 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Keypoint Correspondences for Multi-Person Pose Estimation and Tracking in Videos
Jun 02, 2020

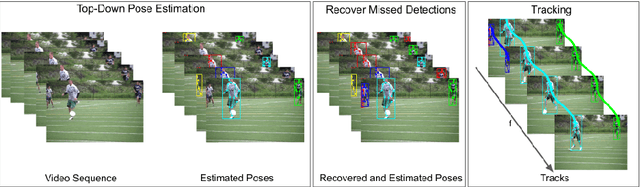

Video annotation is expensive and time consuming. Consequently, datasets for multi-person pose estimation and tracking are less diverse and have more sparse annotations compared to large scale image datasets for human pose estimation. This makes it challenging to learn deep learning based models for associating keypoints across frames that are robust to nuisance factors such as motion blur and occlusions for the task of multi-person pose tracking. To address this issue, we propose an approach that relies on keypoint correspondences for associating persons in videos. Instead of training the network for estimating keypoint correspondences on video data, it is trained on a large scale image datasets for human pose estimation using self-supervision. Combined with a top-down framework for human pose estimation, we use keypoints correspondences to (i) recover missed pose detections (ii) associate pose detections across video frames. Our approach achieves state-of-the-art results for multi-frame pose estimation and multi-person pose tracking on the PosTrack $2017$ and PoseTrack $2018$ data sets.
Detection-Tracking for Efficient Person Analysis: The DetTA Pipeline
Jul 28, 2018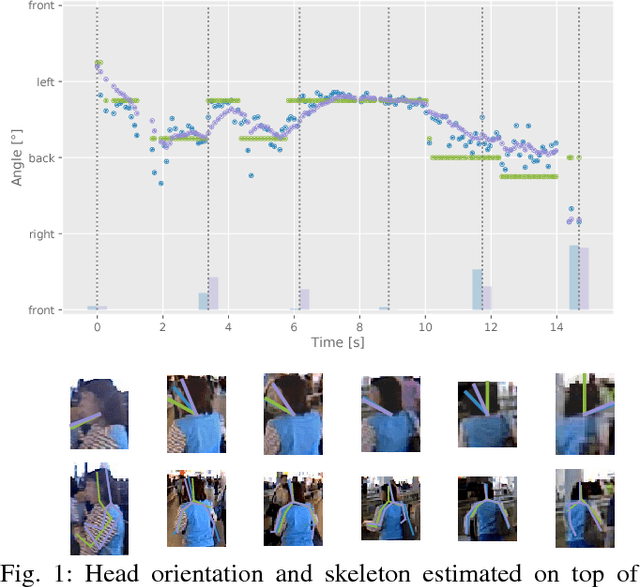
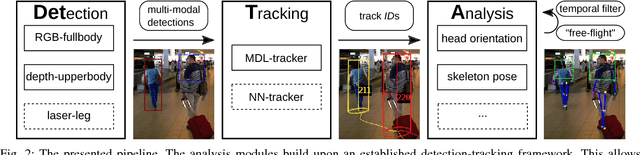
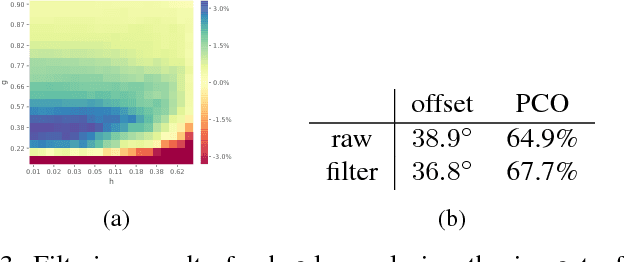
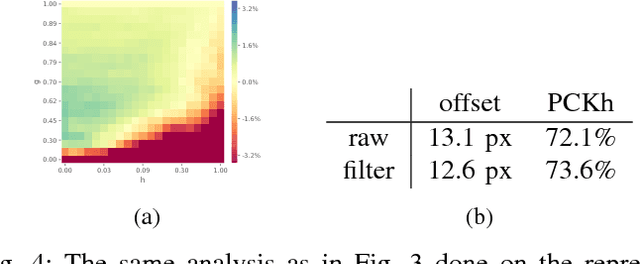
In the past decade many robots were deployed in the wild, and people detection and tracking is an important component of such deployments. On top of that, one often needs to run modules which analyze persons and extract higher level attributes such as age and gender, or dynamic information like gaze and pose. The latter ones are especially necessary for building a reactive, social robot-person interaction. In this paper, we combine those components in a fully modular detection-tracking-analysis pipeline, called DetTA. We investigate the benefits of such an integration on the example of head and skeleton pose, by using the consistent track ID for a temporal filtering of the analysis modules' observations, showing a slight improvement in a challenging real-world scenario. We also study the potential of a so-called "free-flight" mode, where the analysis of a person attribute only relies on the filter's predictions for certain frames. Here, our study shows that this boosts the runtime dramatically, while the prediction quality remains stable. This insight is especially important for reducing power consumption and sharing precious (GPU-)memory when running many analysis components on a mobile platform, especially so in the era of expensive deep learning methods.