 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICLR: In-Context Learning of Representations
Dec 29, 2024



Recent work has demonstrated that semantics specified by pretraining data influence how representations of different concepts are organized in a large language model (LLM). However, given the open-ended nature of LLMs, e.g., their ability to in-context learn, we can ask whether models alter these pretraining semantics to adopt alternative, context-specified ones. Specifically, if we provide in-context exemplars wherein a concept plays a different role than what the pretraining data suggests, do models reorganize their representations in accordance with these novel semantics? To answer this question, we take inspiration from the theory of conceptual role semantics and define a toy "graph tracing" task wherein the nodes of the graph are referenced via concepts seen during training (e.g., apple, bird, etc.) and the connectivity of the graph is defined via some predefined structure (e.g., a square grid). Given exemplars that indicate traces of random walks on the graph, we analyze intermediate representations of the model and find that as the amount of context is scaled, there is a sudden re-organization from pretrained semantic representations to in-context representations aligned with the graph structure. Further, we find that when reference concepts have correlations in their semantics (e.g., Monday, Tuesday, etc.), the context-specified graph structure is still present in the representations, but is unable to dominate the pretrained structure. To explain these results, we analogize our task to energy minimization for a predefined graph topology, providing evidence towards an implicit optimization process to infer context-specified semantics. Overall, our findings indicate scaling context-size can flexibly re-organize model representations, possibly unlocking novel capabilities.
Representation Shattering in Transformers: A Synthetic Study with Knowledge Editing
Oct 22, 2024Knowledge Editing (KE) algorithms alter models' internal weights to perform targeted updates to incorrect, outdated, or otherwise unwanted factual associations. In order to better define the possibilities and limitations of these approaches, recent work has shown that applying KE can adversely affect models' factual recall accuracy and diminish their general reasoning abilities. While these studies give broad insights into the potential harms of KE algorithms, e.g., via performance evaluations on benchmarks, we argue little is understood as to why such destructive failures occur. Is it possible KE methods distort representations of concepts beyond the targeted fact, hence hampering abilities at broad? If so, what is the extent of this distortion? To take a step towards addressing such questions, we define a novel synthetic task wherein a Transformer is trained from scratch to internalize a ``structured'' knowledge graph. The structure enforces relationships between entities of the graph, such that editing a factual association has "trickling effects" on other entities in the graph (e.g., altering X's parent is Y to Z affects who X's siblings' parent is). Through evaluations of edited models and analysis of extracted representations, we show that KE inadvertently affects representations of entities beyond the targeted one, distorting relevant structures that allow a model to infer unseen knowledge about an entity. We call this phenomenon representation shattering and demonstrate that it results in degradation of factual recall and reasoning performance more broadly. To corroborate our findings in a more naturalistic setup, we perform preliminary experiments with a pretrained GPT-2-XL model and reproduce the representation shattering effect therein as well. Overall, our work yields a precise mechanistic hypothesis to explain why KE has adverse effects on model capabilities.
Joint-Task Regularization for Partially Labeled Multi-Task Learning
Apr 02, 2024



