 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Vocabulary Multi-Label Classification via Multi-modal Knowledge Transfer
Paper and Code
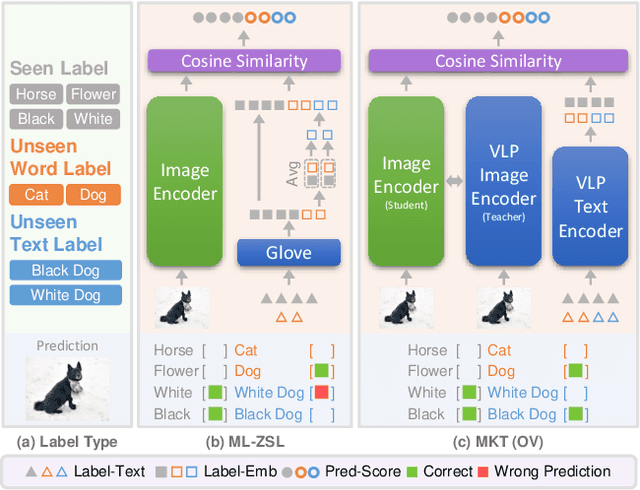
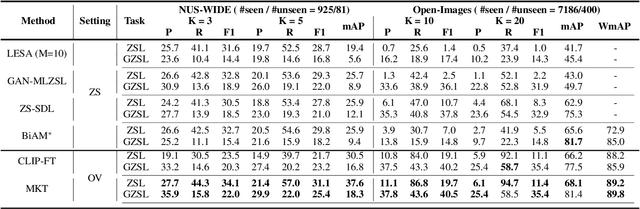
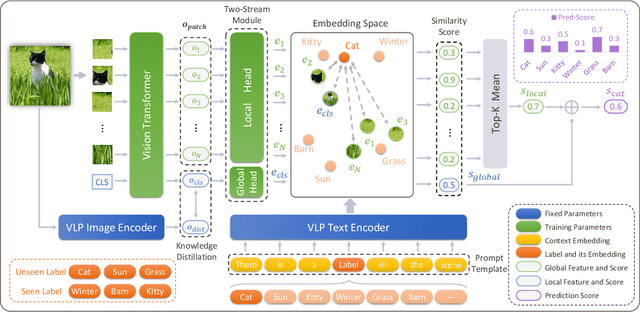
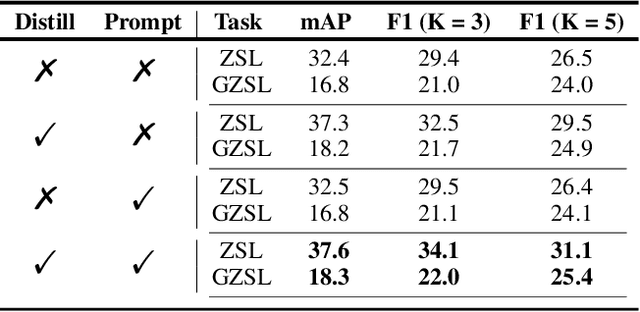
Real-world recognition system often encounters a plenty of unseen labels in practice. To identify such unseen labels, multi-label zero-shot learning (ML-ZSL) focuses on transferring knowledge by a pre-trained textual label embedding (e.g., GloVe). However, such methods only exploit singlemodal knowledge from a language model, while ignoring the rich semantic information inherent in image-text pairs. Instead, recently developed open-vocabulary (OV) based methods succeed in exploiting such information of image-text pairs in object detection, and achieve impressive performance. Inspired by the success of OV-based methods, we propose a novel open-vocabulary framework, named multimodal knowledge transfer (MKT), for multi-label classification. Specifically, our method exploits multi-modal knowledge of image-text pairs based on a vision and language pretraining (VLP) model. To facilitate transferring the imagetext matching ability of VLP model, knowledge distillation is used to guarantee the consistency of image and label embeddings, along with prompt tuning to further update the label embeddings. To further recognize multiple objects, a simple but effective two-stream module is developed to capture both local and global features. Extensive experimental results show that our method significantly outperforms state-of-theart methods on public benchmark datasets. Code will be available at https://github.com/seanhe97/MKT.