 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified and Dynamic Graph for Temporal Character Grouping in Long Videos
Aug 29, 2023

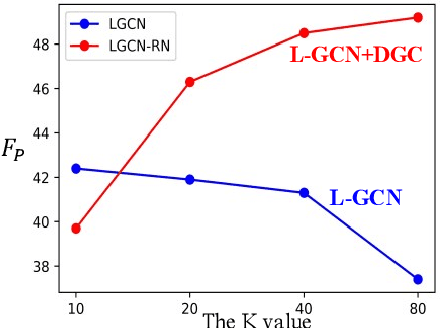
Video temporal character grouping locates appearing moments of major characters within a video according to their identities. To this end, recent works have evolved from unsupervised clustering to graph-based supervised clustering. However, graph methods are built upon the premise of fixed affinity graphs, bringing many inexact connections. Besides, they extract multi-modal features with kinds of models, which are unfriendly to deployment. In this paper, we present a unified and dynamic graph (UniDG) framework for temporal character grouping. This is accomplished firstly by a unified representation network that learns representations of multiple modalities within the same space and still preserves the modality's uniqueness simultaneously. Secondly, we present a dynamic graph clustering where the neighbors of different quantities are dynamically constructed for each node via a cyclic matching strategy, leading to a more reliable affinity graph. Thirdly, a progressive association method is introduced to exploit spatial and temporal contexts among different modalities, allowing multi-modal clustering results to be well fused. As current datasets only provide pre-extracted features, we evaluate our UniDG method on a collected dataset named MTCG, which contains each character's appearing clips of face and body and speaking voice tracks. We also evaluate our key components on existing clustering and retrieval datasets to verify the generalization ability. Experimental results manifest that our method can achieve promising results and outperform several state-of-the-art approaches.
D3G: Exploring Gaussian Prior for Temporal Sentence Grounding with Glance Annotation
Aug 08, 2023



Temporal sentence grounding (TSG) aims to locate a specific moment from an untrimmed video with a given natural language query. Recently, weakly supervised methods still have a large performance gap compared to fully supervised ones, while the latter requires laborious timestamp annotations. In this study, we aim to reduce the annotation cost yet keep competitive performance for TSG task compared to fully supervised ones. To achieve this goal, we investigate a recently proposed glance-supervised temporal sentence grounding task, which requires only single frame annotation (referred to as glance annotation) for each query. Under this setup, we propose a Dynamic Gaussian prior based Grounding framework with Glance annotation (D3G), which consists of a Semantic Alignment Group Contrastive Learning module (SA-GCL) and a Dynamic Gaussian prior Adjustment module (DGA). Specifically, SA-GCL samples reliable positive moments from a 2D temporal map via jointly leveraging Gaussian prior and semantic consistency, which contributes to aligning the positive sentence-moment pairs in the joint embedding space. Moreover, to alleviate the annotation bias resulting from glance annotation and model complex queries consisting of multiple events, we propose the DGA module, which adjusts the distribution dynamically to approximate the ground truth of target moments. Extensive experiments on three challenging benchmarks verify the effectiveness of the proposed D3G. It outperforms the state-of-the-art weakly supervised methods by a large margin and narrows the performance gap compared to fully supervised methods. Code is available at https://github.com/solicucu/D3G.
