 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-Preserving Mesh Decimation for Normal Integration
Apr 01, 2025Normal integration reconstructs 3D surfaces from normal maps obtained e.g. by photometric stereo. These normal maps capture surface details down to the pixel level but require large computational resources for integration at high resolutions. In this work, we replace the dense pixel grid with a sparse anisotropic triangle mesh prior to normal integration. We adapt the triangle mesh to the local geometry in the case of complex surface structures and remove oversampling from flat featureless regions. For high-resolution images, the resulting compression reduces normal integration runtimes from hours to minutes while maintaining high surface accuracy. Our main contribution is the derivation of the well-known quadric error measure from mesh decimation for screen space applications and its combination with optimal Delaunay triangulation.
Image Segmentation from Shadow-Hints using Minimum Spanning Trees
Nov 10, 2024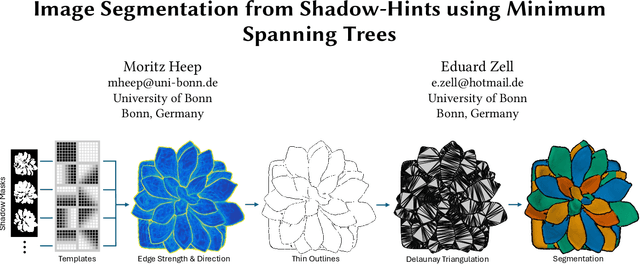

Image segmentation in RGB space is a notoriously difficult task where state-of-the-art methods are trained on thousands or even millions of annotated images. While the performance is impressive, it is still not perfect. We propose a novel image segmentation method, achieving similar segmentation quality but without training. Instead, we require an image sequence with a static camera and a single light source at varying positions, as used in for photometric stereo, for example.
An Adaptive Screen-Space Meshing Approach for Normal Integration
Sep 25, 2024



Reconstructing surfaces from normals is a key component of photometric stereo. This work introduces an adaptive surface triangulation in the image domain and afterwards performs the normal integration on a triangle mesh. Our key insight is that surface curvature can be computed from normals. Based on the curvature, we identify flat areas and aggregate pixels into triangles. The approximation quality is controlled by a single user parameter facilitating a seamless generation of low- to high-resolution meshes. Compared to pixel grids, our triangle meshes adapt locally to surface details and allow for a sparser representation. Our new mesh-based formulation of the normal integration problem is strictly derived from discrete differential geometry and leads to well-conditioned linear systems. Results on real and synthetic data show that 10 to 100 times less vertices are required than pixels. Experiments suggest that this sparsity translates into a sublinear runtime in the number of pixels. For 64 MP normal maps, our meshing-first approach generates and integrates meshes in minutes while pixel-based approaches require hours just for the integration.
Image-Coupled Volume Propagation for Stereo Matching
Dec 30, 2022Several leading methods on public benchmarks for depth-from-stereo rely on memory-demanding 4D cost volumes and computationally intensive 3D convolutions for feature matching. We suggest a new way to process the 4D cost volume where we merge two different concepts in one deeply integrated framework to achieve a symbiotic relationship. A feature matching part is responsible for identifying matching pixels pairs along the baseline while a concurrent image volume part is inspired by depth-from-mono CNNs. However, instead of predicting depth directly from image features, it provides additional context to resolve ambiguities during pixel matching. More technically, the processing of the 4D cost volume is separated into a 2D propagation and a 3D propagation part. Starting from feature maps of the left image, the 2D propagation assists the 3D propagation part of the cost volume at different layers by adding visual features to the geometric context. By combining both parts, we can safely reduce the scale of 3D convolution layers in the matching part without sacrificing accuracy. Experiments demonstrate that our end-to-end trained CNN is ranked 2nd on KITTI2012 and ETH3D benchmarks while being significantly faster than the 1st-ranked method. Furthermore, we notice that the coupling of image and matching-volume improves fine-scale details as demonstrated by our qualitative analysis.