 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-Panda: Parameter-efficient Alignment for Encoder-free Video-Language Models
Dec 24, 2024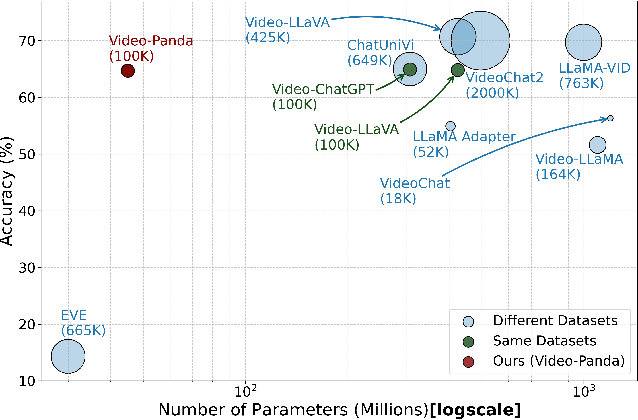
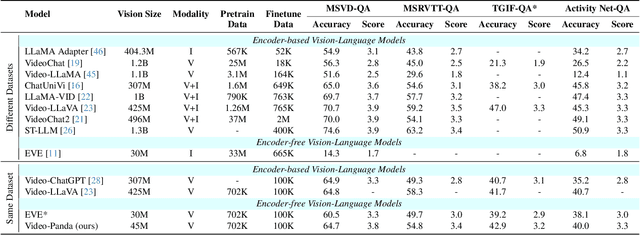
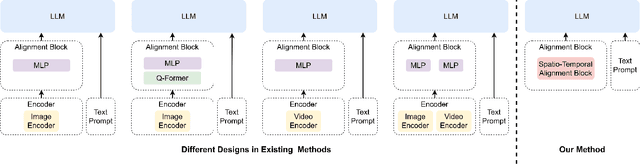
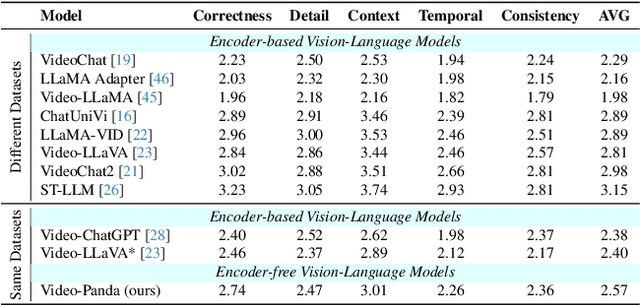
We present an efficient encoder-free approach for video-language understanding that achieves competitive performance while significantly reducing computational overhead. Current video-language models typically rely on heavyweight image encoders (300M-1.1B parameters) or video encoders (1B-1.4B parameters), creating a substantial computational burden when processing multi-frame videos. Our method introduces a novel Spatio-Temporal Alignment Block (STAB) that directly processes video inputs without requiring pre-trained encoders while using only 45M parameters for visual processing - at least a 6.5$\times$ reduction compared to traditional approaches. The STAB architecture combines Local Spatio-Temporal Encoding for fine-grained feature extraction, efficient spatial downsampling through learned attention and separate mechanisms for modeling frame-level and video-level relationships. Our model achieves comparable or superior performance to encoder-based approaches for open-ended video question answering on standard benchmarks. The fine-grained video question-answering evaluation demonstrates our model's effectiveness, outperforming the encoder-based approaches Video-ChatGPT and Video-LLaVA in key aspects like correctness and temporal understanding. Extensive ablation studies validate our architectural choices and demonstrate the effectiveness of our spatio-temporal modeling approach while achieving 3-4$\times$ faster processing speeds than previous methods. Code is available at \url{https://github.com/jh-yi/Video-Panda}.
MV-Match: Multi-View Matching for Domain-Adaptive Identification of Plant Nutrient Deficiencies
Sep 02, 2024



An early, non-invasive, and on-site detection of nutrient deficiencies is critical to enable timely actions to prevent major losses of crops caused by lack of nutrients. While acquiring labeled data is very expensive, collecting images from multiple views of a crop is straightforward. Despite its relevance for practical applications, unsupervised domain adaptation where multiple views are available for the labeled source domain as well as the unlabeled target domain is an unexplored research area. In this work, we thus propose an approach that leverages multiple camera views in the source and target domain for unsupervised domain adaptation. We evaluate the proposed approach on two nutrient deficiency datasets. The proposed method achieves state-of-the-art results on both datasets compared to other unsupervised domain adaptation methods. The dataset and source code are available at https://github.com/jh-yi/MV-Match.
