 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKlingAvatar 2.0 Technical Report
Dec 15, 2025Avatar video generation models have achieved remarkable progress in recent years. However, prior work exhibits limited efficiency in generating long-duration high-resolution videos, suffering from temporal drifting, quality degradation, and weak prompt following as video length increases. To address these challenges, we propose KlingAvatar 2.0, a spatio-temporal cascade framework that performs upscaling in both spatial resolution and temporal dimension. The framework first generates low-resolution blueprint video keyframes that capture global semantics and motion, and then refines them into high-resolution, temporally coherent sub-clips using a first-last frame strategy, while retaining smooth temporal transitions in long-form videos. To enhance cross-modal instruction fusion and alignment in extended videos, we introduce a Co-Reasoning Director composed of three modality-specific large language model (LLM) experts. These experts reason about modality priorities and infer underlying user intent, converting inputs into detailed storylines through multi-turn dialogue. A Negative Director further refines negative prompts to improve instruction alignment. Building on these components, we extend the framework to support ID-specific multi-character control. Extensive experiments demonstrate that our model effectively addresses the challenges of efficient, multimodally aligned long-form high-resolution video generation, delivering enhanced visual clarity, realistic lip-teeth rendering with accurate lip synchronization, strong identity preservation, and coherent multimodal instruction following.
Aquarius: A Family of Industry-Level Video Generation Models for Marketing Scenarios
May 14, 2025



This report introduces Aquarius, a family of industry-level video generation models for marketing scenarios designed for thousands-xPU clusters and models with hundreds of billions of parameters. Leveraging efficient engineering architecture and algorithmic innovation, Aquarius demonstrates exceptional performance in high-fidelity, multi-aspect-ratio, and long-duration video synthesis. By disclosing the framework's design details, we aim to demystify industrial-scale video generation systems and catalyze advancements in the generative video community. The Aquarius framework consists of five components: Distributed Graph and Video Data Processing Pipeline: Manages tens of thousands of CPUs and thousands of xPUs via automated task distribution, enabling efficient video data processing. Additionally, we are about to open-source the entire data processing framework named "Aquarius-Datapipe". Model Architectures for Different Scales: Include a Single-DiT architecture for 2B models and a Multimodal-DiT architecture for 13.4B models, supporting multi-aspect ratios, multi-resolution, and multi-duration video generation. High-Performance infrastructure designed for video generation model training: Incorporating hybrid parallelism and fine-grained memory optimization strategies, this infrastructure achieves 36% MFU at large scale. Multi-xPU Parallel Inference Acceleration: Utilizes diffusion cache and attention optimization to achieve a 2.35x inference speedup. Multiple marketing-scenarios applications: Including image-to-video, text-to-video (avatar), video inpainting and video personalization, among others. More downstream applications and multi-dimensional evaluation metrics will be added in the upcoming version updates.
