 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaPROBE: Alpha Mining via Principled Retrieval and On-graph biased evolution
Feb 12, 2026Extracting signals through alpha factor mining is a fundamental challenge in quantitative finance. Existing automated methods primarily follow two paradigms: Decoupled Factor Generation, which treats factor discovery as isolated events, and Iterative Factor Evolution, which focuses on local parent-child refinements. However, both paradigms lack a global structural view, often treating factor pools as unstructured collections or fragmented chains, which leads to redundant search and limited diversity. To address these limitations, we introduce AlphaPROBE (Alpha Mining via Principled Retrieval and On-graph Biased Evolution), a framework that reframes alpha mining as the strategic navigation of a Directed Acyclic Graph (DAG). By modeling factors as nodes and evolutionary links as edges, AlphaPROBE treats the factor pool as a dynamic, interconnected ecosystem. The framework consists of two core components: a Bayesian Factor Retriever that identifies high-potential seeds by balancing exploitation and exploration through a posterior probability model, and a DAG-aware Factor Generator that leverages the full ancestral trace of factors to produce context-aware, nonredundant optimizations. Extensive experiments on three major Chinese stock market datasets against 8 competitive baselines demonstrate that AlphaPROBE significantly gains enhanced performance in predictive accuracy, return stability and training efficiency. Our results confirm that leveraging global evolutionary topology is essential for efficient and robust automated alpha discovery. We have open-sourced our implementation at https://github.com/gta0804/AlphaPROBE.
MEME: Modeling the Evolutionary Modes of Financial Markets
Feb 12, 2026LLMs have demonstrated significant potential in quantitative finance by processing vast unstructured data to emulate human-like analytical workflows. However, current LLM-based methods primarily follow either an Asset-Centric paradigm focused on individual stock prediction or a Market-Centric approach for portfolio allocation, often remaining agnostic to the underlying reasoning that drives market movements. In this paper, we propose a Logic-Oriented perspective, modeling the financial market as a dynamic, evolutionary ecosystem of competing investment narratives, termed Modes of Thought. To operationalize this view, we introduce MEME (Modeling the Evolutionary Modes of Financial Markets), designed to reconstruct market dynamics through the lens of evolving logics. MEME employs a multi-agent extraction module to transform noisy data into high-fidelity Investment Arguments and utilizes Gaussian Mixture Modeling to uncover latent consensus within a semantic space. To model semantic drift among different market conditions, we also implement a temporal evaluation and alignment mechanism to track the lifecycle and historical profitability of these modes. By prioritizing enduring market wisdom over transient anomalies, MEME ensures that portfolio construction is guided by robust reasoning. Extensive experiments on three heterogeneous Chinese stock pools from 2023 to 2025 demonstrate that MEME consistently outperforms seven SOTA baselines. Further ablation studies, sensitivity analysis, lifecycle case study and cost analysis validate MEME's capacity to identify and adapt to the evolving consensus of financial markets. Our implementation can be found at https://github.com/gta0804/MEME.
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
MASS: Multi-Agent Simulation Scaling for Portfolio Construction
May 15, 2025LLM-based multi-agent has gained significant attention for their potential in simulation and enhancing performance. However, existing works are limited to pure simulations or are constrained by predefined workflows, restricting their applicability and effectiveness. In this paper, we introduce the Multi-Agent Scaling Simulation (MASS) for portfolio construction. MASS achieves stable and continuous excess returns by progressively increasing the number of agents for large-scale simulations to gain a superior understanding of the market and optimizing agent distribution end-to-end through a reverse optimization process, rather than relying on a fixed workflow. We demonstrate its superiority through performance experiments, ablation studies, backtesting experiments, experiments on updated data and stock pools, scaling experiments, parameter sensitivity experiments, and visualization experiments, conducted in comparison with 6 state-of-the-art baselines on 3 challenging A-share stock pools. We expect the paradigm established by MASS to expand to other tasks with similar characteristics. The implementation of MASS has been open-sourced at https://github.com/gta0804/MASS.
