 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking into the Unknown: Exploring Action Discovery for Segmentation of Known and Unknown Actions
Aug 07, 2025We introduce Action Discovery, a novel setup within Temporal Action Segmentation that addresses the challenge of defining and annotating ambiguous actions and incomplete annotations in partially labeled datasets. In this setup, only a subset of actions - referred to as known actions - is annotated in the training data, while other unknown actions remain unlabeled. This scenario is particularly relevant in domains like neuroscience, where well-defined behaviors (e.g., walking, eating) coexist with subtle or infrequent actions that are often overlooked, as well as in applications where datasets are inherently partially annotated due to ambiguous or missing labels. To address this problem, we propose a two-step approach that leverages the known annotations to guide both the temporal and semantic granularity of unknown action segments. First, we introduce the Granularity-Guided Segmentation Module (GGSM), which identifies temporal intervals for both known and unknown actions by mimicking the granularity of annotated actions. Second, we propose the Unknown Action Segment Assignment (UASA), which identifies semantically meaningful classes within the unknown actions, based on learned embedding similarities. We systematically explore the proposed setting of Action Discovery on three challenging datasets - Breakfast, 50Salads, and Desktop Assembly - demonstrating that our method considerably improves upon existing baselines.
MANTA: Diffusion Mamba for Efficient and Effective Stochastic Long-Term Dense Anticipation
Jan 15, 2025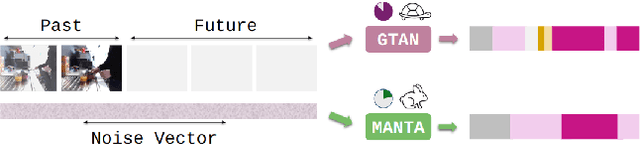

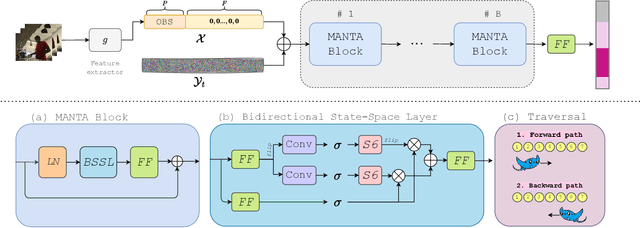

Our work addresses the problem of stochastic long-term dense anticipation. The goal of this task is to predict actions and their durations several minutes into the future based on provided video observations. Anticipation over extended horizons introduces high uncertainty, as a single observation can lead to multiple plausible future outcomes. To address this uncertainty, stochastic models are designed to predict several potential future action sequences. Recent work has further proposed to incorporate uncertainty modelling for observed frames by simultaneously predicting per-frame past and future actions in a unified manner. While such joint modelling of actions is beneficial, it requires long-range temporal capabilities to connect events across distant past and future time points. However, the previous work struggles to achieve such a long-range understanding due to its limited and/or sparse receptive field. To alleviate this issue, we propose a novel MANTA (MAmba for ANTicipation) network. Our model enables effective long-term temporal modelling even for very long sequences while maintaining linear complexity in sequence length. We demonstrate that our approach achieves state-of-the-art results on three datasets - Breakfast, 50Salads, and Assembly101 - while also significantly improving computational and memory efficiency.
Gated Temporal Diffusion for Stochastic Long-Term Dense Anticipation
Jul 16, 2024



Long-term action anticipation has become an important task for many applications such as autonomous driving and human-robot interaction. Unlike short-term anticipation, predicting more actions into the future imposes a real challenge with the increasing uncertainty in longer horizons. While there has been a significant progress in predicting more actions into the future, most of the proposed methods address the task in a deterministic setup and ignore the underlying uncertainty. In this paper, we propose a novel Gated Temporal Diffusion (GTD) network that models the uncertainty of both the observation and the future predictions. As generator, we introduce a Gated Anticipation Network (GTAN) to model both observed and unobserved frames of a video in a mutual representation. On the one hand, using a mutual representation for past and future allows us to jointly model ambiguities in the observation and future, while on the other hand GTAN can by design treat the observed and unobserved parts differently and steer the information flow between them. Our model achieves state-of-the-art results on the Breakfast, Assembly101 and 50Salads datasets in both stochastic and deterministic settings. Code: https://github.com/olga-zats/GTDA .