Rethinking temporal self-similarity for repetitive action counting
Jul 12, 2024



Counting repetitive actions in long untrimmed videos is a challenging task that has many applications such as rehabilitation. State-of-the-art methods predict action counts by first generating a temporal self-similarity matrix (TSM) from the sampled frames and then feeding the matrix to a predictor network. The self-similarity matrix, however, is not an optimal input to a network since it discards too much information from the frame-wise embeddings. We thus rethink how a TSM can be utilized for counting repetitive actions and propose a framework that learns embeddings and predicts action start probabilities at full temporal resolution. The number of repeated actions is then inferred from the action start probabilities. In contrast to current approaches that have the TSM as an intermediate representation, we propose a novel loss based on a generated reference TSM, which enforces that the self-similarity of the learned frame-wise embeddings is consistent with the self-similarity of repeated actions. The proposed framework achieves state-of-the-art results on three datasets, i.e., RepCount, UCFRep, and Countix.
Scene Consistency Representation Learning for Video Scene Segmentation
May 11, 2022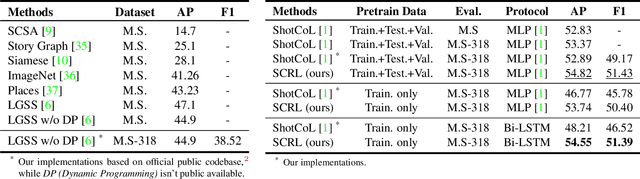
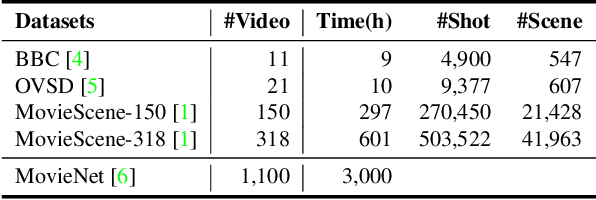
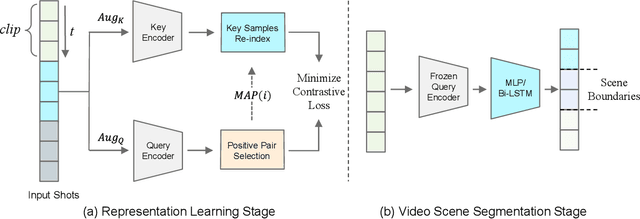
A long-term video, such as a movie or TV show, is composed of various scenes, each of which represents a series of shots sharing the same semantic story. Spotting the correct scene boundary from the long-term video is a challenging task, since a model must understand the storyline of the video to figure out where a scene starts and ends. To this end, we propose an effective Self-Supervised Learning (SSL) framework to learn better shot representations from unlabeled long-term videos. More specifically, we present an SSL scheme to achieve scene consistency, while exploring considerable data augmentation and shuffling methods to boost the model generalizability. Instead of explicitly learning the scene boundary features as in the previous methods, we introduce a vanilla temporal model with less inductive bias to verify the quality of the shot features. Our method achieves the state-of-the-art performance on the task of Video Scene Segmentation. Additionally, we suggest a more fair and reasonable benchmark to evaluate the performance of Video Scene Segmentation methods. The code is made available.
* Accepted to CVPR 2022
A Class-Incremental Learning Method Based on One Class Support Vector Machine
Mar 01, 2018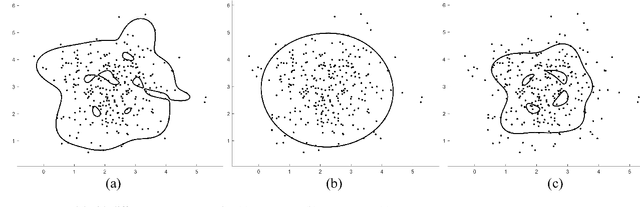

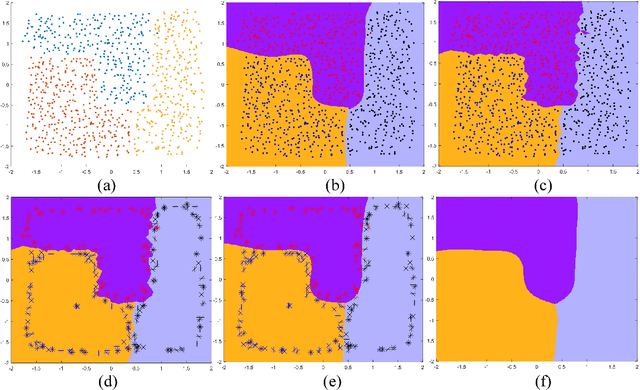
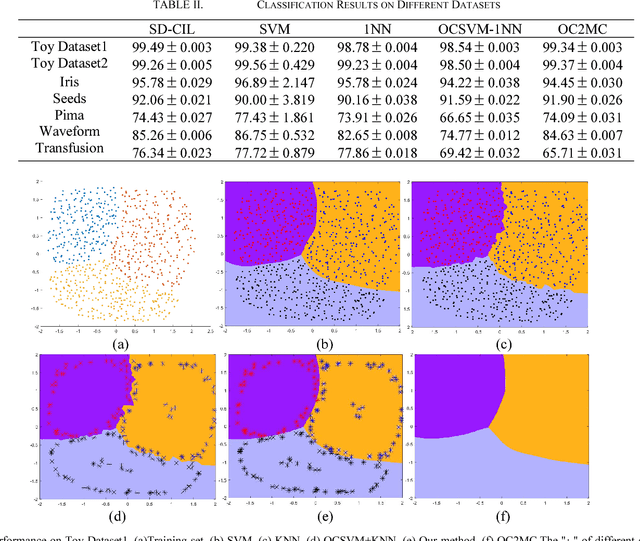
A method based on one class support vector machine (OCSVM) is proposed for class incremental learning. Several OCSVM models divide the input space into several parts. Then, the 1VS1 classifiers are constructed for the confuse part by using the support vectors. During the class incremental learning process, the OCSVM of the new class is trained at first. Then the support vectors of the old classes and the support vectors of the new class are reused to train 1VS1 classifiers for the confuse part. In order to bring more information to the certain support vectors, the support vectors are at the boundary of the distribution of samples as much as possible when the OCSVM is built. Compared with the traditional methods, the proposed method retains the original model and thus reduces memory consumption and training time cost. Various experiments on different datasets also verify the efficiency of the proposed method.
