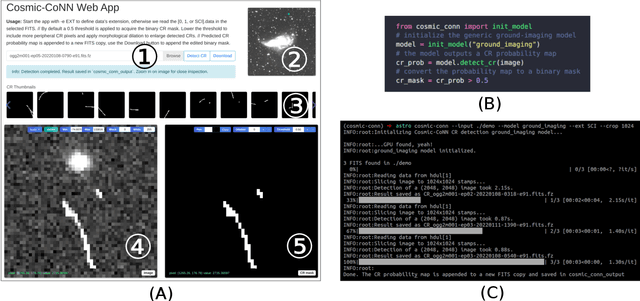
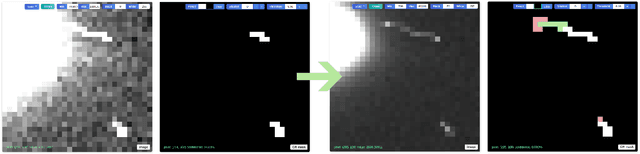
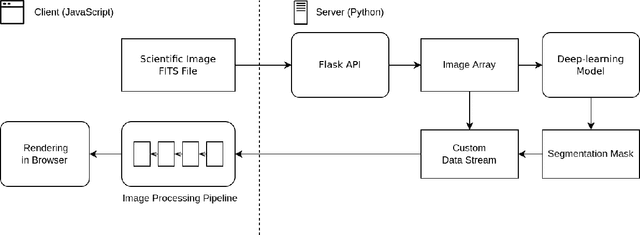
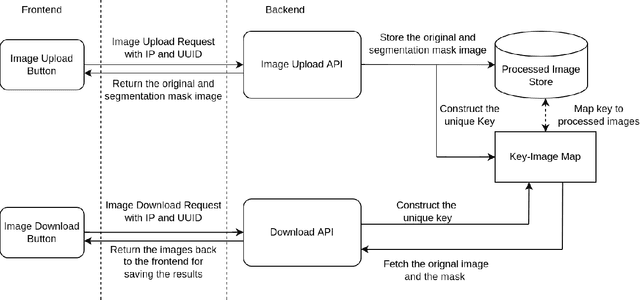
We introduce an interactive image segmentation and visualization framework for identifying, inspecting, and editing tiny objects (just a few pixels wide) in large multi-megapixel high-dynamic-range (HDR) images. Detecting cosmic rays (CRs) in astronomical observations is a cumbersome workflow that requires multiple tools, so we developed an interactive toolkit that unifies model inference, HDR image visualization, segmentation mask inspection and editing into a single graphical user interface. The feature set, initially designed for astronomical data, makes this work a useful research-supporting tool for human-in-the-loop tiny-object segmentation in scientific areas like biomedicine, materials science, remote sensing, etc., as well as computer vision. Our interface features mouse-controlled, synchronized, dual-window visualization of the image and the segmentation mask, a critical feature for locating tiny objects in multi-megapixel images. The browser-based tool can be readily hosted on the web to provide multi-user access and GPU acceleration for any device. The toolkit can also be used as a high-precision annotation tool, or adapted as the frontend for an interactive machine learning framework. Our open-source dataset, CR detection model, and visualization toolkit are available at https://github.com/cy-xu/cosmic-conn.
Cosmic-CoNN: A Cosmic Ray Detection Deep-Learning Framework, Dataset, and Toolkit
Jun 28, 2021
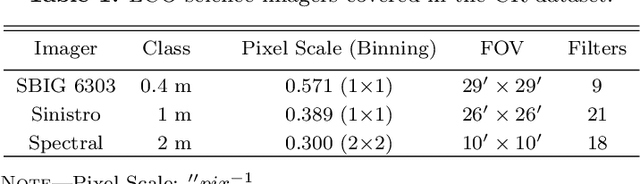
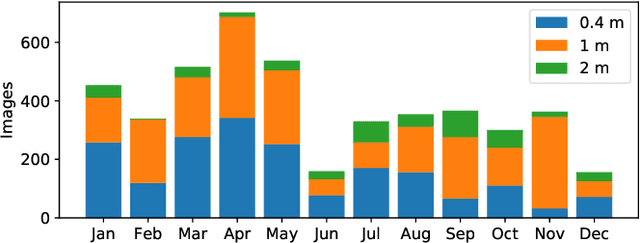
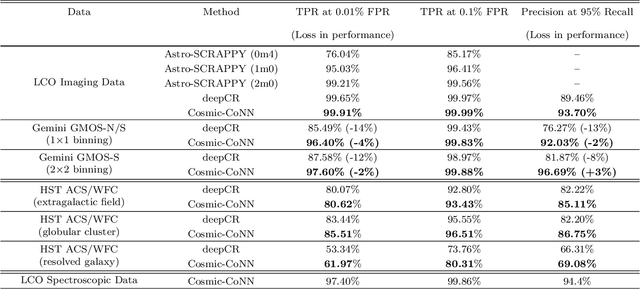
Rejecting cosmic rays (CRs) is essential for scientific interpretation of CCD-captured data, but detecting CRs in single-exposure images has remained challenging. Conventional CR-detection algorithms require tuning multiple parameters experimentally making it hard to automate across different instruments or observation requests. Recent work using deep learning to train CR-detection models has demonstrated promising results. However, instrument-specific models suffer from performance loss on images from ground-based facilities not included in the training data. In this work, we present Cosmic-CoNN, a deep-learning framework designed to produce generic CR-detection models. We build a large, diverse ground-based CR dataset leveraging thousands of images from the Las Cumbres Observatory global telescope network to produce a generic CR-detection model which achieves a 99.91% true-positive detection rate and maintains over 96.40% true-positive rates on unseen data from Gemini GMOS-N/S, with a false-positive rate of 0.01%. Apart from the open-source framework and dataset, we also build a suite of tools including console commands, a web-based application, and Python APIs to make automatic, robust CR detection widely accessible by the community of astronomers.