 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStranding Risk for Underactuated Vessels in Complex Ocean Currents: Analysis and Controllers
Jul 04, 2023Low-propulsion vessels can take advantage of powerful ocean currents to navigate towards a destination. Recent results demonstrated that vessels can reach their destination with high probability despite forecast errors. However, these results do not consider the critical aspect of safety of such vessels: because of their low propulsion which is much smaller than the magnitude of currents, they might end up in currents that inevitably push them into unsafe areas such as shallow areas, garbage patches, and shipping lanes. In this work, we first investigate the risk of stranding for free-floating vessels in the Northeast Pacific. We find that at least 5.04% would strand within 90 days. Next, we encode the unsafe sets as hard constraints into Hamilton-Jacobi Multi-Time Reachability (HJ-MTR) to synthesize a feedback policy that is equivalent to re-planning at each time step at low computational cost. While applying this policy closed-loop guarantees safe operation when the currents are known, in realistic situations only imperfect forecasts are available. We demonstrate the safety of our approach in such realistic situations empirically with large-scale simulations of a vessel navigating in high-risk regions in the Northeast Pacific. We find that applying our policy closed-loop with daily re-planning on new forecasts can ensure safety with high probability even under forecast errors that exceed the maximal propulsion. Our method significantly improves safety over the baselines and still achieves a timely arrival of the vessel at the destination.
A Dual-Source Attention Transformer for Multi-Person Pose Tracking
Jun 09, 2023Multi-person pose tracking is an important element for many applications and requires to estimate the human poses of all persons in a video and to track them over time. The association of poses across frames remains an open research problem, in particular for online tracking methods, due to motion blur, crowded scenes and occlusions. To tackle the association challenge, we propose a Dual-Source Attention Transformer that incorporates three core aspects: i) In order to re-identify persons that have been occluded, we propose a pose-conditioned re-identification network that provides an initial embedding and allows to match persons even if the number of visible joints differs between the frames. ii) We incorporate edge embeddings based on temporal pose similarity and the impact of appearance and pose similarity is automatically adapted. iii) We propose an attention based matching layer for pose-to-track association and duplicate removal. We evaluate our approach on Market1501, PoseTrack 2018 and PoseTrack21.
Keypoint Message Passing for Video-based Person Re-Identification
Nov 16, 2021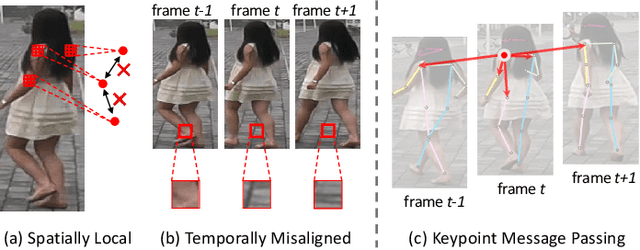
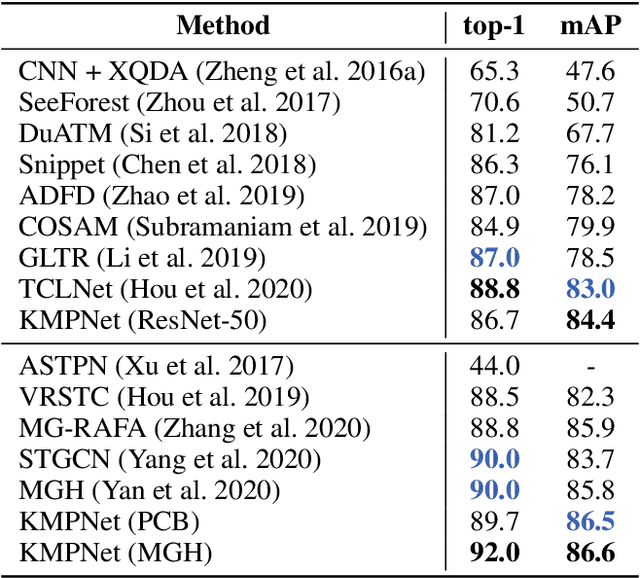
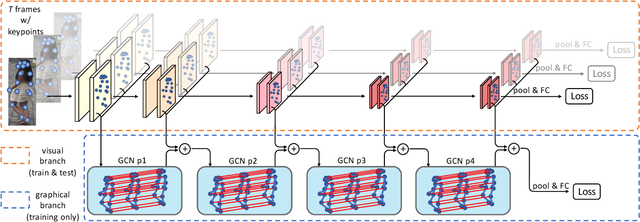
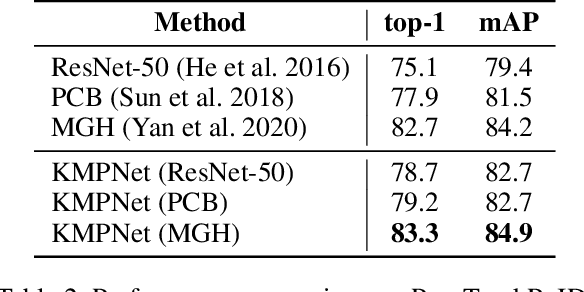
