 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrism: Semi-Supervised Multi-View Stereo with Monocular Structure Priors
Dec 08, 2024



The promise of unsupervised multi-view-stereo (MVS) is to leverage large unlabeled datasets, yet current methods underperform when training on difficult data, such as handheld smartphone videos of indoor scenes. Meanwhile, high-quality synthetic datasets are available but MVS networks trained on these datasets fail to generalize to real-world examples. To bridge this gap, we propose a semi-supervised learning framework that allows us to train on real and rendered images jointly, capturing structural priors from synthetic data while ensuring parity with the real-world domain. Central to our framework is a novel set of losses that leverages powerful existing monocular relative-depth estimators trained on the synthetic dataset, transferring the rich structure of this relative depth to the MVS predictions on unlabeled data. Inspired by perceptual image metrics, we compare the MVS and monocular predictions via a deep feature loss and a multi-scale statistical loss. Our full framework, which we call Prism, achieves large quantitative and qualitative improvements over current unsupervised and synthetic-supervised MVS networks. This is a best-case-scenario result, opening the door to using both unlabeled smartphone videos and photorealistic synthetic datasets for training MVS networks.
Sparse Fusion for Multimodal Transformers
Nov 24, 2021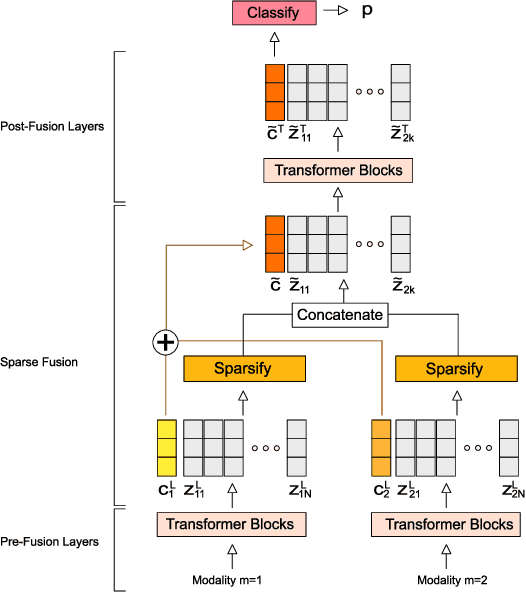
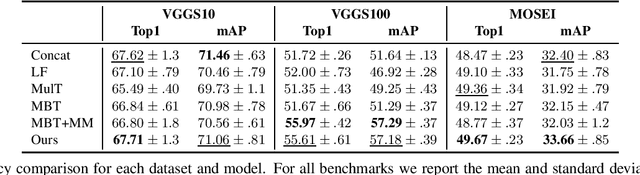
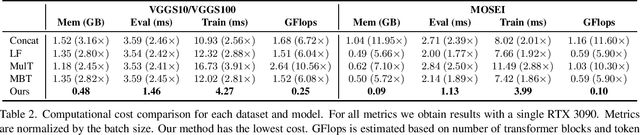
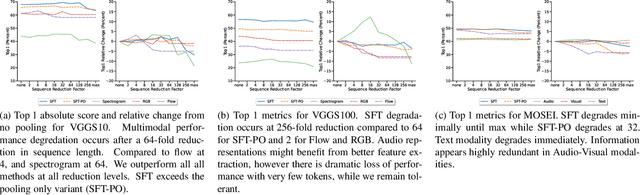
Multimodal classification is a core task in human-centric machine learning. We observe that information is highly complementary across modalities, thus unimodal information can be drastically sparsified prior to multimodal fusion without loss of accuracy. To this end, we present Sparse Fusion Transformers (SFT), a novel multimodal fusion method for transformers that performs comparably to existing state-of-the-art methods while having greatly reduced memory footprint and computation cost. Key to our idea is a sparse-pooling block that reduces unimodal token sets prior to cross-modality modeling. Evaluations are conducted on multiple multimodal benchmark datasets for a wide range of classification tasks. State-of-the-art performance is obtained on multiple benchmarks under similar experiment conditions, while reporting up to six-fold reduction in computational cost and memory requirements. Extensive ablation studies showcase our benefits of combining sparsification and multimodal learning over naive approaches. This paves the way for enabling multimodal learning on low-resource devices.
Augmentation Strategies for Learning with Noisy Labels
Mar 04, 2021
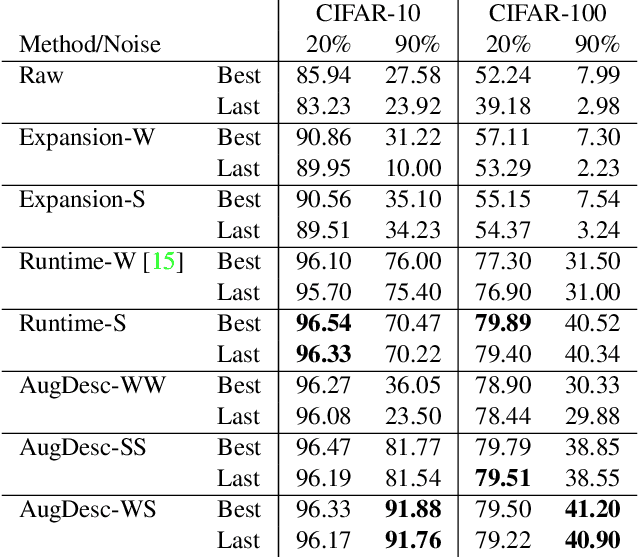
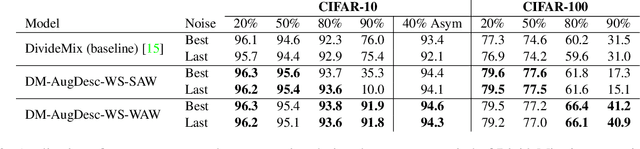

Imperfect labels are ubiquitous in real-world datasets. Several recent successful methods for training deep neural networks (DNNs) robust to label noise have used two primary techniques: filtering samples based on loss during a warm-up phase to curate an initial set of cleanly labeled samples, and using the output of a network as a pseudo-label for subsequent loss calculations. In this paper, we evaluate different augmentation strategies for algorithms tackling the "learning with noisy labels" problem. We propose and examine multiple augmentation strategies and evaluate them using synthetic datasets based on CIFAR-10 and CIFAR-100, as well as on the real-world dataset Clothing1M. Due to several commonalities in these algorithms, we find that using one set of augmentations for loss modeling tasks and another set for learning is the most effective, improving results on the state-of-the-art and other previous methods. Furthermore, we find that applying augmentation during the warm-up period can negatively impact the loss convergence behavior of correctly versus incorrectly labeled samples. We introduce this augmentation strategy to the state-of-the-art technique and demonstrate that we can improve performance across all evaluated noise levels. In particular, we improve accuracy on the CIFAR-10 benchmark at 90% symmetric noise by more than 15% in absolute accuracy and we also improve performance on the real-world dataset Clothing1M. (* equal contribution)