 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREVEAL: Relation-based Video Representation Learning for Video-Question-Answering
Apr 07, 2025Video-Question-Answering (VideoQA) comprises the capturing of complex visual relation changes over time, remaining a challenge even for advanced Video Language Models (VLM), i.a., because of the need to represent the visual content to a reasonably sized input for those models. To address this problem, we propose RElation-based Video rEpresentAtion Learning (REVEAL), a framework designed to capture visual relation information by encoding them into structured, decomposed representations. Specifically, inspired by spatiotemporal scene graphs, we propose to encode video sequences as sets of relation triplets in the form of (\textit{subject-predicate-object}) over time via their language embeddings. To this end, we extract explicit relations from video captions and introduce a Many-to-Many Noise Contrastive Estimation (MM-NCE) together with a Q-Former architecture to align an unordered set of video-derived queries with corresponding text-based relation descriptions. At inference, the resulting Q-former produces an efficient token representation that can serve as input to a VLM for VideoQA. We evaluate the proposed framework on five challenging benchmarks: NeXT-QA, Intent-QA, STAR, VLEP, and TVQA. It shows that the resulting query-based video representation is able to outperform global alignment-based CLS or patch token representations and achieves competitive results against state-of-the-art models, particularly on tasks requiring temporal reasoning and relation comprehension. The code and models will be publicly released.
Position: More Rigorous Software Engineering Would Improve Reproducibility in Machine Learning Research
Feb 02, 2025Experimental verification and falsification of scholarly work are part of the scientific method's core. To improve the Machine Learning (ML)-communities' ability to verify results from prior work, we argue for more robust software engineering. We estimate the adoption of common engineering best practices by examining repository links from all recently accepted International Conference on Machine Learning (ICML), International Conference on Learning Representations (ICLR) and Neural Information Processing Systems (NeurIPS) papers as well as ICML papers over time. Based on the results, we recommend how we, as a community, can improve reproducibility in ML-research.
Rethinking temporal self-similarity for repetitive action counting
Jul 12, 2024



Counting repetitive actions in long untrimmed videos is a challenging task that has many applications such as rehabilitation. State-of-the-art methods predict action counts by first generating a temporal self-similarity matrix (TSM) from the sampled frames and then feeding the matrix to a predictor network. The self-similarity matrix, however, is not an optimal input to a network since it discards too much information from the frame-wise embeddings. We thus rethink how a TSM can be utilized for counting repetitive actions and propose a framework that learns embeddings and predicts action start probabilities at full temporal resolution. The number of repeated actions is then inferred from the action start probabilities. In contrast to current approaches that have the TSM as an intermediate representation, we propose a novel loss based on a generated reference TSM, which enforces that the self-similarity of the learned frame-wise embeddings is consistent with the self-similarity of repeated actions. The proposed framework achieves state-of-the-art results on three datasets, i.e., RepCount, UCFRep, and Countix.
Wavelet Packet Power Spectrum Kullback-Leibler Divergence: A New Metric for Image Synthesis
Dec 23, 2023Current metrics for generative neural networks are biased towards low frequencies, specific generators, objects from the ImageNet dataset, and value texture more than shape. Many current quality metrics do not measure frequency information directly. In response, we propose a new frequency band-based quality metric, which opens a door into the frequency domain yet, at the same time, preserves spatial aspects of the data. Our metric works well even if the distributions we compare are far from ImageNet or have been produced by differing generator architectures. We verify the quality of our metric by sampling a broad selection of generative networks on a wide variety of data sets. A user study ensures our metric aligns with human perception. Furthermore, we show that frequency band guidance can improve the frequency domain fidelity of a current generative network.
Towards generalizing deep-audio fake detection networks
May 22, 2023Today's generative neural networks allow the creation of high-quality synthetic speech at scale. While we welcome the creative use of this new technology, we must also recognize the risks. As synthetic speech is abused for both monetary and identity theft, we require a broad set of deep fake identification tools. Furthermore, previous work reported a limited ability of deep classifiers to generalize to unseen audio generators. By leveraging the wavelet-packet and short-time Fourier transform, we train excellent lightweight detectors that generalize. We report improved results on an extension of the WaveFake dataset. To account for the rapid progress in the field, we additionally consider samples drawn from the novel Avocodo and BigVGAN networks.