Video-based person re-identification (re-ID) is an important technique in visual surveillance systems which aims to match video snippets of people captured by different cameras. Existing methods are mostly based on convolutional neural networks (CNNs), whose building blocks either process local neighbor pixels at a time, or, when 3D convolutions are used to model temporal information, suffer from the misalignment problem caused by person movement. In this paper, we propose to overcome the limitations of normal convolutions with a human-oriented graph method. Specifically, features located at person joint keypoints are extracted and connected as a spatial-temporal graph. These keypoint features are then updated by message passing from their connected nodes with a graph convolutional network (GCN). During training, the GCN can be attached to any CNN-based person re-ID model to assist representation learning on feature maps, whilst it can be dropped after training for better inference speed. Our method brings significant improvements over the CNN-based baseline model on the MARS dataset with generated person keypoints and a newly annotated dataset: PoseTrackReID. It also defines a new state-of-the-art method in terms of top-1 accuracy and mean average precision in comparison to prior works.
PoseTrackReID: Dataset Description
Nov 12, 2020Current datasets for video-based person re-identification (re-ID) do not include structural knowledge in form of human pose annotations for the persons of interest. Nonetheless, pose information is very helpful to disentangle useful feature information from background or occlusion noise. Especially real-world scenarios, such as surveillance, contain a lot of occlusions in human crowds or by obstacles. On the other hand, video-based person re-ID can benefit other tasks such as multi-person pose tracking in terms of robust feature matching. For that reason, we present PoseTrackReID, a large-scale dataset for multi-person pose tracking and video-based person re-ID. With PoseTrackReID, we want to bridge the gap between person re-ID and multi-person pose tracking. Additionally, this dataset provides a good benchmark for current state-of-the-art methods on multi-frame person re-ID.
Self-supervised Keypoint Correspondences for Multi-Person Pose Estimation and Tracking in Videos
Jun 02, 2020

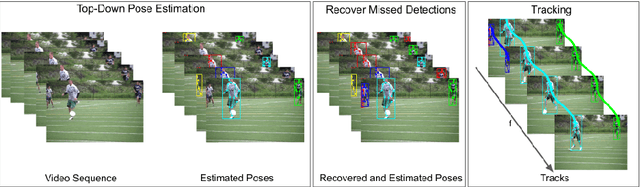

Video annotation is expensive and time consuming. Consequently, datasets for multi-person pose estimation and tracking are less diverse and have more sparse annotations compared to large scale image datasets for human pose estimation. This makes it challenging to learn deep learning based models for associating keypoints across frames that are robust to nuisance factors such as motion blur and occlusions for the task of multi-person pose tracking. To address this issue, we propose an approach that relies on keypoint correspondences for associating persons in videos. Instead of training the network for estimating keypoint correspondences on video data, it is trained on a large scale image datasets for human pose estimation using self-supervision. Combined with a top-down framework for human pose estimation, we use keypoints correspondences to (i) recover missed pose detections (ii) associate pose detections across video frames. Our approach achieves state-of-the-art results for multi-frame pose estimation and multi-person pose tracking on the PosTrack $2017$ and PoseTrack $2018$ data sets.
