 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASPD: Unlocking Adaptive Serial-Parallel Decoding by Exploring Intrinsic Parallelism in LLMs
Aug 12, 2025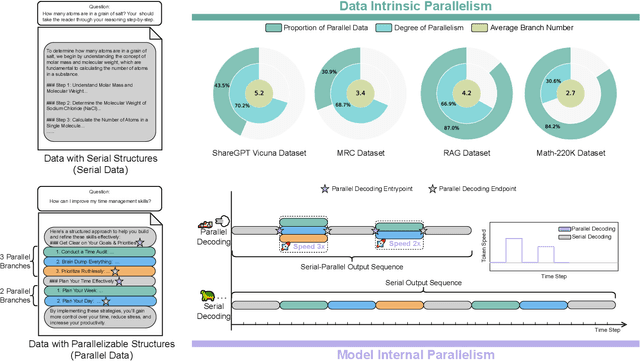
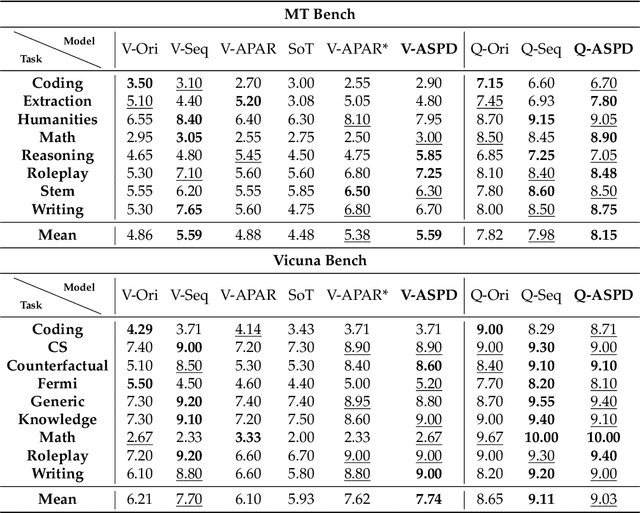
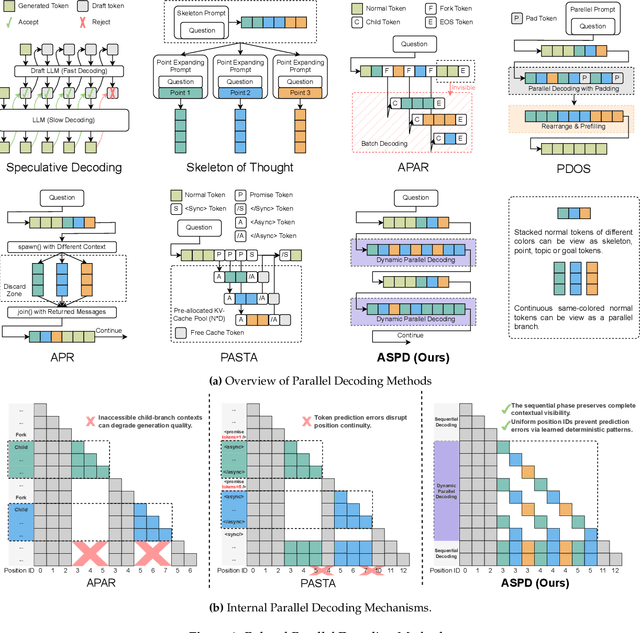
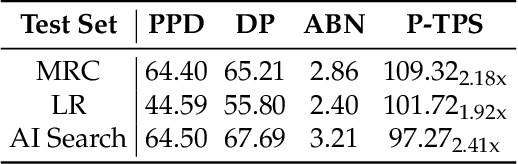
The increasing scale and complexity of large language models (LLMs) pose significant inference latency challenges, primarily due to their autoregressive decoding paradigm characterized by the sequential nature of next-token prediction. By re-examining the outputs of autoregressive models, we observed that some segments exhibit parallelizable structures, which we term intrinsic parallelism. Decoding each parallelizable branch simultaneously (i.e. parallel decoding) can significantly improve the overall inference speed of LLMs. In this paper, we propose an Adaptive Serial-Parallel Decoding (ASPD), which addresses two core challenges: automated construction of parallelizable data and efficient parallel decoding mechanism. More specifically, we introduce a non-invasive pipeline that automatically extracts and validates parallelizable structures from the responses of autoregressive models. To empower efficient adaptive serial-parallel decoding, we implement a Hybrid Decoding Engine which enables seamless transitions between serial and parallel decoding modes while maintaining a reusable KV cache, maximizing computational efficiency. Extensive evaluations across General Tasks, Retrieval-Augmented Generation, Mathematical Reasoning, demonstrate that ASPD achieves unprecedented performance in both effectiveness and efficiency. Notably, on Vicuna Bench, our method achieves up to 3.19x speedup (1.85x on average) while maintaining response quality within 1% difference compared to autoregressive models, realizing significant acceleration without compromising generation quality. Our framework sets a groundbreaking benchmark for efficient LLM parallel inference, paving the way for its deployment in latency-sensitive applications such as AI-powered customer service bots and answer retrieval engines.
Multimodal Label Relevance Ranking via Reinforcement Learning
Jul 18, 2024Conventional multi-label recognition methods often focus on label confidence, frequently overlooking the pivotal role of partial order relations consistent with human preference. To resolve these issues, we introduce a novel method for multimodal label relevance ranking, named Label Relevance Ranking with Proximal Policy Optimization (LR\textsuperscript{2}PPO), which effectively