 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating LLMs When They Do Not Know the Answer: Statistical Evaluation of Mathematical Reasoning via Comparative Signals
Feb 03, 2026Evaluating mathematical reasoning in LLMs is constrained by limited benchmark sizes and inherent model stochasticity, yielding high-variance accuracy estimates and unstable rankings across platforms. On difficult problems, an LLM may fail to produce a correct final answer, yet still provide reliable pairwise comparison signals indicating which of two candidate solutions is better. We leverage this observation to design a statistically efficient evaluation framework that combines standard labeled outcomes with pairwise comparison signals obtained by having models judge auxiliary reasoning chains. Treating these comparison signals as control variates, we develop a semiparametric estimator based on the efficient influence function (EIF) for the setting where auxiliary reasoning chains are observed. This yields a one-step estimator that achieves the semiparametric efficiency bound, guarantees strict variance reduction over naive sample averaging, and admits asymptotic normality for principled uncertainty quantification. Across simulations, our one-step estimator substantially improves ranking accuracy, with gains increasing as model output noise grows. Experiments on GPQA Diamond, AIME 2025, and GSM8K further demonstrate more precise performance estimation and more reliable model rankings, especially in small-sample regimes where conventional evaluation is pretty unstable.
MeanCache: From Instantaneous to Average Velocity for Accelerating Flow Matching Inference
Jan 27, 2026We present MeanCache, a training-free caching framework for efficient Flow Matching inference. Existing caching methods reduce redundant computation but typically rely on instantaneous velocity information (e.g., feature caching), which often leads to severe trajectory deviations and error accumulation under high acceleration ratios. MeanCache introduces an average-velocity perspective: by leveraging cached Jacobian--vector products (JVP) to construct interval average velocities from instantaneous velocities, it effectively mitigates local error accumulation. To further improve cache timing and JVP reuse stability, we develop a trajectory-stability scheduling strategy as a practical tool, employing a Peak-Suppressed Shortest Path under budget constraints to determine the schedule. Experiments on FLUX.1, Qwen-Image, and HunyuanVideo demonstrate that MeanCache achieves 4.12X and 4.56X and 3.59X acceleration, respectively, while consistently outperforming state-of-the-art caching baselines in generation quality. We believe this simple yet effective approach provides a new perspective for Flow Matching inference and will inspire further exploration of stability-driven acceleration in commercial-scale generative models.
Labels or Preferences? Budget-Constrained Learning with Human Judgments over AI-Generated Outputs
Jan 19, 2026The increasing reliance on human preference feedback to judge AI-generated pseudo labels has created a pressing need for principled, budget-conscious data acquisition strategies. We address the crucial question of how to optimally allocate a fixed annotation budget between ground-truth labels and pairwise preferences in AI. Our solution, grounded in semi-parametric inference, casts the budget allocation problem as a monotone missing data framework. Building on this formulation, we introduce Preference-Calibrated Active Learning (PCAL), a novel method that learns the optimal data acquisition strategy and develops a statistically efficient estimator for functionals of the data distribution. Theoretically, we prove the asymptotic optimality of our PCAL estimator and establish a key robustness guarantee that ensures robust performance even with poorly estimated nuisance models. Our flexible framework applies to a general class of problems, by directly optimizing the estimator's variance instead of requiring a closed-form solution. This work provides a principled and statistically efficient approach for budget-constrained learning in modern AI. Simulations and real-data analysis demonstrate the practical benefits and superior performance of our proposed method.
HiMo-CLIP: Modeling Semantic Hierarchy and Monotonicity in Vision-Language Alignment
Nov 10, 2025Contrastive vision-language models like CLIP have achieved impressive results in image-text retrieval by aligning image and text representations in a shared embedding space. However, these models often treat text as flat sequences, limiting their ability to handle complex, compositional, and long-form descriptions. In particular, they fail to capture two essential properties of language: semantic hierarchy, which reflects the multi-level compositional structure of text, and semantic monotonicity, where richer descriptions should result in stronger alignment with visual content.To address these limitations, we propose HiMo-CLIP, a representation-level framework that enhances CLIP-style models without modifying the encoder architecture. HiMo-CLIP introduces two key components: a hierarchical decomposition (HiDe) module that extracts latent semantic components from long-form text via in-batch PCA, enabling flexible, batch-aware alignment across different semantic granularities, and a monotonicity-aware contrastive loss (MoLo) that jointly aligns global and component-level representations, encouraging the model to internalize semantic ordering and alignment strength as a function of textual completeness.These components work in concert to produce structured, cognitively-aligned cross-modal representations. Experiments on multiple image-text retrieval benchmarks show that HiMo-CLIP consistently outperforms strong baselines, particularly under long or compositional descriptions. The code is available at https://github.com/UnicomAI/HiMo-CLIP.
