 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomy of Agentic Memory: Taxonomy and Empirical Analysis of Evaluation and System Limitations
Feb 22, 2026Agentic memory systems enable large language model (LLM) agents to maintain state across long interactions, supporting long-horizon reasoning and personalization beyond fixed context windows. Despite rapid architectural development, the empirical foundations of these systems remain fragile: existing benchmarks are often underscaled, evaluation metrics are misaligned with semantic utility, performance varies significantly across backbone models, and system-level costs are frequently overlooked. This survey presents a structured analysis of agentic memory from both architectural and system perspectives. We first introduce a concise taxonomy of MAG systems based on four memory structures. Then, we analyze key pain points limiting current systems, including benchmark saturation effects, metric validity and judge sensitivity, backbone-dependent accuracy, and the latency and throughput overhead introduced by memory maintenance. By connecting the memory structure to empirical limitations, this survey clarifies why current agentic memory systems often underperform their theoretical promise and outlines directions for more reliable evaluation and scalable system design.
Performance Analysis of End-to-End LEO Satellite-Aided Shore-to-Ship Communications: A Stochastic Geometry Approach
Oct 23, 2025Low Earth orbit (LEO) satellite networks have shown strategic superiority in maritime communications, assisting in establishing signal transmissions from shore to ship through space-based links. Traditional performance modeling based on multiple circular orbits is challenging to characterize large-scale LEO satellite constellations, thus requiring a tractable approach to accurately evaluate the network performance. In this paper, we propose a theoretical framework for an LEO satellite-aided shore-to-ship communication network (LEO-SSCN), where LEO satellites are distributed as a binomial point process (BPP) on a specific spherical surface. The framework aims to obtain the end-to-end transmission performance by considering signal transmissions through either a marine link or a space link subject to Rician or Shadowed Rician fading, respectively. Due to the indeterminate position of the serving satellite, accurately modeling the distance from the serving satellite to the destination ship becomes intractable. To address this issue, we propose a distance approximation approach. Then, by approximation and incorporating a threshold-based communication scheme, we leverage stochastic geometry to derive analytical expressions of end-to-end transmission success probability and average transmission rate capacity. Extensive numerical results verify the accuracy of the analysis and demonstrate the effect of key parameters on the performance of LEO-SSCN.
Segment Anything in 3D Gaussians
Feb 01, 2024



3D Gaussian Splatting has emerged as an alternative 3D representation of Neural Radiance Fields (NeRFs), benefiting from its high-quality rendering results and real-time rendering speed. Considering the 3D Gaussian representation remains unparsed, it is necessary first to execute object segmentation within this domain. Subsequently, scene editing and collision detection can be performed, proving vital to a multitude of applications, such as virtual reality (VR), augmented reality (AR), game/movie production, etc. In this paper, we propose a novel approach to achieve object segmentation in 3D Gaussian via an interactive procedure without any training process and learned parameters. We refer to the proposed method as SA-GS, for Segment Anything in 3D Gaussians. Given a set of clicked points in a single input view, SA-GS can generalize SAM to achieve 3D consistent segmentation via the proposed multi-view mask generation and view-wise label assignment methods. We also propose a cross-view label-voting approach to assign labels from different views. In addition, in order to address the boundary roughness issue of segmented objects resulting from the non-negligible spatial sizes of 3D Gaussian located at the boundary, SA-GS incorporates the simple but effective Gaussian Decomposition scheme. Extensive experiments demonstrate that SA-GS achieves high-quality 3D segmentation results, which can also be easily applied for scene editing and collision detection tasks. Codes will be released soon.
Zero-shot Text-driven Physically Interpretable Face Editing
Aug 11, 2023