discerns partial order relations among labels. LR\textsuperscript{2}PPO first utilizes partial order pairs in the target domain to train a reward model, which aims to capture human preference intrinsic to the specific scenario. Furthermore, we meticulously design state representation and a policy loss tailored for ranking tasks, enabling LR\textsuperscript{2}PPO to boost the performance of label relevance ranking model and largely reduce the requirement of partial order annotation for transferring to new scenes. To assist in the evaluation of our approach and similar methods, we further propose a novel benchmark dataset, LRMovieNet, featuring multimodal labels and their corresponding partial order data. Extensive experiments demonstrate that our LR\textsuperscript{2}PPO algorithm achieves state-of-the-art performance, proving its effectiveness in addressing the multimodal label relevance ranking problem. Codes and the proposed LRMovieNet dataset are publicly available at \url{https://github.com/ChazzyGordon/LR2PPO}.
Fingerprint Presentation Attack Detector Using Global-Local Model
Feb 20, 2024The vulnerability of automated fingerprint recognition systems (AFRSs) to presentation attacks (PAs) promotes the vigorous development of PA detection (PAD) technology. However, PAD methods have been limited by information loss and poor generalization ability, resulting in new PA materials and fingerprint sensors. This paper thus proposes a global-local model-based PAD (RTK-PAD) method to overcome those limitations to some extent. The proposed method consists of three modules, called: 1) the global module; 2) the local module; and 3) the rethinking module. By adopting the cut-out-based global module, a global spoofness score predicted from nonlocal features of the entire fingerprint images can be achieved. While by using the texture in-painting-based local module, a local spoofness score predicted from fingerprint patches is obtained. The two modules are not independent but connected through our proposed rethinking module by localizing two discriminative patches for the local module based on the global spoofness score. Finally, the fusion spoofness score by averaging the global and local spoofness scores is used for PAD. Our experimental results evaluated on LivDet 2017 show that the proposed RTK-PAD can achieve an average classification error (ACE) of 2.28% and a true detection rate (TDR) of 91.19% when the false detection rate (FDR) equals 1.0%, which significantly outperformed the state-of-the-art methods by $\sim$10% in terms of TDR (91.19% versus 80.74%).
