 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-Coupled Volume Propagation for Stereo Matching
Dec 30, 2022Several leading methods on public benchmarks for depth-from-stereo rely on memory-demanding 4D cost volumes and computationally intensive 3D convolutions for feature matching. We suggest a new way to process the 4D cost volume where we merge two different concepts in one deeply integrated framework to achieve a symbiotic relationship. A feature matching part is responsible for identifying matching pixels pairs along the baseline while a concurrent image volume part is inspired by depth-from-mono CNNs. However, instead of predicting depth directly from image features, it provides additional context to resolve ambiguities during pixel matching. More technically, the processing of the 4D cost volume is separated into a 2D propagation and a 3D propagation part. Starting from feature maps of the left image, the 2D propagation assists the 3D propagation part of the cost volume at different layers by adding visual features to the geometric context. By combining both parts, we can safely reduce the scale of 3D convolution layers in the matching part without sacrificing accuracy. Experiments demonstrate that our end-to-end trained CNN is ranked 2nd on KITTI2012 and ETH3D benchmarks while being significantly faster than the 1st-ranked method. Furthermore, we notice that the coupling of image and matching-volume improves fine-scale details as demonstrated by our qualitative analysis.
Bonn Activity Maps: Dataset Description
Dec 13, 2019
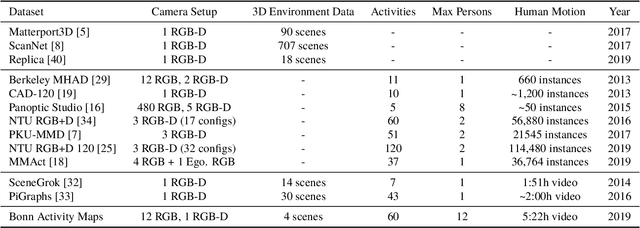


The key prerequisite for accessing the huge potential of current machine learning techniques is the availability of large databases that capture the complex relations of interest. Previous datasets are focused on either 3D scene representations with semantic information, tracking of multiple persons and recognition of their actions, or activity recognition of a single person in captured 3D environments. We present Bonn Activity Maps, a large-scale dataset for human tracking, activity recognition and anticipation of multiple persons. Our dataset comprises four different scenes that have been recorded by time-synchronized cameras each only capturing the scene partially, the reconstructed 3D models with semantic annotations, motion trajectories for individual people including 3D human poses as well as human activity annotations. We utilize the annotations to generate activity likelihoods on the 3D models called activity maps.