Unifying Part Detection and Association for Recurrent Multi-Person Pose Estimation
Apr 26, 2019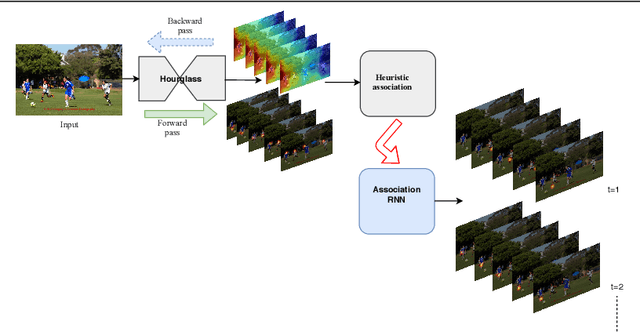
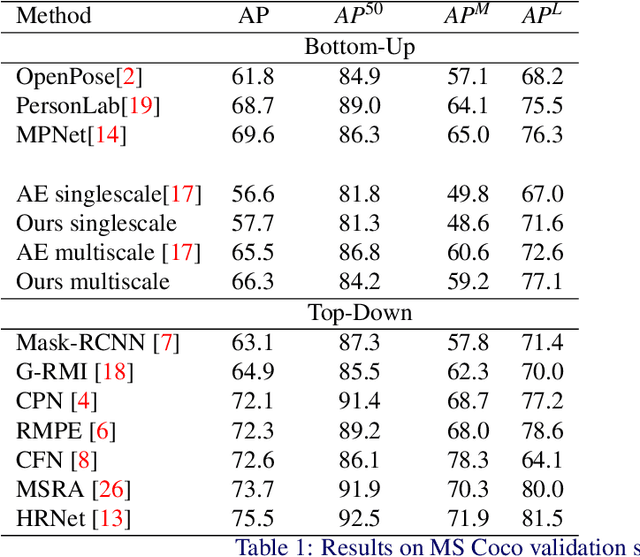


We propose a joint model of human joint detection and association for 2D multi-person pose estimation (MPPE). The approach unifies training of joint detection and association without a need for further processing or sophisticated heuristics in order to associate the joints with people individually. The approach consists of two stages, where in the first stage joint detection heatmaps and association features are extracted, and in the second stage, whose input are the extracted features of the first stage, we introduce a recurrent neural network (RNN) which predicts the heatmaps of a single person's joints in each iteration. In addition, the network learns a stopping criterion in order to halt once it has identified all individuals in the image. This approach allowed us to eliminate several heuristic assumptions and parameters needed for association which do not necessarily hold true. Additionally, such an end-to-end approach allows the final objective to be known and directly optimized over during training. We evaluated our model on the challenging MSCOCO dataset and obtained an improvement over the baseline, particularly in challenging scenes with occlusions.
Joint Flow: Temporal Flow Fields for Multi Person Tracking
Jul 20, 2018
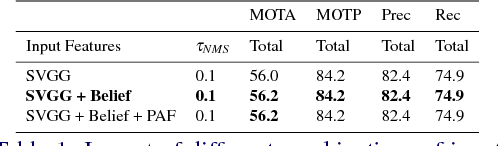
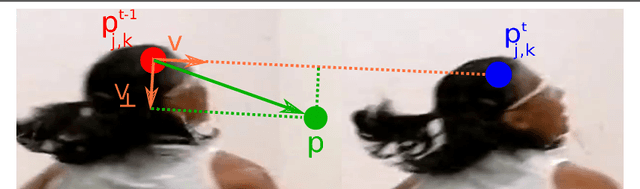
In this work we propose an online multi person pose tracking approach which works on two consecutive frames $I_{t-1}$ and $I_t$. The general formulation of our temporal network allows to rely on any multi person pose estimation approach as spatial network. From the spatial network we extract image features and pose features for both frames. These features serve as input for our temporal model that predicts Temporal Flow Fields (TFF). These TFF are vector fields which indicate the direction in which each body joint is going to move from frame $I_{t-1}$ to frame $I_t$. This novel representation allows to formulate a similarity measure of detected joints. These similarities are used as binary potentials in a bipartite graph optimization problem in order to perform tracking of multiple poses. We show that these TFF can be learned by a relative small CNN network whilst achieving state-of-the-art multi person pose tracking results.
