 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombating Mode Collapse in GANs via Manifold Entropy Estimation
Paper and Code
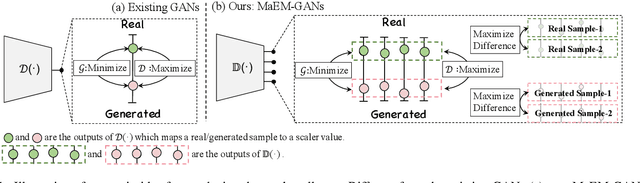
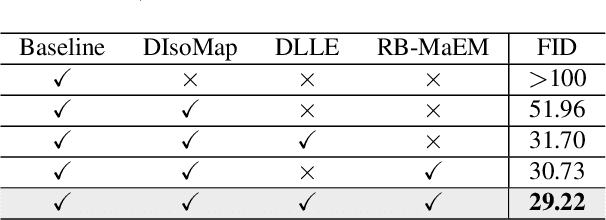
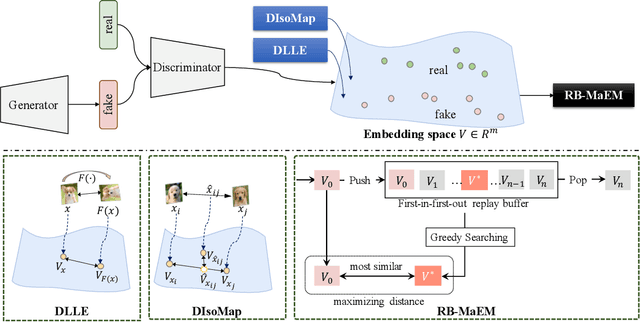
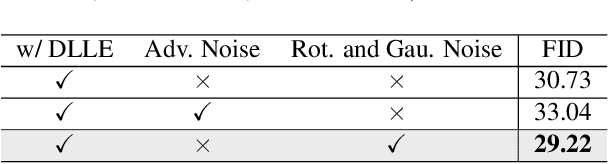
Generative Adversarial Networks (GANs) have shown compelling results in various tasks and applications in recent years. However, mode collapse remains a critical problem in GANs. In this paper, we propose a novel training pipeline to address the mode collapse issue of GANs. Different from existing methods, we propose to generalize the discriminator as feature embedding, and maximize the entropy of distributions in the embedding space learned by the discriminator. Specifically, two regularization terms, i.e.Deep Local Linear Embedding (DLLE) and Deep Isometric feature Mapping (DIsoMap), are designed to encourage the discriminator to learn the structural information embedded in the data, such that the embedding space learned by the discriminator can be well formed. Based on the well-learned embedding space supported by the discriminator, a non-parametric entropy estimator is designed to efficiently maximize the entropy of embedding vectors, playing as an approximation of maximizing the entropy of the generated distribution. Through improving the discriminator and maximizing the distance of the most similar samples in the embedding space, our pipeline effectively reduces the mode collapse without sacrificing the quality of generated samples. Extensive experimental results show the effectiveness of our method which outperforms the GAN baseline, MaF-GAN on CelebA (9.13 vs. 12.43 in FID) and surpasses the recent state-of-the-art energy-based model on the ANIME-FACE dataset (2.80 vs. 2.26 in Inception score).