Multimodal Label Relevance Ranking via Reinforcement Learning
Jul 18, 2024Conventional multi-label recognition methods often focus on label confidence, frequently overlooking the pivotal role of partial order relations consistent with human preference. To resolve these issues, we introduce a novel method for multimodal label relevance ranking, named Label Relevance Ranking with Proximal Policy Optimization (LR\textsuperscript{2}PPO), which effectively discerns partial order relations among labels. LR\textsuperscript{2}PPO first utilizes partial order pairs in the target domain to train a reward model, which aims to capture human preference intrinsic to the specific scenario. Furthermore, we meticulously design state representation and a policy loss tailored for ranking tasks, enabling LR\textsuperscript{2}PPO to boost the performance of label relevance ranking model and largely reduce the requirement of partial order annotation for transferring to new scenes. To assist in the evaluation of our approach and similar methods, we further propose a novel benchmark dataset, LRMovieNet, featuring multimodal labels and their corresponding partial order data. Extensive experiments demonstrate that our LR\textsuperscript{2}PPO algorithm achieves state-of-the-art performance, proving its effectiveness in addressing the multimodal label relevance ranking problem. Codes and the proposed LRMovieNet dataset are publicly available at \url{https://github.com/ChazzyGordon/LR2PPO}.
MMEvalPro: Calibrating Multimodal Benchmarks Towards Trustworthy and Efficient Evaluation
Jun 29, 2024



Large Multimodal Models (LMMs) exhibit impressive cross-modal understanding and reasoning abilities, often assessed through multiple-choice questions (MCQs) that include an image, a question, and several options. However, many benchmarks used for such evaluations suffer from systematic biases. Remarkably, Large Language Models (LLMs) without any visual perception capabilities achieve non-trivial performance, undermining the credibility of these evaluations. To address this issue while maintaining the efficiency of MCQ evaluations, we propose MMEvalPro, a benchmark designed to avoid Type-I errors through a trilogy evaluation pipeline and more rigorous metrics. For each original question from existing benchmarks, human annotators augment it by creating one perception question and one knowledge anchor question through a meticulous annotation process. MMEvalPro comprises $2,138$ question triplets, totaling $6,414$ distinct questions. Two-thirds of these questions are manually labeled by human experts, while the rest are sourced from existing benchmarks (MMMU, ScienceQA, and MathVista). Compared with the existing benchmarks, our experiments with the latest LLMs and LMMs demonstrate that MMEvalPro is more challenging (the best LMM lags behind human performance by $31.73\%$, compared to an average gap of $8.03\%$ in previous benchmarks) and more trustworthy (the best LLM trails the best LMM by $23.09\%$, whereas the gap for previous benchmarks is just $14.64\%$). Our in-depth analysis explains the reason for the large performance gap and justifies the trustworthiness of evaluation, underscoring its significant potential for advancing future research.
Unified and Dynamic Graph for Temporal Character Grouping in Long Videos
Aug 29, 2023

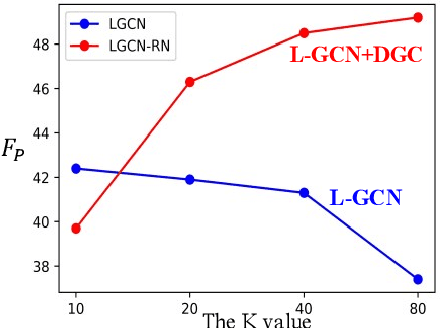
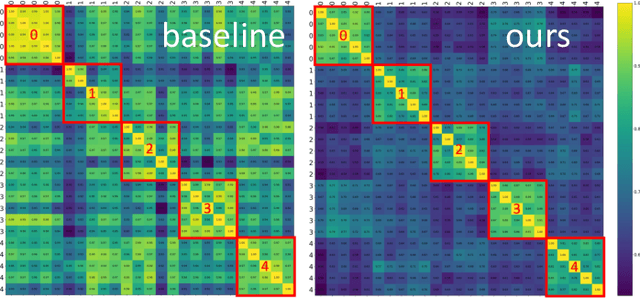
Video temporal character grouping locates appearing moments of major characters within a video according to their identities. To this end, recent works have evolved from unsupervised clustering to graph-based supervised clustering. However, graph methods are built upon the premise of fixed affinity graphs, bringing many inexact connections. Besides, they extract multi-modal features with kinds of models, which are unfriendly to deployment. In this paper, we present a unified and dynamic graph (UniDG) framework for temporal character grouping. This is accomplished firstly by a unified representation network that learns representations of multiple modalities within the same space and still preserves the modality's uniqueness simultaneously. Secondly, we present a dynamic graph clustering where the neighbors of different quantities are dynamically constructed for each node via a cyclic matching strategy, leading to a more reliable affinity graph. Thirdly, a progressive association method is introduced to exploit spatial and temporal contexts among different modalities, allowing multi-modal clustering results to be well fused. As current datasets only provide pre-extracted features, we evaluate our UniDG method on a collected dataset named MTCG, which contains each character's appearing clips of face and body and speaking voice tracks. We also evaluate our key components on existing clustering and retrieval datasets to verify the generalization ability. Experimental results manifest that our method can achieve promising results and outperform several state-of-the-art approaches.