Collaborative Noisy Label Cleaner: Learning Scene-aware Trailers for Multi-modal Highlight Detection in Movies
Mar 26, 2023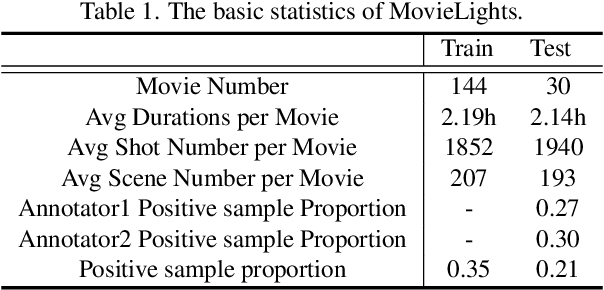
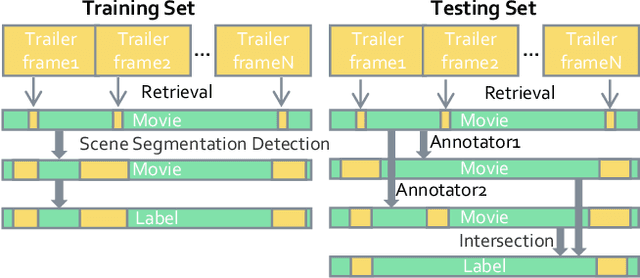
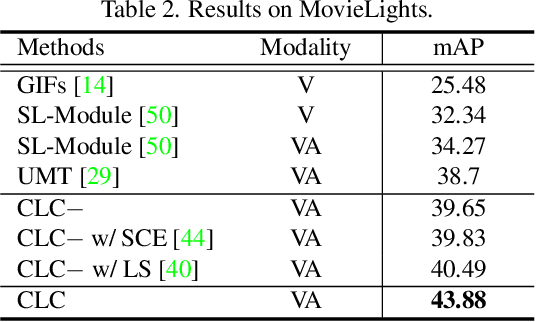
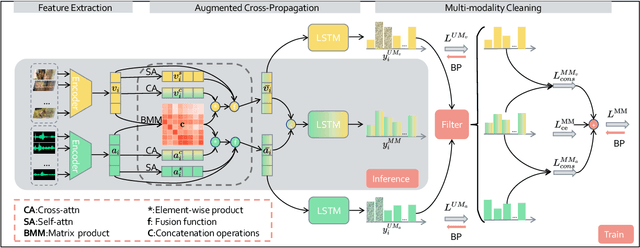
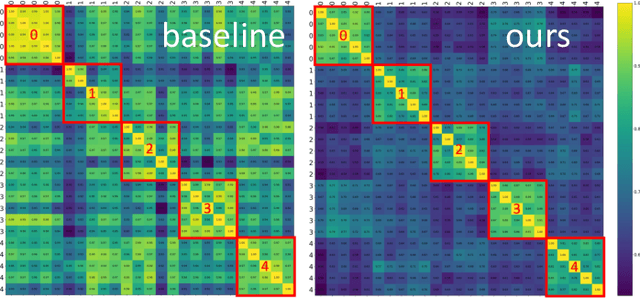
Movie highlights stand out of the screenplay for efficient browsing and play a crucial role on social media platforms. Based on existing efforts, this work has two observations: (1) For different annotators, labeling highlight has uncertainty, which leads to inaccurate and time-consuming annotations. (2) Besides previous supervised or unsupervised settings, some existing video corpora can be useful, e.g., trailers, but they are often noisy and incomplete to cover the full highlights. In this work, we study a more practical and promising setting, i.e., reformulating highlight detection as "learning with noisy labels". This setting does not require time-consuming manual annotations and can fully utilize existing abundant video corpora. First, based on movie trailers, we leverage scene segmentation to obtain complete shots, which are regarded as noisy labels. Then, we propose a Collaborative noisy Label Cleaner (CLC) framework to learn from noisy highlight moments. CLC consists of two modules: augmented cross-propagation (ACP) and multi-modality cleaning (MMC). The former aims to exploit the closely related audio-visual signals and fuse them to learn unified multi-modal representations. The latter aims to achieve cleaner highlight labels by observing the changes in losses among different modalities. To verify the effectiveness of CLC, we further collect a large-scale highlight dataset named MovieLights. Comprehensive experiments on MovieLights and YouTube Highlights datasets demonstrate the effectiveness of our approach. Code has been made available at: https://github.com/TencentYoutuResearch/HighlightDetection-CLC
Few-shot Forgery Detection via Guided Adversarial Interpolation
Apr 12, 2022
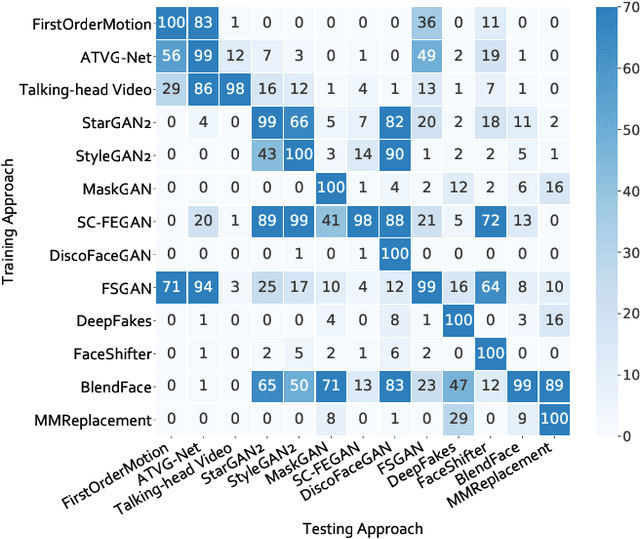
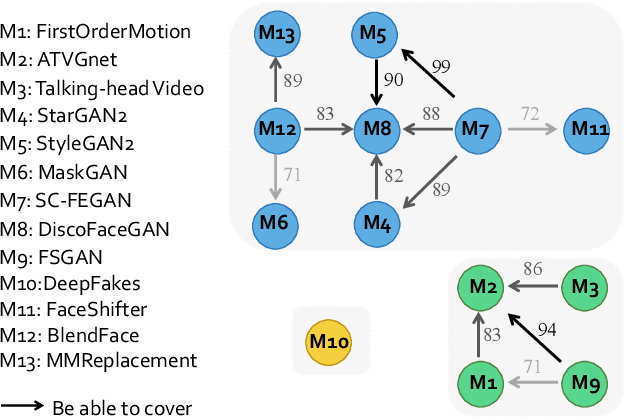
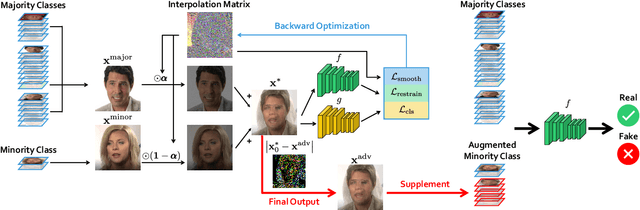
Realistic visual media synthesis is becoming a critical societal issue with the surge of face manipulation models; new forgery approaches emerge at an unprecedented pace. Unfortunately, existing forgery detection methods suffer significant performance drops when applied to novel forgery approaches. In this work, we address the few-shot forgery detection problem by designing a comprehensive benchmark based on coverage analysis among various forgery approaches, and proposing Guided Adversarial Interpolation (GAI). Our key insight is that there exist