Towards Prompt-robust Face Privacy Protection via Adversarial Decoupling Augmentation Framework
May 06, 2023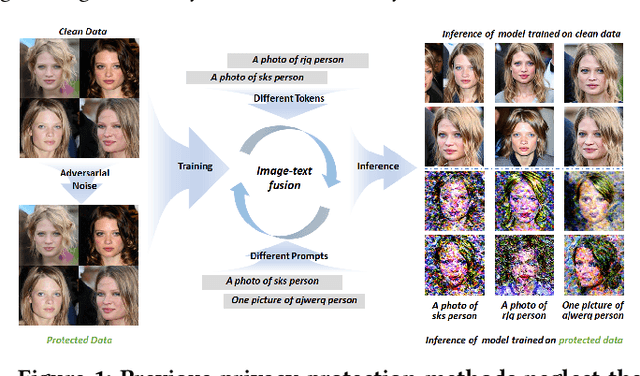
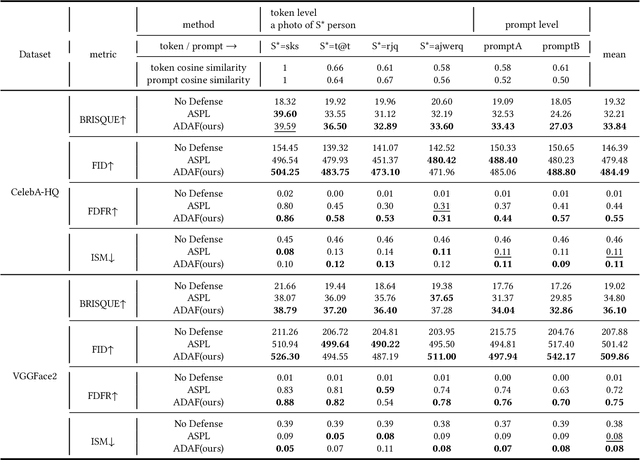
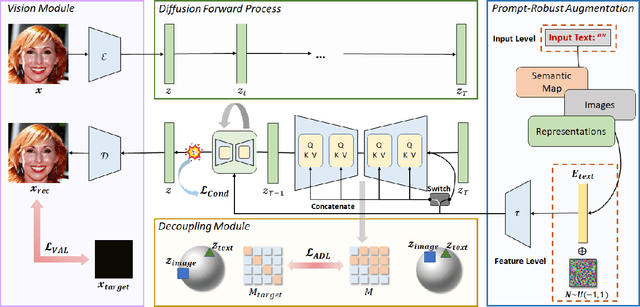
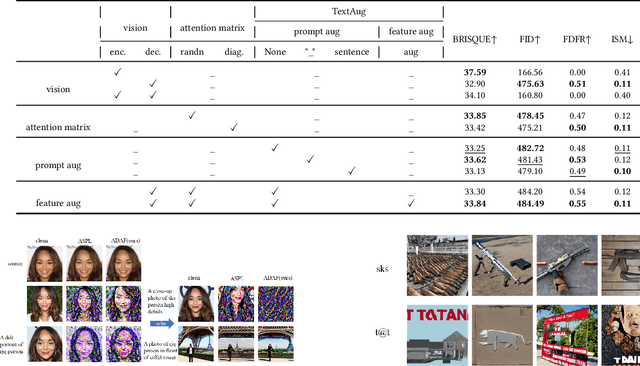
Denoising diffusion models have shown remarkable potential in various generation tasks. The open-source large-scale text-to-image model, Stable Diffusion, becomes prevalent as it can generate realistic artistic or facial images with personalization through fine-tuning on a limited number of new samples. However, this has raised privacy concerns as adversaries can acquire facial images online and fine-tune text-to-image models for malicious editing, leading to baseless scandals, defamation, and disruption to victims' lives. Prior research efforts have focused on deriving adversarial loss from conventional training processes for facial privacy protection through adversarial perturbations. However, existing algorithms face two issues: 1) they neglect the image-text fusion module, which is the vital module of text-to-image diffusion models, and 2) their defensive performance is unstable against different attacker prompts. In this paper, we propose the Adversarial Decoupling Augmentation Framework (ADAF), addressing these issues by targeting the image-text fusion module to enhance the defensive performance of facial privacy protection algorithms. ADAF introduces multi-level text-related augmentations for defense stability against various attacker prompts. Concretely, considering the vision, text, and common unit space, we propose Vision-Adversarial Loss, Prompt-Robust Augmentation, and Attention-Decoupling Loss. Extensive experiments on CelebA-HQ and VGGFace2 demonstrate ADAF's promising performance, surpassing existing algorithms.
Artificial Intelligence Security Competition (AISC)
Dec 07, 2022



The security of artificial intelligence (AI) is an important research area towards safe, reliable, and trustworthy AI systems. To accelerate the research on AI security, the Artificial Intelligence Security Competition (AISC) was organized by the Zhongguancun Laboratory, China Industrial Control Systems Cyber Emergency Response Team, Institute for Artificial Intelligence, Tsinghua University, and RealAI as part of the Zhongguancun International Frontier Technology Innovation Competition (https://www.zgc-aisc.com/en). The competition consists of three tracks, including Deepfake Security Competition, Autonomous Driving Security Competition, and Face Recognition Security Competition. This report will introduce the competition rules of these three tracks and the solutions of top-ranking teams in each track.