HSI-CNN: A Novel Convolution Neural Network for Hyperspectral Image
Feb 28, 2018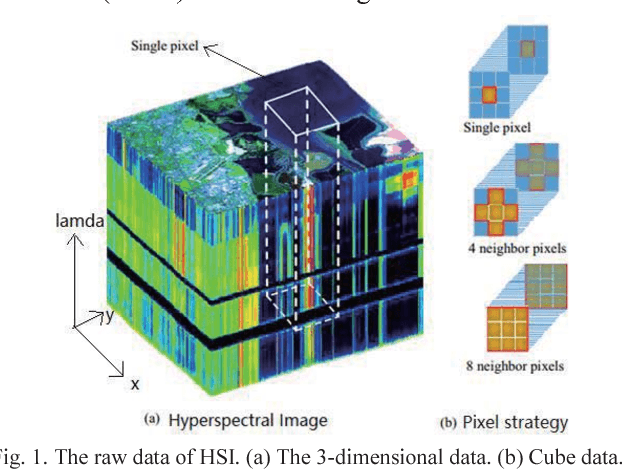
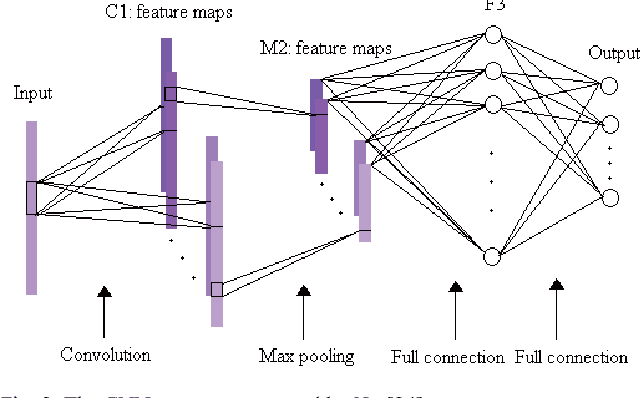
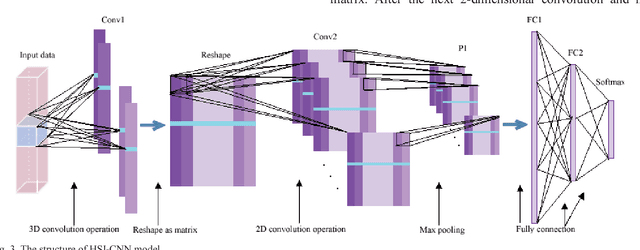

With the development of deep learning, the performance of hyperspectral image (HSI) classification has been greatly improved in recent years. The shortage of training samples has become a bottleneck for further improvement of performance. In this paper, we propose a novel convolutional neural network framework for the characteristics of hyperspectral image data, called HSI-CNN. Firstly, the spectral-spatial feature is extracted from a target pixel and its neighbors. Then, a number of one-dimensional feature maps, obtained by convolution operation on spectral-spatial features, are stacked into a two-dimensional matrix. Finally, the two-dimensional matrix considered as an image is fed into standard CNN. This is why we call it HSI-CNN. In addition, we also implements two depth network classification models, called HSI-CNN+XGBoost and HSI-CapsNet, in order to compare the performance of our framework. Experiments show that the performance of hyperspectral image classification is improved efficiently with HSI-CNN framework. We evaluate the model's performance using four popular HSI datasets, which are the Kennedy Space Center (KSC), Indian Pines (IP), Pavia University scene (PU) and Salinas scene (SA). As far as we concerned, HSI-CNN has got the state-of-art accuracy among all methods we have known on these datasets of 99.28%, 99.09%, 99.42%, 98.95% separately.