 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAVA: Template-free Animatable Volumetric Actors
Jun 21, 2022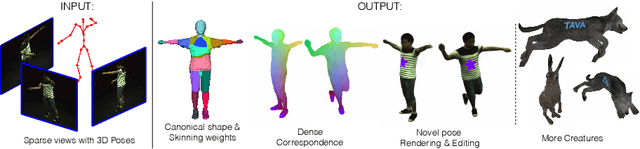

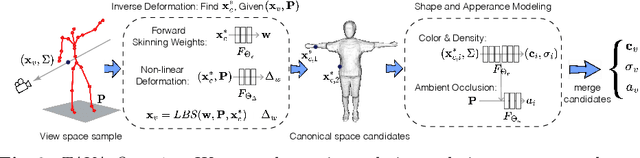
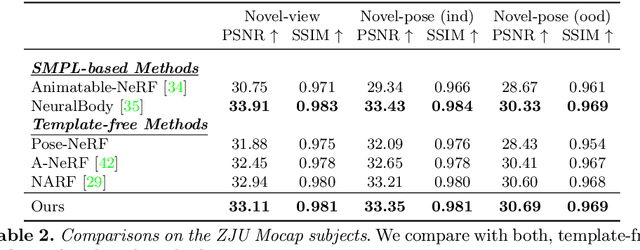
Coordinate-based volumetric representations have the potential to generate photo-realistic virtual avatars from images. However, virtual avatars also need to be controllable even to a novel pose that may not have been observed. Traditional techniques, such as LBS, provide such a function; yet it usually requires a hand-designed body template, 3D scan data, and limited appearance models. On the other hand, neural representation has been shown to be powerful in representing visual details, but are under explored on deforming dynamic articulated actors. In this paper, we propose TAVA, a method to create T emplate-free Animatable Volumetric Actors, based on neural representations. We rely solely on multi-view data and a tracked skeleton to create a volumetric model of an actor, which can be animated at the test time given novel pose. Since TAVA does not require a body template, it is applicable to humans as well as other creatures such as animals. Furthermore, TAVA is designed such that it can recover accurate dense correspondences, making it amenable to content-creation and editing tasks. Through extensive experiments, we demonstrate that the proposed method generalizes well to novel poses as well as unseen views and showcase basic editing capabilities.