Rethinking temporal self-similarity for repetitive action counting
Jul 12, 2024



Counting repetitive actions in long untrimmed videos is a challenging task that has many applications such as rehabilitation. State-of-the-art methods predict action counts by first generating a temporal self-similarity matrix (TSM) from the sampled frames and then feeding the matrix to a predictor network. The self-similarity matrix, however, is not an optimal input to a network since it discards too much information from the frame-wise embeddings. We thus rethink how a TSM can be utilized for counting repetitive actions and propose a framework that learns embeddings and predicts action start probabilities at full temporal resolution. The number of repeated actions is then inferred from the action start probabilities. In contrast to current approaches that have the TSM as an intermediate representation, we propose a novel loss based on a generated reference TSM, which enforces that the self-similarity of the learned frame-wise embeddings is consistent with the self-similarity of repeated actions. The proposed framework achieves state-of-the-art results on three datasets, i.e., RepCount, UCFRep, and Countix.
Robust Action Segmentation from Timestamp Supervision
Oct 12, 2022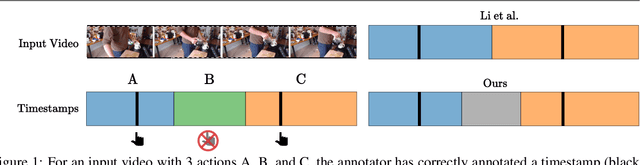
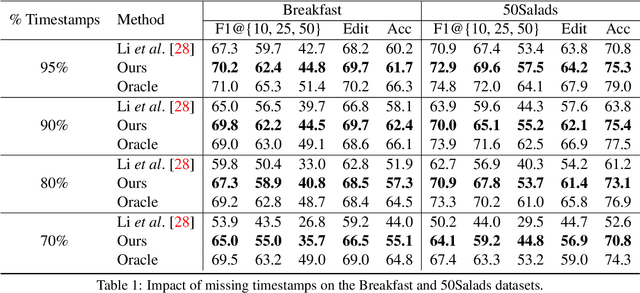
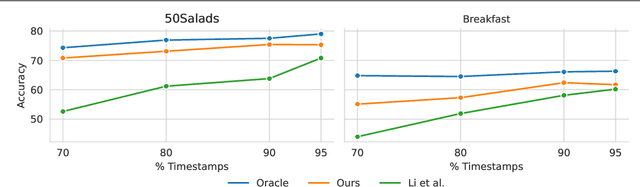
Action segmentation is the task of predicting an action label for each frame of an untrimmed video. As obtaining annotations to train an approach for action segmentation in a fully supervised way is expensive, various approaches have been proposed to train action segmentation models using different forms of weak supervision, e.g., action transcripts, action sets, or more recently timestamps. Timestamp supervision is a promising type of weak supervision as obtaining one timestamp per action is less expensive than annotating all frames, but it provides more information than other forms of weak supervision. However, previous works assume that every action instance is annotated with a timestamp, which is a restrictive assumption since it assumes that annotators do not miss any action. In this work, we relax this restrictive assumption and take missing annotations for some action instances into account. We show that our approach is more robust to missing annotations compared to other approaches and various baselines.
Self-supervised Learning for Unintentional Action Prediction
Sep 24, 2022Distinguishing if an action is performed as intended or if an intended action fails is an important skill that not only humans have, but that is also important for intelligent systems that operate in human environments. Recognizing if an action is unintentional or anticipating if an action will fail, however, is not straightforward due to lack of annotated data. While videos of unintentional or failed actions can be found in the Internet in abundance, high annotation costs are a major bottleneck for learning networks for these tasks. In this work, we thus study the problem of self-supervised representation learning for unintentional action prediction. While previous works learn the representation based on a local temporal neighborhood, we show that the global context of a video is needed to learn a good representation for the three downstream tasks: unintentional action classification, localization and anticipation. In the supplementary material, we show that the learned representation can be used for detecting anomalies in videos as well.
