 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Prompt-robust Face Privacy Protection via Adversarial Decoupling Augmentation Framework
Paper and Code
May 06, 2023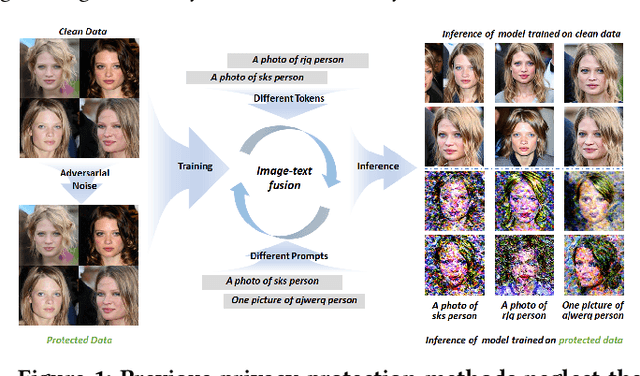
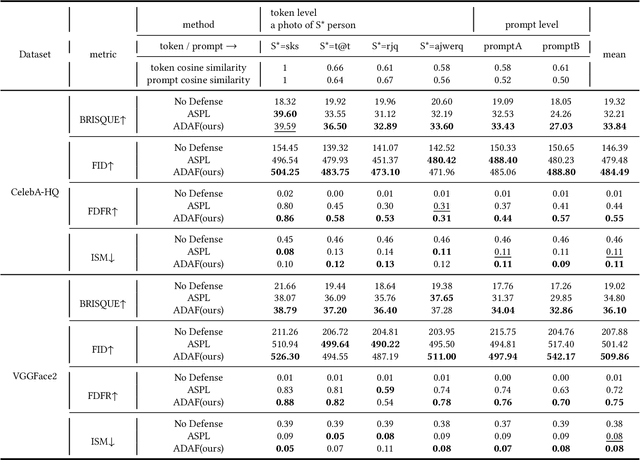
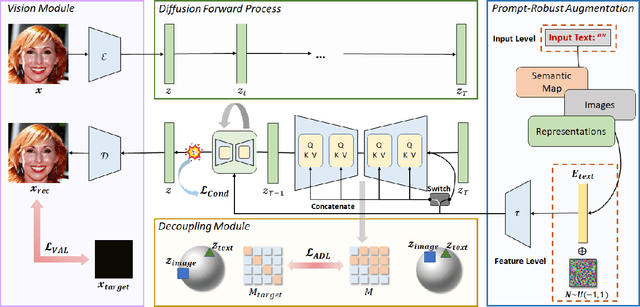
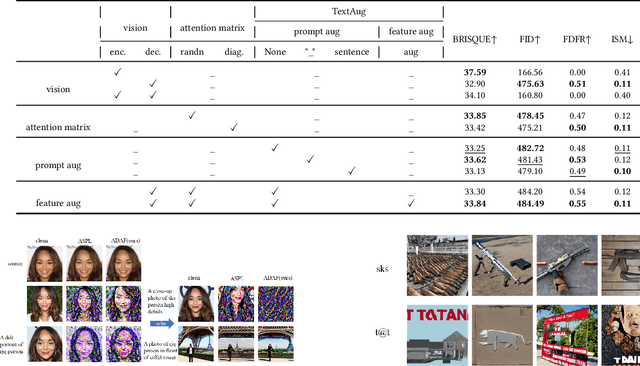
Denoising diffusion models have shown remarkable potential in various generation tasks. The open-source large-scale text-to-image model, Stable Diffusion, becomes prevalent as it can generate realistic artistic or facial images with personalization through fine-tuning on a limited number of new samples. However, this has raised privacy concerns as adversaries can acquire facial images online and fine-tune text-to-image models for malicious editing, leading to baseless scandals, defamation, and disruption to victims' lives. Prior research efforts have focused on deriving adversarial loss from conventional training processes for facial privacy protection through adversarial perturbations. However, existing algorithms face two issues: 1) they neglect the image-text fusion module, which is the vital module of text-to-image diffusion models, and 2) their defensive performance is unstable against different attacker prompts. In this paper, we propose the Adversarial Decoupling Augmentation Framework (ADAF), addressing these issues by targeting the image-text fusion module to enhance the defensive performance of facial privacy protection algorithms. ADAF introduces multi-level text-related augmentations for defense stability against various attacker prompts. Concretely, considering the vision, text, and common unit space, we propose Vision-Adversarial Loss, Prompt-Robust Augmentation, and Attention-Decoupling Loss. Extensive experiments on CelebA-HQ and VGGFace2 demonstrate ADAF's promising performance, surpassing existing algorithms.