Canonical convolutional neural networks
Jun 03, 2022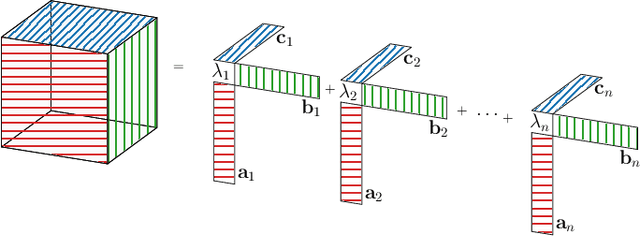


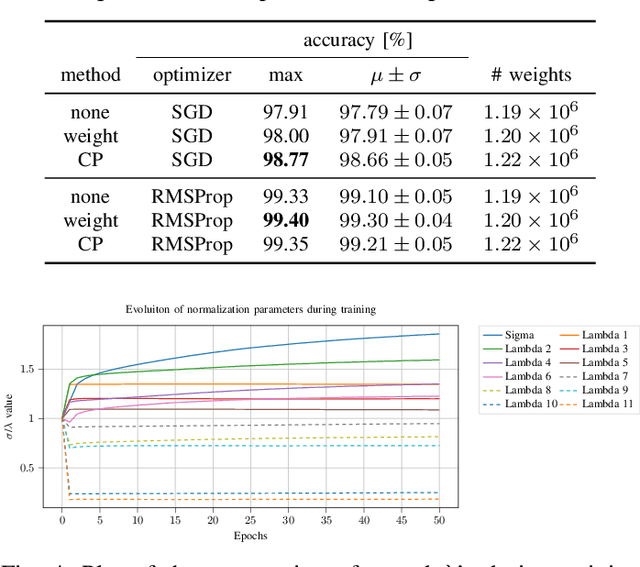
We introduce canonical weight normalization for convolutional neural networks. Inspired by the canonical tensor decomposition, we express the weight tensors in so-called canonical networks as scaled sums of outer vector products. In particular, we train network weights in the decomposed form, where scale weights are optimized separately for each mode. Additionally, similarly to weight normalization, we include a global scaling parameter. We study the initialization of the canonical form by running the power method and by drawing randomly from Gaussian or uniform distributions. Our results indicate that we can replace the power method with cheaper initializations drawn from standard distributions. The canonical re-parametrization leads to competitive normalization performance on the MNIST, CIFAR10, and SVHN data sets. Moreover, the formulation simplifies network compression. Once training has converged, the canonical form allows convenient model-compression by truncating the parameter sums.
Quantum Feature Selection
Mar 24, 2022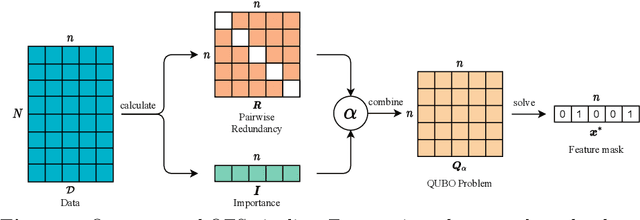


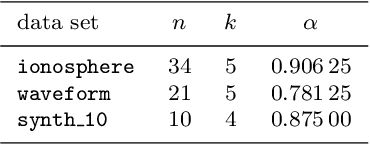
In machine learning, fewer features reduce model complexity. Carefully assessing the influence of each input feature on the model quality is therefore a crucial preprocessing step. We propose a novel feature selection algorithm based on a quadratic unconstrained binary optimization (QUBO) problem, which allows to select a specified number of features based on their importance and redundancy. In contrast to iterative or greedy methods, our direct approach yields higherquality solutions. QUBO problems are particularly interesting because they can be solved on quantum hardware. To evaluate our proposed algorithm, we conduct a series of numerical experiments using a classical computer, a quantum gate computer and a quantum annealer. Our evaluation compares our method to a range of standard methods on various benchmark datasets. We observe competitive performance.
