 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified and Dynamic Graph for Temporal Character Grouping in Long Videos
Paper and Code
Aug 29, 2023

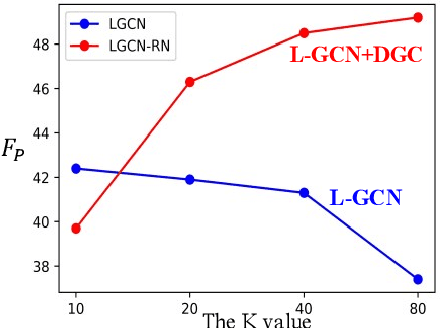
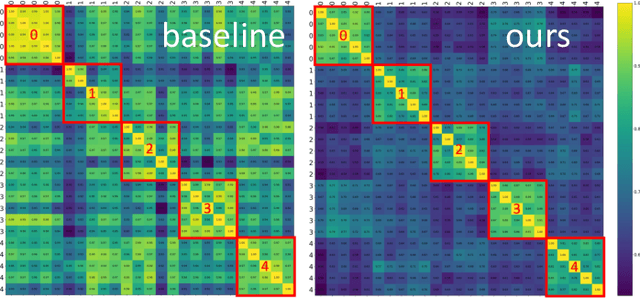
Video temporal character grouping locates appearing moments of major characters within a video according to their identities. To this end, recent works have evolved from unsupervised clustering to graph-based supervised clustering. However, graph methods are built upon the premise of fixed affinity graphs, bringing many inexact connections. Besides, they extract multi-modal features with kinds of models, which are unfriendly to deployment. In this paper, we present a unified and dynamic graph (UniDG) framework for temporal character grouping. This is accomplished firstly by a unified representation network that learns representations of multiple modalities within the same space and still preserves the modality's uniqueness simultaneously. Secondly, we present a dynamic graph clustering where the neighbors of different quantities are dynamically constructed for each node via a cyclic matching strategy, leading to a more reliable affinity graph. Thirdly, a progressive association method is introduced to exploit spatial and temporal contexts among different modalities, allowing multi-modal clustering results to be well fused. As current datasets only provide pre-extracted features, we evaluate our UniDG method on a collected dataset named MTCG, which contains each character's appearing clips of face and body and speaking voice tracks. We also evaluate our key components on existing clustering and retrieval datasets to verify the generalization ability. Experimental results manifest that our method can achieve promising results and outperform several state-of-the-art approaches.