Adaptive Perturbation Generation for Multiple Backdoors Detection
Sep 13, 2022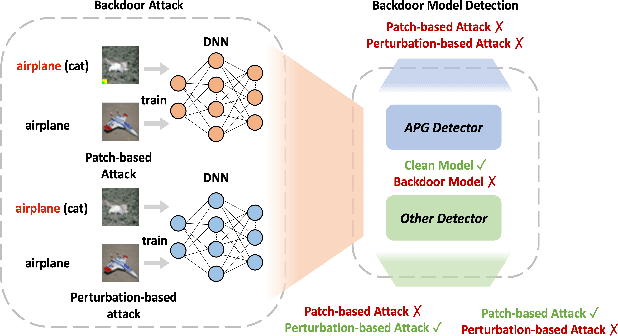
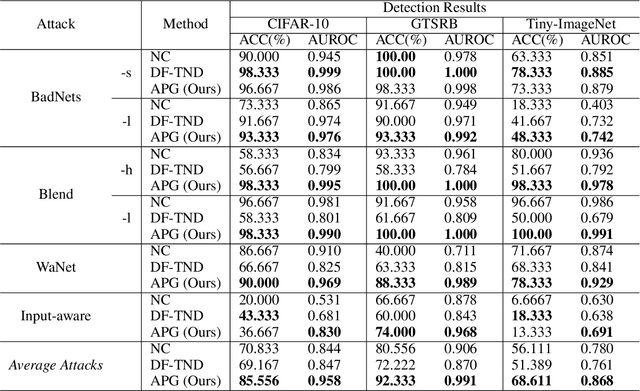
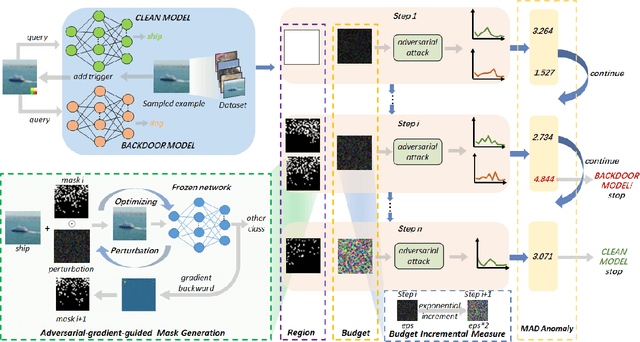
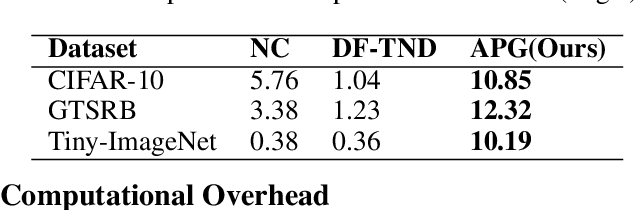
Extensive evidence has demonstrated that deep neural networks (DNNs) are vulnerable to backdoor attacks, which motivates the development of backdoor detection methods. Existing backdoor detection methods are typically tailored for backdoor attacks with individual specific types (e.g., patch-based or perturbation-based). However, adversaries are likely to generate multiple types of backdoor attacks in practice, which challenges the current detection strategies. Based on the fact that adversarial perturbations are highly correlated with trigger patterns, this paper proposes the Adaptive Perturbation Generation (APG) framework to detect multiple types of backdoor attacks by adaptively injecting adversarial perturbations. Since different trigger patterns turn out to show highly diverse behaviors under the same adversarial perturbations, we first design the global-to-local strategy to fit the multiple types of backdoor triggers via adjusting the region and budget of attacks. To further increase the efficiency of perturbation injection, we introduce a gradient-guided mask generation strategy to search for the optimal regions for adversarial attacks. Extensive experiments conducted on multiple datasets (CIFAR-10, GTSRB, Tiny-ImageNet) demonstrate that our method outperforms state-of-the-art baselines by large margins(+12%).
Exploring Disentangled Content Information for Face Forgery Detection
Jul 19, 2022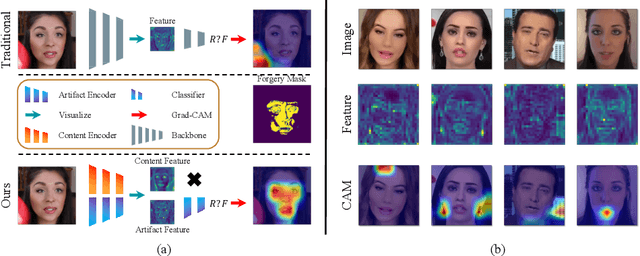
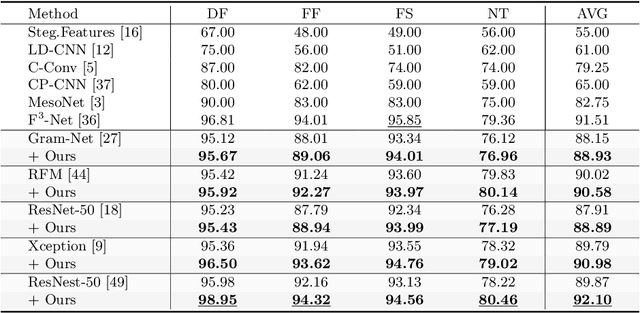

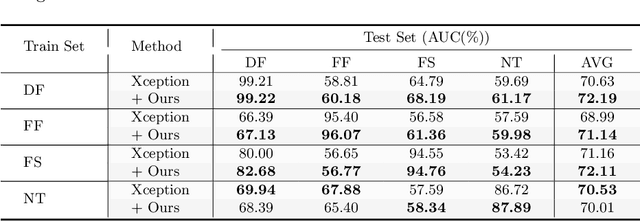
Convolutional neural network based face forgery detection methods have achieved remarkable results during training, but struggled to maintain comparable performance during testing. We observe that the detector is prone to focus more on content information than artifact traces, suggesting that the detector is sensitive to the intrinsic bias of the dataset, which leads to severe overfitting. Motivated by this key observation, we design an easily embeddable disentanglement framework for content information removal, and further propose a Content Consistency Constraint (C2C) and a Global Representation Contrastive Constraint (GRCC) to enhance the independence of disentangled features. Furthermore, we cleverly construct two unbalanced datasets to investigate the impact of the content bias. Extensive visualizations and experiments demonstrate that our framework can not only ignore the interference of content information, but also guide the detector to mine suspicious artifact traces and achieve competitive performance.