* This paper was accepted by IEEE Transactions on Cybernetics. Current version is updated with minor revisions on introduction and related works
Text-Guided 3D Face Synthesis -- From Generation to Editing
Dec 01, 2023


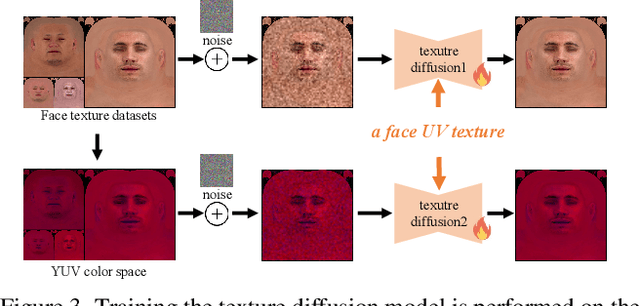
Text-guided 3D face synthesis has achieved remarkable results by leveraging text-to-image (T2I) diffusion models. However, most existing works focus solely on the direct generation, ignoring the editing, restricting them from synthesizing customized 3D faces through iterative adjustments. In this paper, we propose a unified text-guided framework from face generation to editing. In the generation stage, we propose a geometry-texture decoupled generation to mitigate the loss of geometric details caused by coupling. Besides, decoupling enables us to utilize the generated geometry as a condition for texture generation, yielding highly geometry-texture aligned results. We further employ a fine-tuned texture diffusion model to enhance texture quality in both RGB and YUV space. In the editing stage, we first employ a pre-trained diffusion model to update facial geometry or texture based on the texts. To enable sequential editing, we introduce a UV domain consistency preservation regularization, preventing unintentional changes to irrelevant facial attributes. Besides, we propose a self-guided consistency weight strategy to improve editing efficacy while preserving consistency. Through comprehensive experiments, we showcase our method's superiority in face synthesis. Project page: https://faceg2e.github.io/.
NeFII: Inverse Rendering for Reflectance Decomposition with Near-Field Indirect Illumination
Mar 29, 2023



Inverse rendering methods aim to estimate geometry, materials and illumination from multi-view RGB images. In order to achieve better decomposition, recent approaches attempt to model indirect illuminations reflected from different materials via Spherical Gaussians (SG), which, however, tends to blur the high-frequency reflection details. In this paper, we propose an end-to-end inverse rendering pipeline that decomposes materials and illumination from multi-view images, while considering near-field indirect illumination. In a nutshell, we introduce the Monte Carlo sampling based path tracing and cache the indirect illumination as neural radiance, enabling a physics-faithful and easy-to-optimize inverse rendering method. To enhance efficiency and practicality, we leverage SG to represent the smooth environment illuminations and apply importance sampling techniques. To supervise indirect illuminations from unobserved directions, we develop a novel radiance consistency constraint between implicit neural radiance and path tracing results of unobserved rays along with the joint optimization of materials and illuminations, thus significantly improving the decomposition performance. Extensive experiments demonstrate that our method outperforms the state-of-the-art on multiple synthetic and real datasets, especially in terms of inter-reflection decomposition.