D3G: Exploring Gaussian Prior for Temporal Sentence Grounding with Glance Annotation
Aug 08, 2023



Temporal sentence grounding (TSG) aims to locate a specific moment from an untrimmed video with a given natural language query. Recently, weakly supervised methods still have a large performance gap compared to fully supervised ones, while the latter requires laborious timestamp annotations. In this study, we aim to reduce the annotation cost yet keep competitive performance for TSG task compared to fully supervised ones. To achieve this goal, we investigate a recently proposed glance-supervised temporal sentence grounding task, which requires only single frame annotation (referred to as glance annotation) for each query. Under this setup, we propose a Dynamic Gaussian prior based Grounding framework with Glance annotation (D3G), which consists of a Semantic Alignment Group Contrastive Learning module (SA-GCL) and a Dynamic Gaussian prior Adjustment module (DGA). Specifically, SA-GCL samples reliable positive moments from a 2D temporal map via jointly leveraging Gaussian prior and semantic consistency, which contributes to aligning the positive sentence-moment pairs in the joint embedding space. Moreover, to alleviate the annotation bias resulting from glance annotation and model complex queries consisting of multiple events, we propose the DGA module, which adjusts the distribution dynamically to approximate the ground truth of target moments. Extensive experiments on three challenging benchmarks verify the effectiveness of the proposed D3G. It outperforms the state-of-the-art weakly supervised methods by a large margin and narrows the performance gap compared to fully supervised methods. Code is available at https://github.com/solicucu/D3G.
VLMAE: Vision-Language Masked Autoencoder
Aug 19, 2022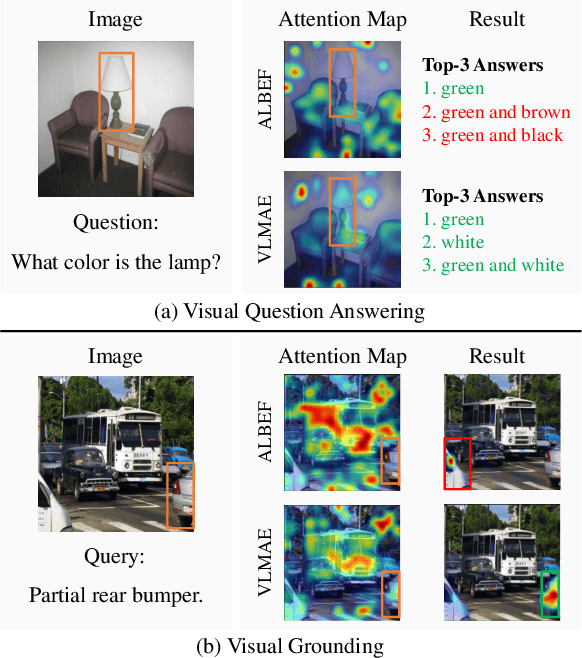
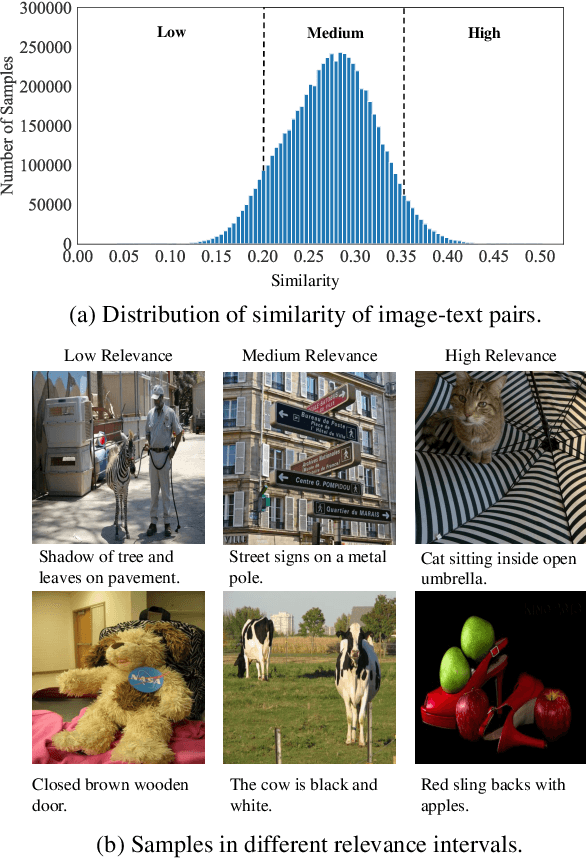
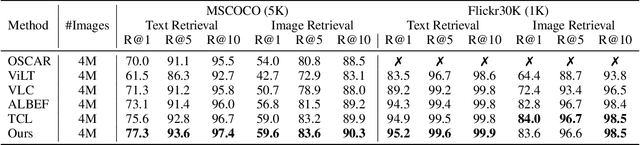