* Accepted by AAAI 2026 as an Oral Presentation (13 pages, 7 figures, 7 tables)
Towards Prompt-robust Face Privacy Protection via Adversarial Decoupling Augmentation Framework
May 06, 2023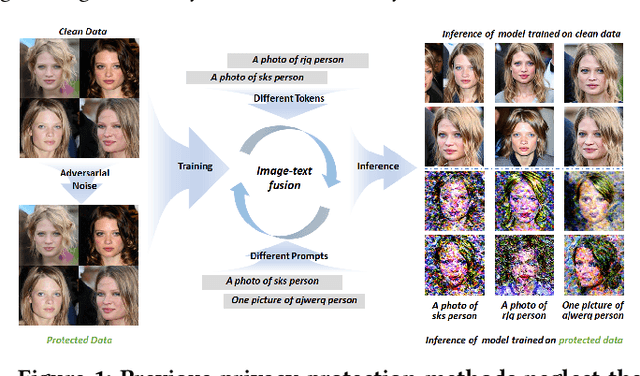
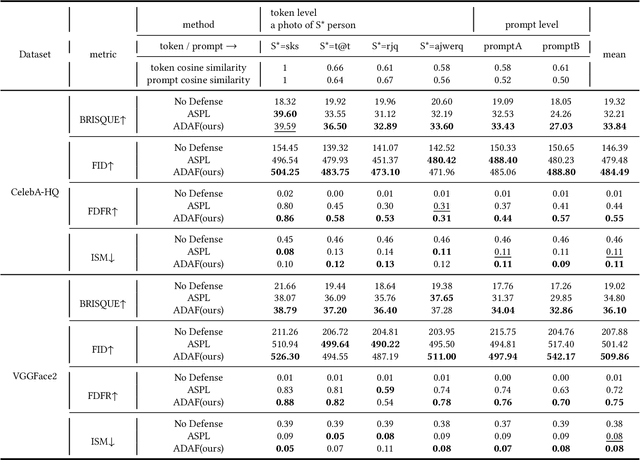
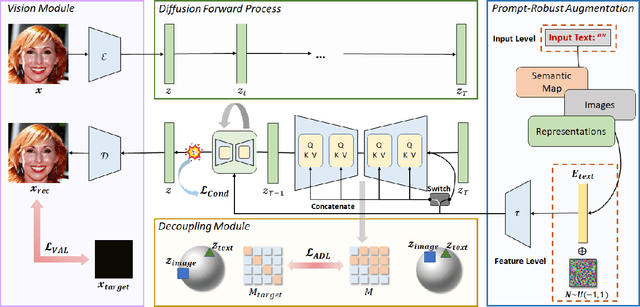
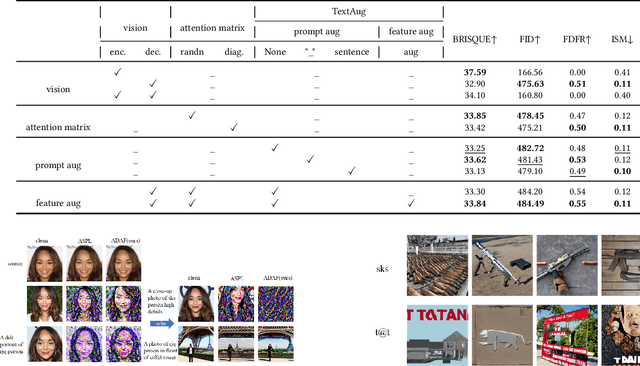
Denoising diffusion models have shown remarkable potential in various generation tasks. The open-source large-scale text-to-image model, Stable Diffusion, becomes prevalent as it can generate realistic artistic or facial images with personalization through fine-tuning on a limited number of new samples. However, this has raised privacy concerns as adversaries can acquire facial images online and fine-tune text-to-image models for malicious editing, leading to baseless scandals, defamation, and disruption to victims' lives. Prior research efforts have focused on deriving adversarial loss from conventional training processes for facial privacy protection through adversarial perturbations. However, existing algorithms face two issues: 1) they neglect the image-text fusion module, which is the vital module of text-to-image diffusion models, and 2) their defensive performance is unstable against different attacker prompts. In this paper, we propose the Adversarial Decoupling Augmentation Framework (ADAF), addressing these issues by targeting the image-text fusion module to enhance the defensive performance of facial privacy protection algorithms. ADAF introduces multi-level text-related augmentations for defense stability against various attacker prompts. Concretely, considering the vision, text, and common unit space, we propose Vision-Adversarial Loss, Prompt-Robust Augmentation, and Attention-Decoupling Loss. Extensive experiments on CelebA-HQ and VGGFace2 demonstrate ADAF's promising performance, surpassing existing algorithms.