Multi-task learning has become increasingly popular in the machine learning field, but its practicality is hindered by the need for large, labeled datasets. Most multi-task learning methods depend on fully labeled datasets wherein each input example is accompanied by ground-truth labels for all target tasks. Unfortunately, curating such datasets can be prohibitively expensive and impractical, especially for dense prediction tasks which require per-pixel labels for each image. With this in mind, we propose Joint-Task Regularization (JTR), an intuitive technique which leverages cross-task relations to simultaneously regularize all tasks in a single joint-task latent space to improve learning when data is not fully labeled for all tasks. JTR stands out from existing approaches in that it regularizes all tasks jointly rather than separately in pairs -- therefore, it achieves linear complexity relative to the number of tasks while previous methods scale quadratically. To demonstrate the validity of our approach, we extensively benchmark our method across a wide variety of partially labeled scenarios based on NYU-v2, Cityscapes, and Taskonomy.
Towards an Understanding of Stepwise Inference in Transformers: A Synthetic Graph Navigation Model
Feb 12, 2024Stepwise inference protocols, such as scratchpads and chain-of-thought, help language models solve complex problems by decomposing them into a sequence of simpler subproblems. Despite the significant gain in performance achieved via these protocols, the underlying mechanisms of stepwise inference have remained elusive. To address this, we propose to study autoregressive Transformer models on a synthetic task that embodies the multi-step nature of problems where stepwise inference is generally most useful. Specifically, we define a graph navigation problem wherein a model is tasked with traversing a path from a start to a goal node on the graph. Despite is simplicity, we find we can empirically reproduce and analyze several phenomena observed at scale: (i) the stepwise inference reasoning gap, the cause of which we find in the structure of the training data; (ii) a diversity-accuracy tradeoff in model generations as sampling temperature varies; (iii) a simplicity bias in the model's output; and (iv) compositional generalization and a primacy bias with in-context exemplars. Overall, our work introduces a grounded, synthetic framework for studying stepwise inference and offers mechanistic hypotheses that can lay the foundation for a deeper understanding of this phenomenon.
Augmentation Strategies for Learning with Noisy Labels
Mar 04, 2021
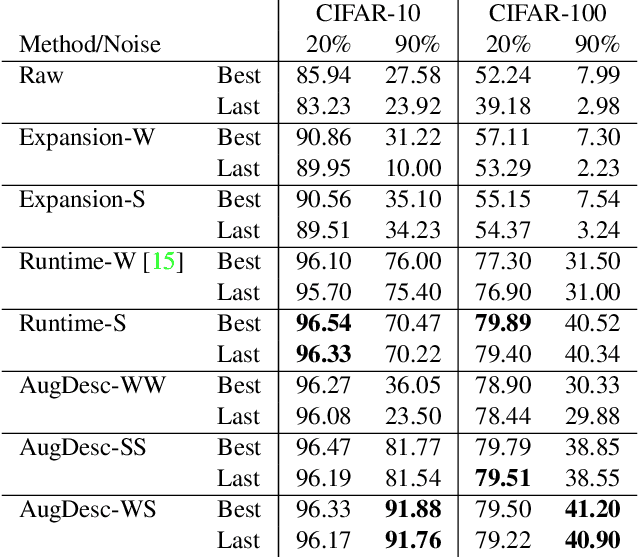
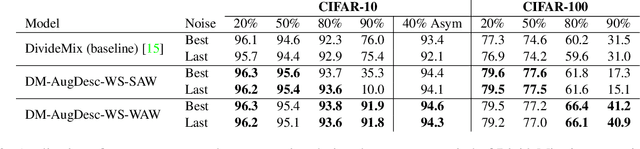

Imperfect labels are ubiquitous in real-world datasets. Several recent successful methods for training deep neural networks (DNNs) robust to label noise have used two primary techniques: filtering samples based on loss during a warm-up phase to curate an initial set of cleanly labeled samples, and using the output of a network as a pseudo-label for subsequent loss calculations. In this paper, we evaluate different augmentation strategies for algorithms tackling the "learning with noisy labels" problem. We propose and examine multiple augmentation strategies and evaluate them using synthetic datasets based on CIFAR-10 and CIFAR-100, as well as on the real-world dataset Clothing1M. Due to several commonalities in these algorithms, we find that using one set of augmentations for loss modeling tasks and another set for learning is the most effective, improving results on the state-of-the-art and other previous methods. Furthermore, we find that applying augmentation during the warm-up period can negatively impact the loss convergence behavior of correctly versus incorrectly labeled samples. We introduce this augmentation strategy to the state-of-the-art technique and demonstrate that we can improve performance across all evaluated noise levels. In particular, we improve accuracy on the CIFAR-10 benchmark at 90% symmetric noise by more than 15% in absolute accuracy and we also improve performance on the real-world dataset Clothing1M. (* equal contribution)