Few-shot Forgery Detection via Guided Adversarial Interpolation
Apr 12, 2022
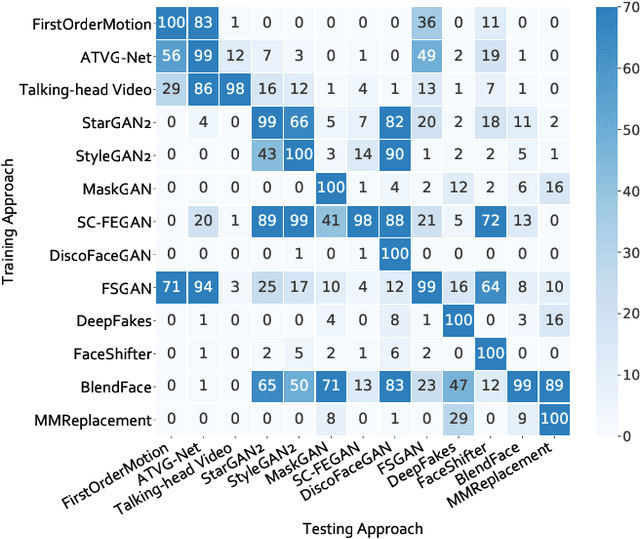
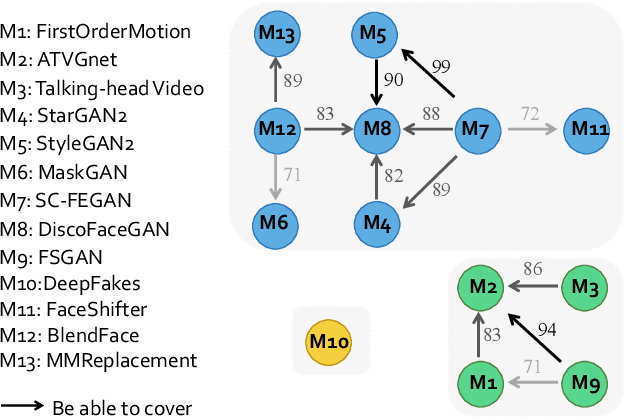
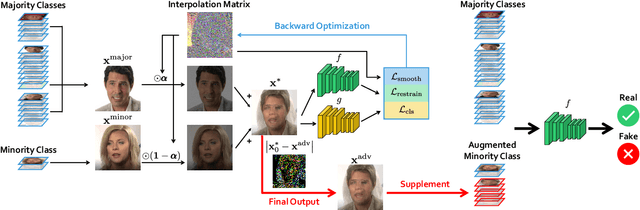
Realistic visual media synthesis is becoming a critical societal issue with the surge of face manipulation models; new forgery approaches emerge at an unprecedented pace. Unfortunately, existing forgery detection methods suffer significant performance drops when applied to novel forgery approaches. In this work, we address the few-shot forgery detection problem by designing a comprehensive benchmark based on coverage analysis among various forgery approaches, and proposing Guided Adversarial Interpolation (GAI). Our key insight is that there exist transferable distribution characteristics among different forgery approaches with the majority and minority classes. Specifically, we enhance the discriminative ability against novel forgery approaches via adversarially interpolating the artifacts of the minority samples to the majority samples under the guidance of a teacher network. Unlike the standard re-balancing method which usually results in over-fitting to minority classes, our method simultaneously takes account of the diversity of majority information as well as the significance of minority information. Extensive experiments demonstrate that our GAI achieves state-of-the-art performances on the established few-shot forgery detection benchmark. Notably, our method is also validated to be robust to choices of majority and minority forgery approaches.