This paper proposes a novel and physically interpretable method for face editing based on arbitrary text prompts. Different from previous GAN-inversion-based face editing methods that manipulate the latent space of GANs, or diffusion-based methods that model image manipulation as a reverse diffusion process, we regard the face editing process as imposing vector flow fields on face images, representing the offset of spatial coordinates and color for each image pixel. Under the above-proposed paradigm, we represent the vector flow field in two ways: 1) explicitly represent the flow vectors with rasterized tensors, and 2) implicitly parameterize the flow vectors as continuous, smooth, and resolution-agnostic neural fields, by leveraging the recent advances of implicit neural representations. The flow vectors are iteratively optimized under the guidance of the pre-trained Contrastive Language-Image Pretraining~(CLIP) model by maximizing the correlation between the edited image and the text prompt. We also propose a learning-based one-shot face editing framework, which is fast and adaptable to any text prompt input. Our method can also be flexibly extended to real-time video face editing. Compared with state-of-the-art text-driven face editing methods, our method can generate physically interpretable face editing results with high identity consistency and image quality. Our code will be made publicly available.
EasyASR: A Distributed Machine Learning Platform for End-to-end Automatic Speech Recognition
Sep 14, 2020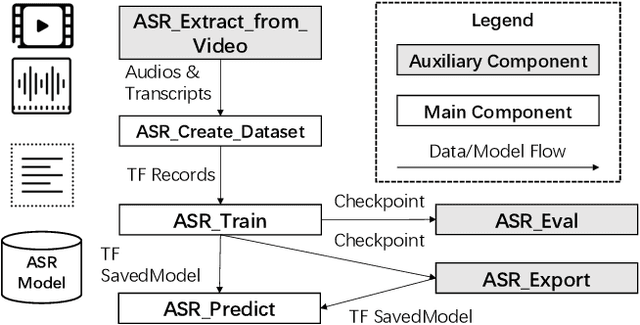
We present EasyASR, a distributed machine learning platform for training and serving large-scale Automatic Speech Recognition (ASR) models, as well as collecting and processing audio data at scale. Our platform is built upon the Machine Learning Platform for AI of Alibaba Cloud. Its main functionality is to support efficient learning and inference for end-to-end ASR models on distributed GPU clusters. It allows users to learn ASR models with either pre-defined or user-customized network architectures via simple user interface. On EasyASR, we have produced state-of-the-art results over several public datasets for Mandarin speech recognition.
Weakly Supervised Construction of ASR Systems with Massive Video Data
Aug 04, 2020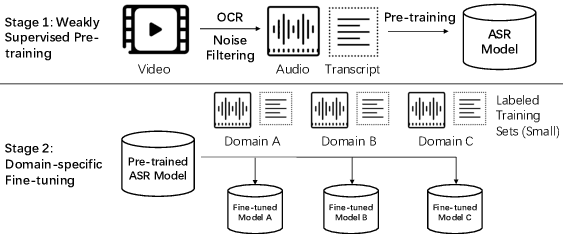
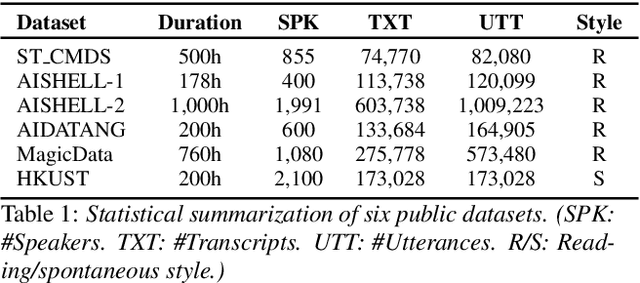
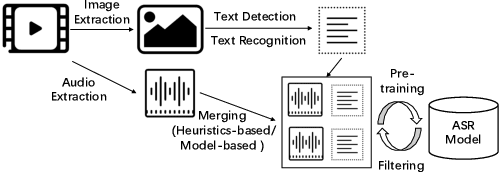
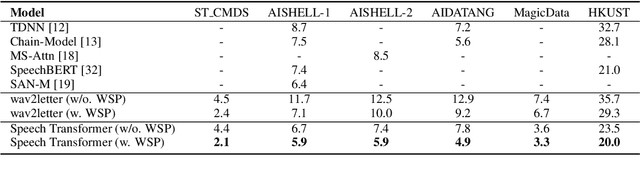
Building Automatic Speech Recognition (ASR) systems from scratch is significantly challenging, mostly due to the time-consuming and financially-expensive process of annotating a large amount of audio data with transcripts. Although several unsupervised pre-training models have been proposed, applying such models directly might still be sub-optimal if more labeled, training data could be obtained without a large cost. In this paper, we present a weakly supervised framework for constructing ASR systems with massive video data. As videos often contain human-speech audios aligned with subtitles, we consider videos as an important knowledge source, and propose an effective approach to extract high-quality audios aligned with transcripts from videos based on Optical Character Recognition (OCR). The underlying ASR model can be fine-tuned to fit any domain-specific target training datasets after weakly supervised pre-training. Extensive experiments show that our framework can easily produce state-of-the-art results on six public datasets for Mandarin speech recognition.
Artificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
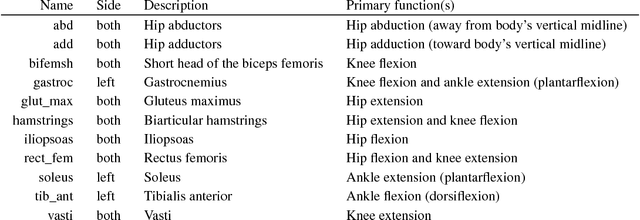
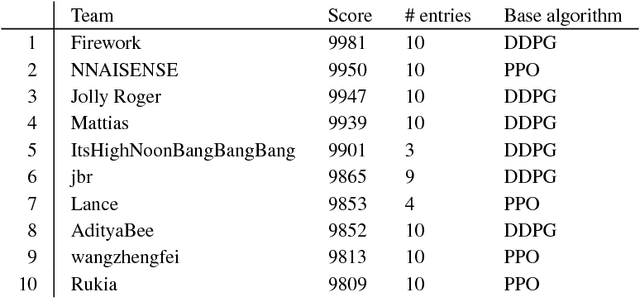

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.