Adaptive Perturbation Generation for Multiple Backdoors Detection
Sep 13, 2022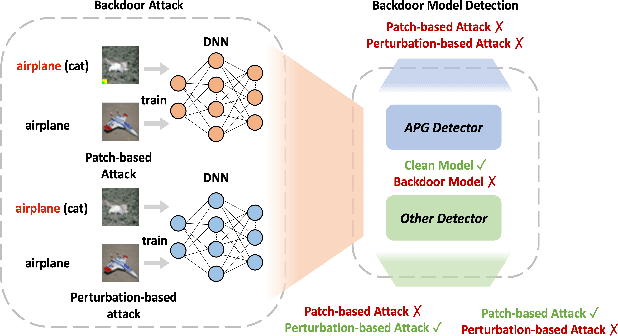
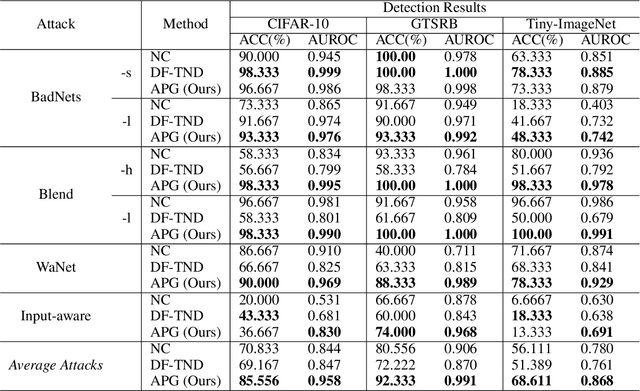
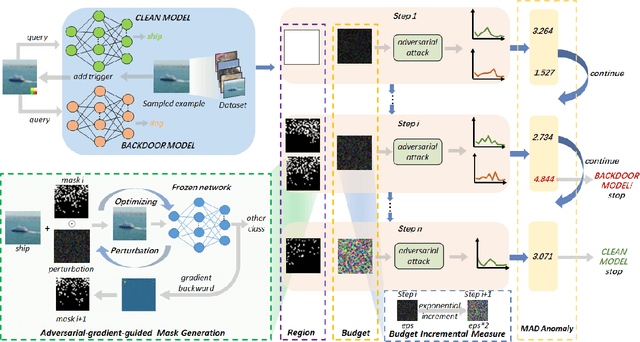
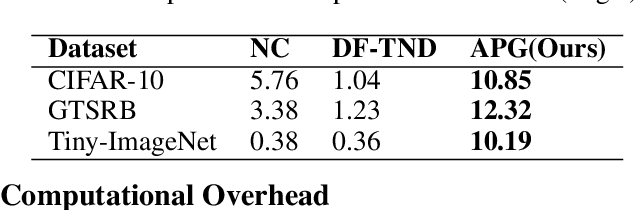
Extensive evidence has demonstrated that deep neural networks (DNNs) are vulnerable to backdoor attacks, which motivates the development of backdoor detection methods. Existing backdoor detection methods are typically tailored for backdoor attacks with individual specific types (e.g., patch-based or perturbation-based). However, adversaries are likely to generate multiple types of backdoor attacks in practice, which challenges the current detection strategies. Based on the fact that adversarial perturbations are highly correlated with trigger patterns, this paper proposes the Adaptive Perturbation Generation (APG) framework to detect multiple types of backdoor attacks by adaptively injecting adversarial perturbations. Since different trigger patterns turn out to show highly diverse behaviors under the same adversarial perturbations, we first design the global-to-local strategy to fit the multiple types of backdoor triggers via adjusting the region and budget of attacks. To further increase the efficiency of perturbation injection, we introduce a gradient-guided mask generation strategy to search for the optimal regions for adversarial attacks. Extensive experiments conducted on multiple datasets (CIFAR-10, GTSRB, Tiny-ImageNet) demonstrate that our method outperforms state-of-the-art baselines by large margins(+12%).