On the effects of biased quantum random numbers on the initialization of artificial neural networks
Aug 30, 2021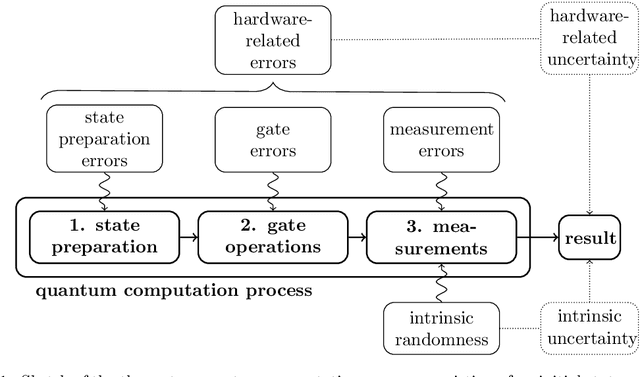
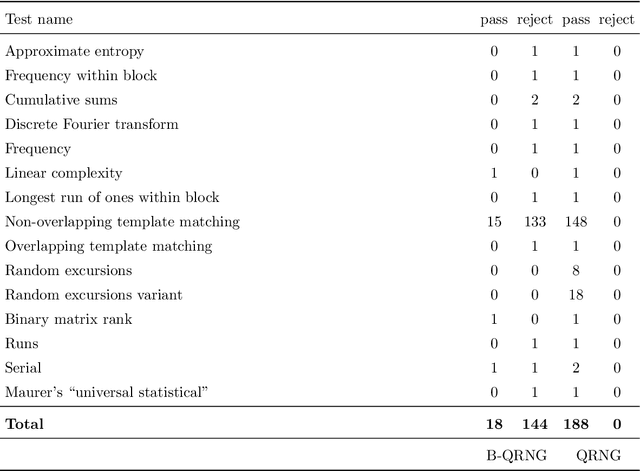
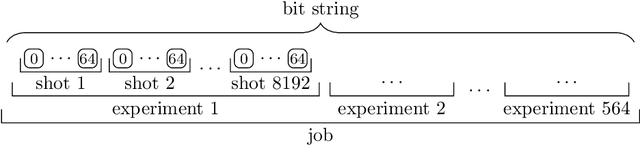
Recent advances in practical quantum computing have led to a variety of cloud-based quantum computing platforms that allow researchers to evaluate their algorithms on noisy intermediate-scale quantum (NISQ) devices. A common property of quantum computers is that they exhibit instances of true randomness as opposed to pseudo-randomness obtained from classical systems. Investigating the effects of such true quantum randomness in the context of machine learning is appealing, and recent results vaguely suggest that benefits can indeed be achieved from the use of quantum random numbers. To shed some more light on this topic, we empirically study the effects of hardware-biased quantum random numbers on the initialization of artificial neural network weights in numerical experiments. We find no statistically significant difference in comparison with unbiased quantum random numbers as well as biased and unbiased random numbers from a classical pseudo-random number generator. The quantum random numbers for our experiments are obtained from real quantum hardware.
Wavelet-Packet Powered Deepfake Image Detection
Jun 17, 2021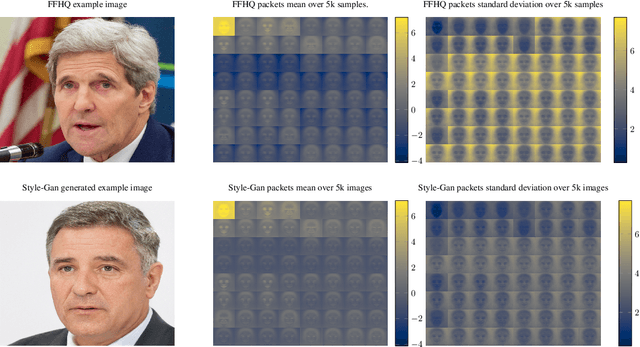
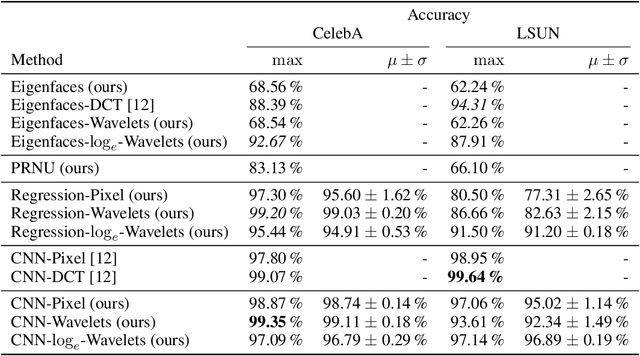

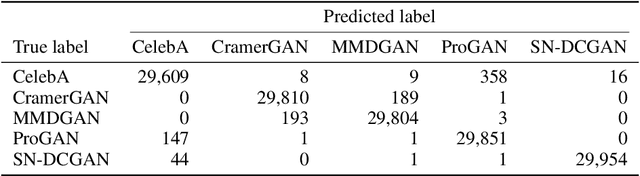
As neural networks become more able to generate realistic artificial images, they have the potential to improve movies, music, video games and make the internet an even more creative and inspiring place. Yet, at the same time, the latest technology potentially enables new digital ways to lie. In response, the need for a diverse and reliable toolbox arises to identify artificial images and other content. Previous work primarily relies on pixel-space CNN or the Fourier transform. To the best of our knowledge, wavelet-based gan analysis and detection methods have been absent thus far. This paper aims to fill this gap and describes a wavelet-based approach to gan-generated image analysis and detection. We evaluate our method on FFHQ, CelebA, and LSUN source identification problems and find improved or competitive performance.