Collaborative Noisy Label Cleaner: Learning Scene-aware Trailers for Multi-modal Highlight Detection in Movies
Mar 26, 2023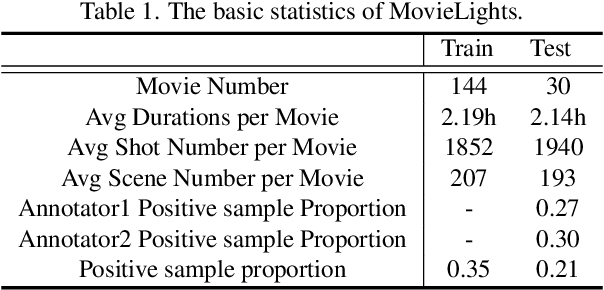
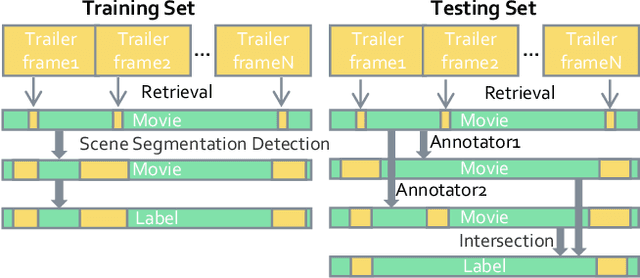
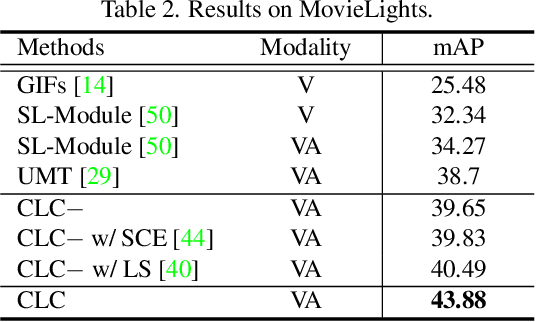
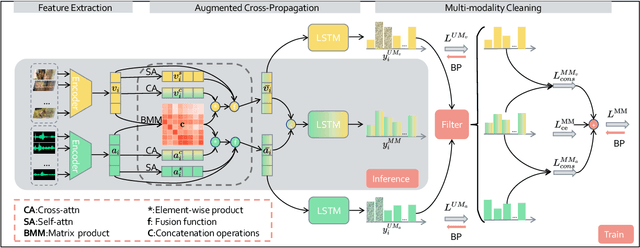
Movie highlights stand out of the screenplay for efficient browsing and play a crucial role on social media platforms. Based on existing efforts, this work has two observations: (1) For different annotators, labeling highlight has uncertainty, which leads to inaccurate and time-consuming annotations. (2) Besides previous supervised or unsupervised settings, some existing video corpora can be useful, e.g., trailers, but they are often noisy and incomplete to cover the full highlights. In this work, we study a more practical and promising setting, i.e., reformulating highlight detection as "learning with noisy labels". This setting does not require time-consuming manual annotations and can fully utilize existing abundant video corpora. First, based on movie trailers, we leverage scene segmentation to obtain complete shots, which are regarded as noisy labels. Then, we propose a Collaborative noisy Label Cleaner (CLC) framework to learn from noisy highlight moments. CLC consists of two modules: augmented cross-propagation (ACP) and multi-modality cleaning (MMC). The former aims to exploit the closely related audio-visual signals and fuse them to learn unified multi-modal representations. The latter aims to achieve cleaner highlight labels by observing the changes in losses among different modalities. To verify the effectiveness of CLC, we further collect a large-scale highlight dataset named MovieLights. Comprehensive experiments on MovieLights and YouTube Highlights datasets demonstrate the effectiveness of our approach. Code has been made available at: https://github.com/TencentYoutuResearch/HighlightDetection-CLC
Improving GAN Training via Feature Space Shrinkage
Mar 02, 2023Due to the outstanding capability for data generation, Generative Adversarial Networks (GANs) have attracted considerable attention in unsupervised learning. However, training GANs is difficult, since the training distribution is dynamic for the discriminator, leading to unstable image representation. In this paper, we address the problem of training GANs from a novel perspective, \emph{i.e.,} robust image classification. Motivated by studies on robust image representation, we propose a simple yet effective module, namely AdaptiveMix, for GANs, which shrinks the regions of training data in the image representation space of the discriminator. Considering it is intractable to directly bound feature space, we propose to construct hard samples and narrow down the feature distance between hard and easy samples. The hard samples are constructed by mixing a pair of training images. We evaluate the effectiveness of our AdaptiveMix with widely-used and state-of-the-art GAN architectures. The evaluation results demonstrate that our AdaptiveMix can facilitate the training of GANs and effectively improve the image quality of generated samples. We also show that our AdaptiveMix can be further applied to image classification and Out-Of-Distribution (OOD) detection tasks, by equipping it with state-of-the-art methods. Extensive experiments on seven publicly available datasets show that our method effectively boosts the performance of baselines. The code is publicly available at https://github.com/WentianZhang-ML/AdaptiveMix.
