 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee Finer, See More: Implicit Modality Alignment for Text-based Person Retrieval
Paper and Code

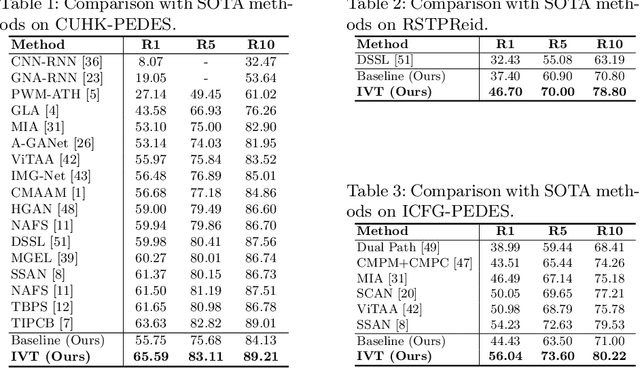
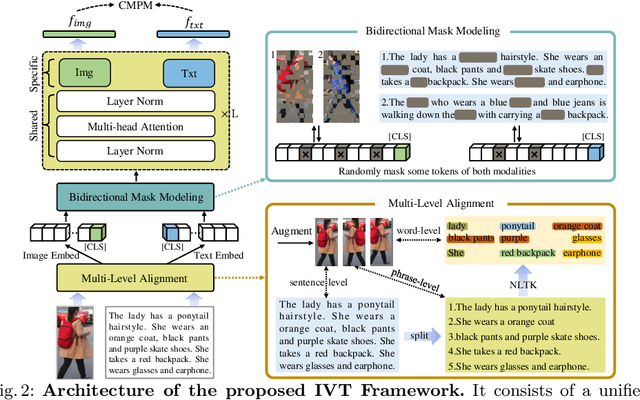

Text-based person retrieval aims to find the query person based on a textual description. The key is to learn a common latent space mapping between visual-textual modalities. To achieve this goal, existing works employ segmentation to obtain explicitly cross-modal alignments or utilize attention to explore salient alignments. These methods have two shortcomings: 1) Labeling cross-modal alignments are time-consuming. 2) Attention methods can explore salient cross-modal alignments but may ignore some subtle and valuable pairs. To relieve these issues, we introduce an Implicit Visual-Textual (IVT) framework for text-based person retrieval. Different from previous models, IVT utilizes a single network to learn representation for both modalities, which contributes to the visual-textual interaction. To explore the fine-grained alignment, we further propose two implicit semantic alignment paradigms: multi-level alignment (MLA) and bidirectional mask modeling (BMM). The MLA module explores finer matching at sentence, phrase, and word levels, while the BMM module aims to mine \textbf{more} semantic alignments between visual and textual modalities. Extensive experiments are carried out to evaluate the proposed IVT on public datasets, i.e., CUHK-PEDES, RSTPReID, and ICFG-PEDES. Even without explicit body part alignment, our approach still achieves state-of-the-art performance. Code is available at: https://github.com/TencentYoutuResearch/PersonRetrieval-IVT.