 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLMAE: Vision-Language Masked Autoencoder
Paper and Code
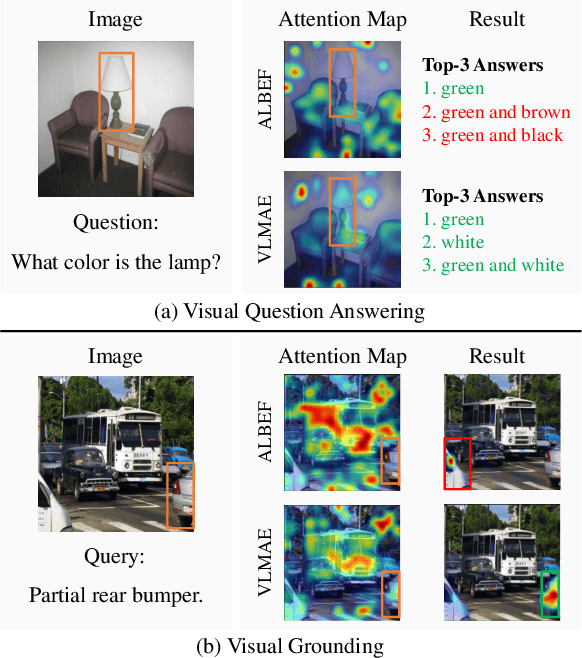
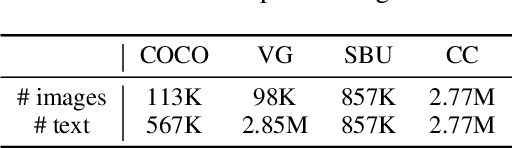
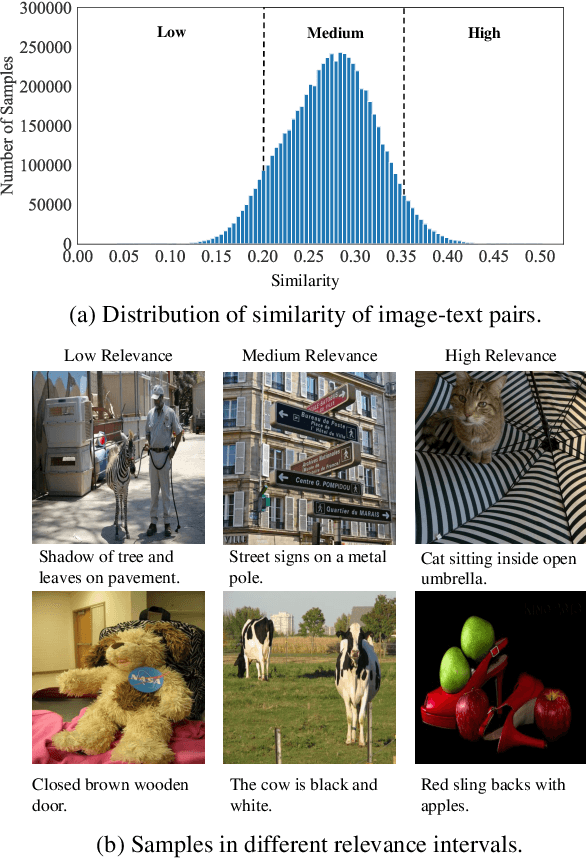
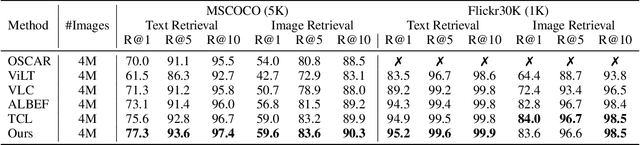
Image and language modeling is of crucial importance for vision-language pre-training (VLP), which aims to learn multi-modal representations from large-scale paired image-text data. However, we observe that most existing VLP methods focus on modeling the interactions between image and text features while neglecting the information disparity between image and text, thus suffering from focal bias. To address this problem, we propose a vision-language masked autoencoder framework (VLMAE). VLMAE employs visual generative learning, facilitating the model to acquire fine-grained and unbiased features. Unlike the previous works, VLMAE pays attention to almost all critical patches in an image, providing more comprehensive understanding. Extensive experiments demonstrate that VLMAE achieves better performance in various vision-language downstream tasks, including visual question answering, image-text retrieval and visual grounding, even with up to 20% pre-training speedup.