Decoupled Mixup for Generalized Visual Recognition
Oct 26, 2022Convolutional neural networks (CNN) have demonstrated remarkable performance when the training and testing data are from the same distribution. However, such trained CNN models often largely degrade on testing data which is unseen and Out-Of-the-Distribution (OOD). To address this issue, we propose a novel "Decoupled-Mixup" method to train CNN models for OOD visual recognition. Different from previous work combining pairs of images homogeneously, our method decouples each image into discriminative and noise-prone regions, and then heterogeneously combines these regions of image pairs to train CNN models. Since the observation is that noise-prone regions such as textural and clutter backgrounds are adverse to the generalization ability of CNN models during training, we enhance features from discriminative regions and suppress noise-prone ones when combining an image pair. To further improve the generalization ability of trained models, we propose to disentangle discriminative and noise-prone regions in frequency-based and context-based fashions. Experiment results show the high generalization performance of our method on testing data that are composed of unseen contexts, where our method achieves 85.76\% top-1 accuracy in Track-1 and 79.92\% in Track-2 in the NICO Challenge. The source code is available at https://github.com/HaozheLiu-ST/NICOChallenge-OOD-Classification.
See Finer, See More: Implicit Modality Alignment for Text-based Person Retrieval
Aug 26, 2022
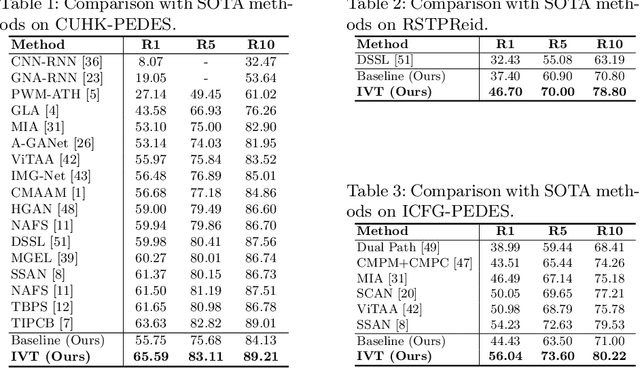
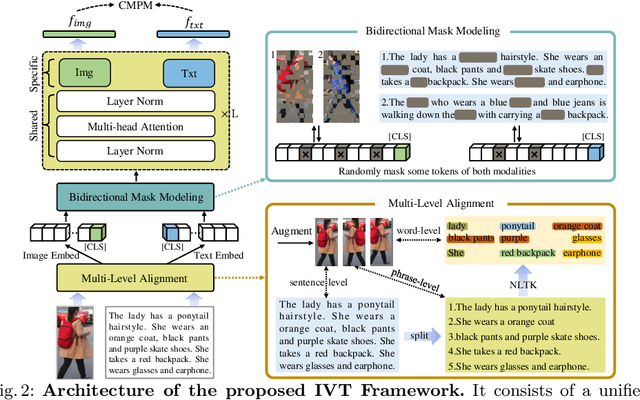

Text-based person retrieval aims to find the query person based on a textual description. The key is to learn a common latent space mapping between visual-textual modalities. To achieve this goal, existing works employ segmentation to obtain explicitly cross-modal alignments or utilize attention to explore salient alignments. These methods have two shortcomings: 1) Labeling cross-modal alignments are time-consuming. 2) Attention methods can explore salient cross-modal alignments but may ignore some subtle and valuable pairs. To relieve these issues, we introduce an Implicit Visual-Textual (IVT) framework for text-based person retrieval. Different from previous models, IVT utilizes a single network to learn representation for both modalities, which contributes to the visual-textual interaction. To explore the fine-grained alignment, we further propose two implicit semantic alignment paradigms: multi-level alignment (MLA) and bidirectional mask modeling (BMM). The MLA module explores finer matching at sentence, phrase, and word levels, while the BMM module aims to mine \textbf{more} semantic alignments between visual and textual modalities. Extensive experiments are carried out to evaluate the proposed IVT on public datasets, i.e., CUHK-PEDES, RSTPReID, and ICFG-PEDES. Even without explicit body part alignment, our approach still achieves state-of-the-art performance. Code is available at: https://github.com/TencentYoutuResearch/PersonRetrieval-IVT.