A Dual-Source Approach for 3D Human Pose Estimation from a Single Image
Sep 06, 2017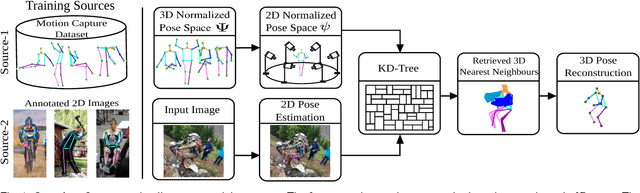
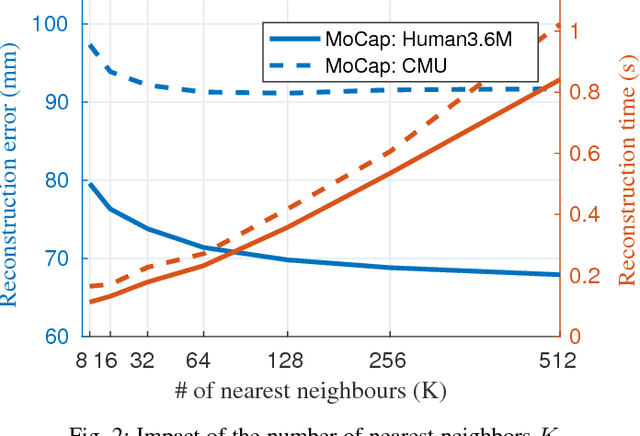
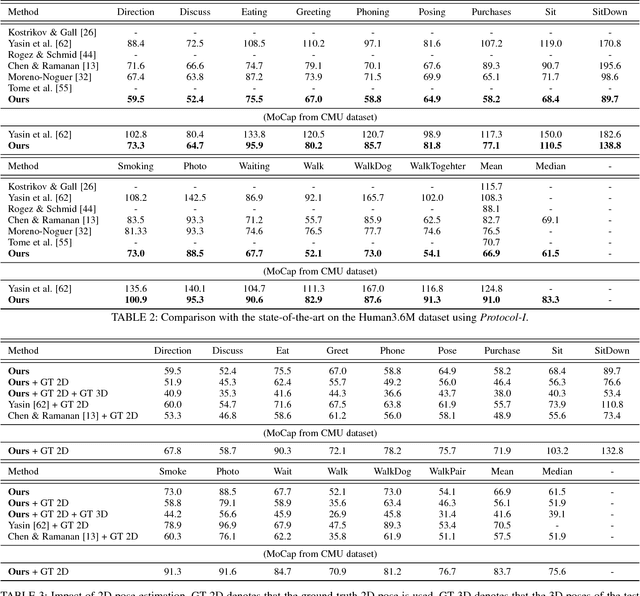
In this work we address the challenging problem of 3D human pose estimation from single images. Recent approaches learn deep neural networks to regress 3D pose directly from images. One major challenge for such methods, however, is the collection of training data. Specifically, collecting large amounts of training data containing unconstrained images annotated with accurate 3D poses is infeasible. We therefore propose to use two independent training sources. The first source consists of accurate 3D motion capture data, and the second source consists of unconstrained images with annotated 2D poses. To integrate both sources, we propose a dual-source approach that combines 2D pose estimation with efficient 3D pose retrieval. To this end, we first convert the motion capture data into a normalized 2D pose space, and separately learn a 2D pose estimation model from the image data. During inference, we estimate the 2D pose and efficiently retrieve the nearest 3D poses. We then jointly estimate a mapping from the 3D pose space to the image and reconstruct the 3D pose. We provide a comprehensive evaluation of the proposed method and experimentally demonstrate the effectiveness of our approach, even when the skeleton structures of the two sources differ substantially.