Image and language modeling is of crucial importance for vision-language pre-training (VLP), which aims to learn multi-modal representations from large-scale paired image-text data. However, we observe that most existing VLP methods focus on modeling the interactions between image and text features while neglecting the information disparity between image and text, thus suffering from focal bias. To address this problem, we propose a vision-language masked autoencoder framework (VLMAE). VLMAE employs visual generative learning, facilitating the model to acquire fine-grained and unbiased features. Unlike the previous works, VLMAE pays attention to almost all critical patches in an image, providing more comprehensive understanding. Extensive experiments demonstrate that VLMAE achieves better performance in various vision-language downstream tasks, including visual question answering, image-text retrieval and visual grounding, even with up to 20% pre-training speedup.
Exploiting Feature Diversity for Make-up Temporal Video Grounding
Aug 12, 2022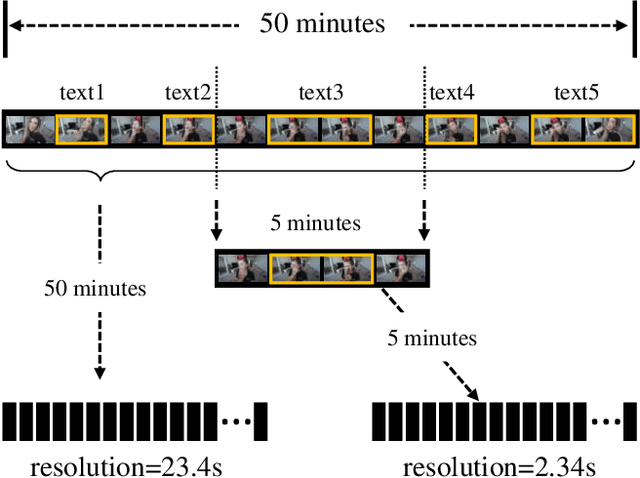
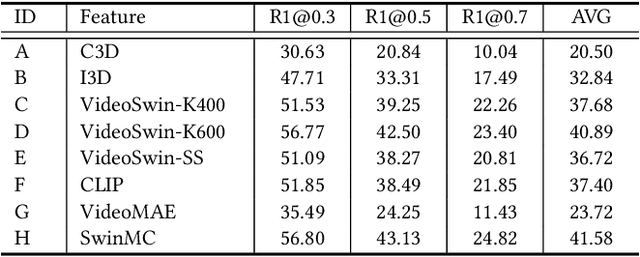
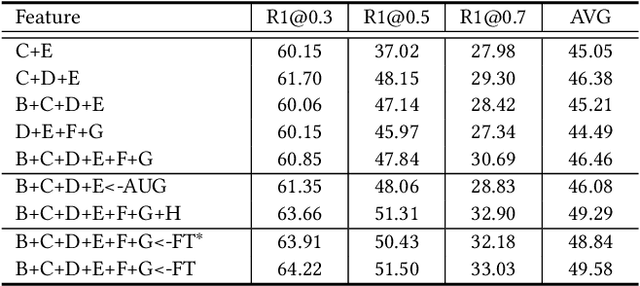

This technical report presents the 3rd winning solution for MTVG, a new task introduced in the 4-th Person in Context (PIC) Challenge at ACM MM 2022. MTVG aims at localizing the temporal boundary of the step in an untrimmed video based on a textual description. The biggest challenge of this task is the fi ne-grained video-text semantics of make-up steps. However, current methods mainly extract video features using action-based pre-trained models. As actions are more coarse-grained than make-up steps, action-based features are not sufficient to provide fi ne-grained cues. To address this issue,we propose to achieve fi ne-grained representation via exploiting feature diversities. Specifically, we proposed a series of methods from feature extraction, network optimization, to model ensemble. As a result, we achieved 3rd place in the MTVG competition.