transferable distribution characteristics among different forgery approaches with the majority and minority classes. Specifically, we enhance the discriminative ability against novel forgery approaches via adversarially interpolating the artifacts of the minority samples to the majority samples under the guidance of a teacher network. Unlike the standard re-balancing method which usually results in over-fitting to minority classes, our method simultaneously takes account of the diversity of majority information as well as the significance of minority information. Extensive experiments demonstrate that our GAI achieves state-of-the-art performances on the established few-shot forgery detection benchmark. Notably, our method is also validated to be robust to choices of majority and minority forgery approaches.
ForgeryNet: A Versatile Benchmark for Comprehensive Forgery Analysis
Mar 09, 2021
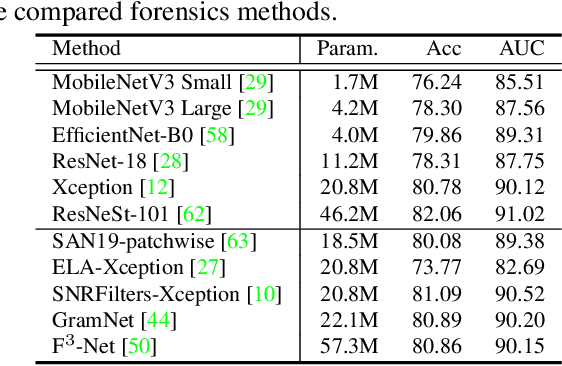


The rapid progress of photorealistic synthesis techniques has reached at a critical point where the boundary between real and manipulated images starts to blur. Thus, benchmarking and advancing digital forgery analysis have become a pressing issue. However, existing face forgery datasets either have limited diversity or only support coarse-grained analysis. To counter this emerging threat, we construct the ForgeryNet dataset, an extremely large face forgery dataset with unified annotations in image- and video-level data across four tasks: 1) Image Forgery Classification, including two-way (real / fake), three-way (real / fake with identity-replaced forgery approaches / fake with identity-remained forgery approaches), and n-way (real and 15 respective forgery approaches) classification. 2) Spatial Forgery Localization, which segments the manipulated area of fake images compared to their corresponding source real images. 3) Video Forgery Classification, which re-defines the video-level forgery classification with manipulated frames in random positions. This task is important because attackers in real world are free to manipulate any target frame. and 4) Temporal Forgery Localization, to localize the temporal segments which are manipulated. ForgeryNet is by far the largest publicly available deep face forgery dataset in terms of data-scale (2.9 million images, 221,247 videos), manipulations (7 image-level approaches, 8 video-level approaches), perturbations (36 independent and more mixed perturbations) and annotations (6.3 million classification labels, 2.9 million manipulated area annotations and 221,247 temporal forgery segment labels). We perform extensive benchmarking and studies of existing face forensics methods and obtain several valuable observations.