Combating Mode Collapse in GANs via Manifold Entropy Estimation
Aug 25, 2022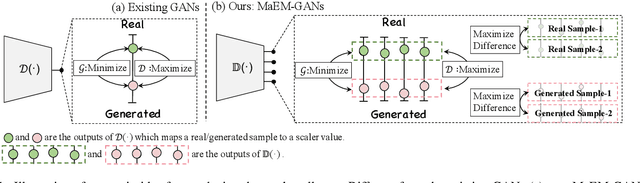
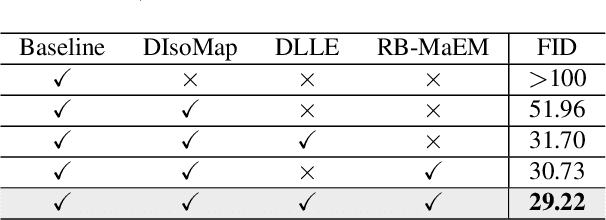
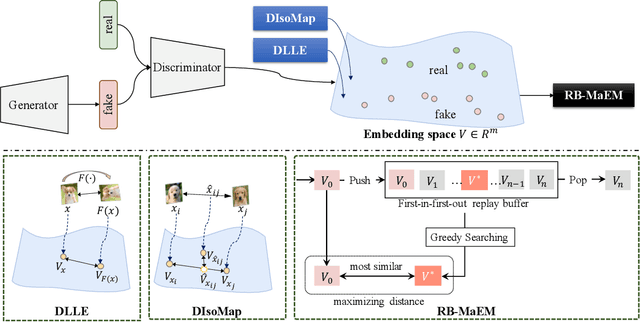
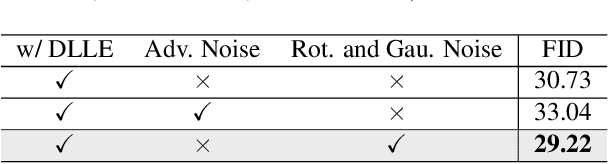
Generative Adversarial Networks (GANs) have shown compelling results in various tasks and applications in recent years. However, mode collapse remains a critical problem in GANs. In this paper, we propose a novel training pipeline to address the mode collapse issue of GANs. Different from existing methods, we propose to generalize the discriminator as feature embedding, and maximize the entropy of distributions in the embedding space learned by the discriminator. Specifically, two regularization terms, i.e.Deep Local Linear Embedding (DLLE) and Deep Isometric feature Mapping (DIsoMap), are designed to encourage the discriminator to learn the structural information embedded in the data, such that the embedding space learned by the discriminator can be well formed. Based on the well-learned embedding space supported by the discriminator, a non-parametric entropy estimator is designed to efficiently maximize the entropy of embedding vectors, playing as an approximation of maximizing the entropy of the generated distribution. Through improving the discriminator and maximizing the distance of the most similar samples in the embedding space, our pipeline effectively reduces the mode collapse without sacrificing the quality of generated samples. Extensive experimental results show the effectiveness of our method which outperforms the GAN baseline, MaF-GAN on CelebA (9.13 vs. 12.43 in FID) and surpasses the recent state-of-the-art energy-based model on the ANIME-FACE dataset (2.80 vs. 2.26 in Inception score).