Towards deep neural network compression via learnable wavelet transforms
Apr 20, 2020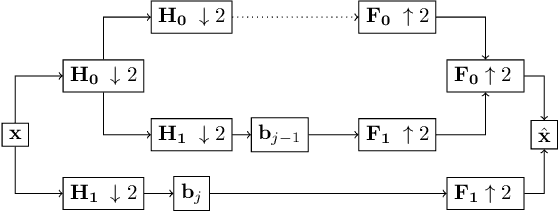
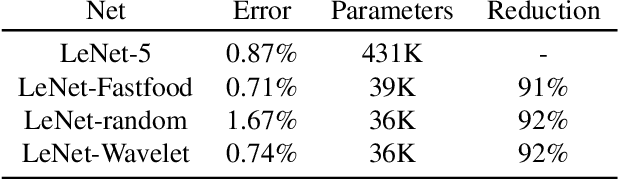
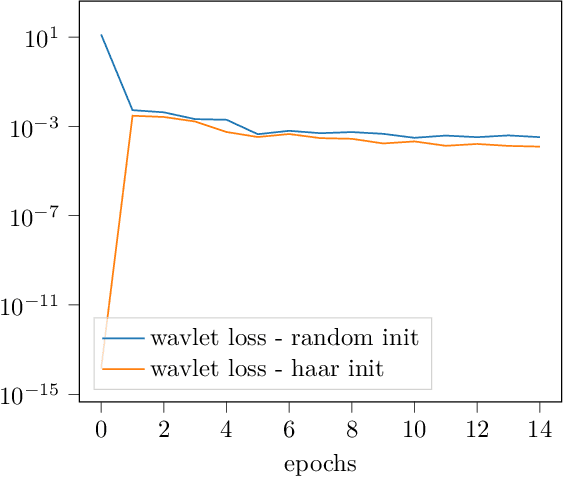
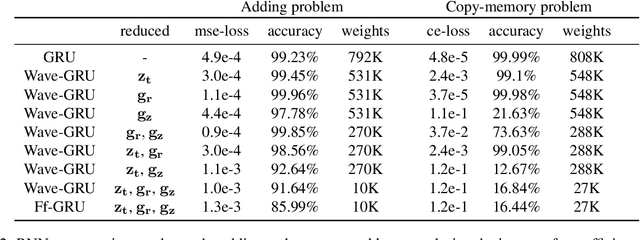
Wavelets are well known for data compression, yet have rarely been applied to the compression of neural networks. In this paper, we show how the fast wavelet transform can be applied to compress linear layers in neural networks. Linear layers still occupy a significant portion of the parameters in recurrent neural networks (RNNs). Through our method, we can learn both the wavelet bases as well as corresponding coefficients to efficiently represent the linear layers of RNNs. Our wavelet compressed RNNs have significantly fewer parameters yet still perform competitively with state-of-the-art on both synthetic and real-world RNN benchmarks. Wavelet optimization adds basis flexibility, without large numbers of extra weights