 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnical report of a DMD-based Characterization Method for Vision Sensors
Mar 04, 2025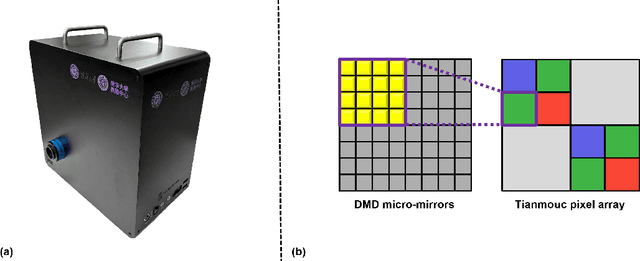

This technical report presents a novel DMD-based characterization method for vision sensors, particularly neuromorphic sensors such as event-based vision sensors (EVS) and Tianmouc, a complementary vision sensor. Traditional image sensor characterization standards, such as EMVA1288, are unsuitable for BVS due to their dynamic response characteristics. To address this, we propose a high-speed, high-precision testing system using a Digital Micromirror Device (DMD) to modulate spatial and temporal light intensity. This approach enables quantitative analysis of key parameters such as event latency, signal-to-noise ratio (SNR), and dynamic range (DR) under controlled conditions. Our method provides a standardized and reproducible testing framework, overcoming the limitations of existing evaluation techniques for neuromorphic sensors. Furthermore, we discuss the potential of this method for large-scale BVS dataset generation and conversion, paving the way for more consistent benchmarking of bio-inspired vision technologies.
Text-Guided 3D Face Synthesis -- From Generation to Editing
Dec 01, 2023


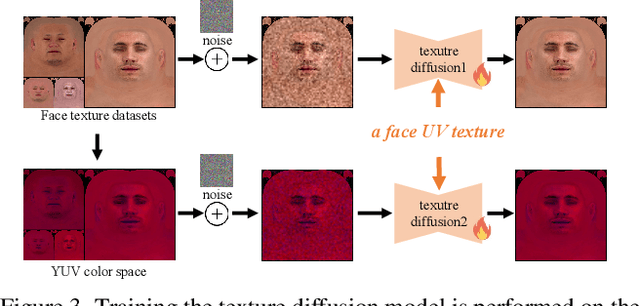
Text-guided 3D face synthesis has achieved remarkable results by leveraging text-to-image (T2I) diffusion models. However, most existing works focus solely on the direct generation, ignoring the editing, restricting them from synthesizing customized 3D faces through iterative adjustments. In this paper, we propose a unified text-guided framework from face generation to editing. In the generation stage, we propose a geometry-texture decoupled generation to mitigate the loss of geometric details caused by coupling. Besides, decoupling enables us to utilize the generated geometry as a condition for texture generation, yielding highly geometry-texture aligned results. We further employ a fine-tuned texture diffusion model to enhance texture quality in both RGB and YUV space. In the editing stage, we first employ a pre-trained diffusion model to update facial geometry or texture based on the texts. To enable sequential editing, we introduce a UV domain consistency preservation regularization, preventing unintentional changes to irrelevant facial attributes. Besides, we propose a self-guided consistency weight strategy to improve editing efficacy while preserving consistency. Through comprehensive experiments, we showcase our method's superiority in face synthesis. Project page: https://faceg2e.github.io/.
Zero-shot Text-driven Physically Interpretable Face Editing
Aug 11, 2023



This paper proposes a novel and physically interpretable method for face editing based on arbitrary text prompts. Different from previous GAN-inversion-based face editing methods that manipulate the latent space of GANs, or diffusion-based methods that model image manipulation as a reverse diffusion process, we regard the face editing process as imposing vector flow fields on face images, representing the offset of spatial coordinates and color for each image pixel. Under the above-proposed paradigm, we represent the vector flow field in two ways: 1) explicitly represent the flow vectors with rasterized tensors, and 2) implicitly parameterize the flow vectors as continuous, smooth, and resolution-agnostic neural fields, by leveraging the recent advances of implicit neural representations. The flow vectors are iteratively optimized under the guidance of the pre-trained Contrastive Language-Image Pretraining~(CLIP) model by maximizing the correlation between the edited image and the text prompt. We also propose a learning-based one-shot face editing framework, which is fast and adaptable to any text prompt input. Our method can also be flexibly extended to real-time video face editing. Compared with state-of-the-art text-driven face editing methods, our method can generate physically interpretable face editing results with high identity consistency and image quality. Our code will be made publicly available.