FIFA: Fast Inference Approximation for Action Segmentation
Aug 09, 2021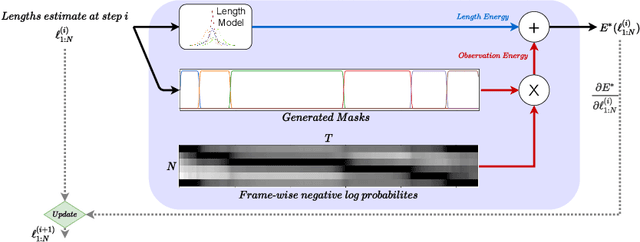
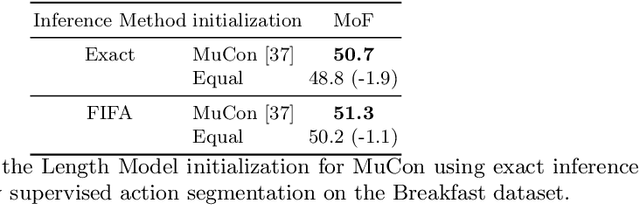
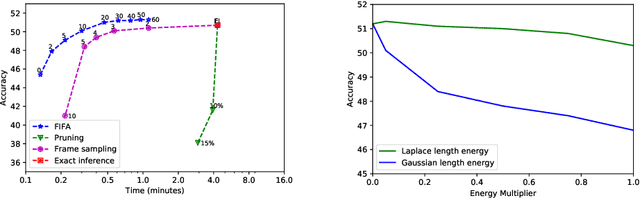
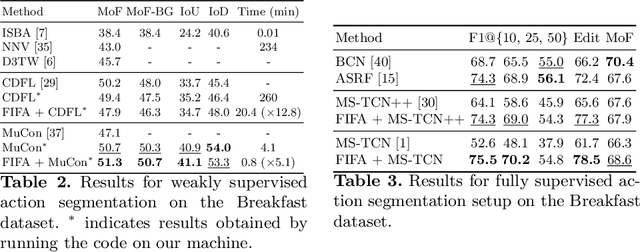
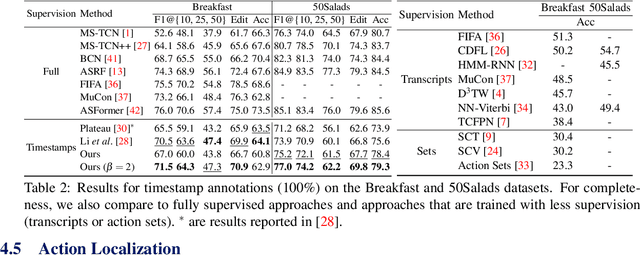
We introduce FIFA, a fast approximate inference method for action segmentation and alignment. Unlike previous approaches, FIFA does not rely on expensive dynamic programming for inference. Instead, it uses an approximate differentiable energy function that can be minimized using gradient-descent. FIFA is a general approach that can replace exact inference improving its speed by more than 5 times while maintaining its performance. FIFA is an anytime inference algorithm that provides a better speed vs. accuracy trade-off compared to exact inference. We apply FIFA on top of state-of-the-art approaches for weakly supervised action segmentation and alignment as well as fully supervised action segmentation. FIFA achieves state-of-the-art results on most metrics on two action segmentation datasets.
Multi-Modal Temporal Convolutional Network for Anticipating Actions in Egocentric Videos
Jul 18, 2021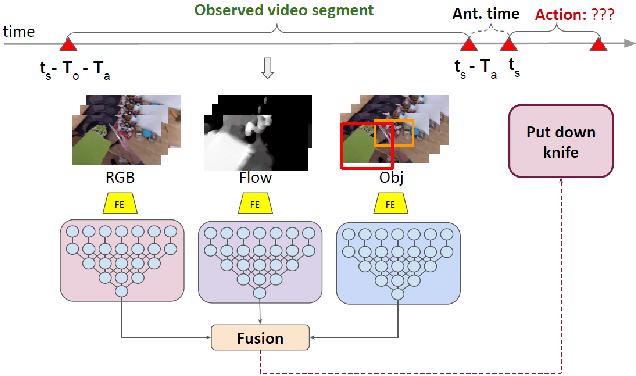
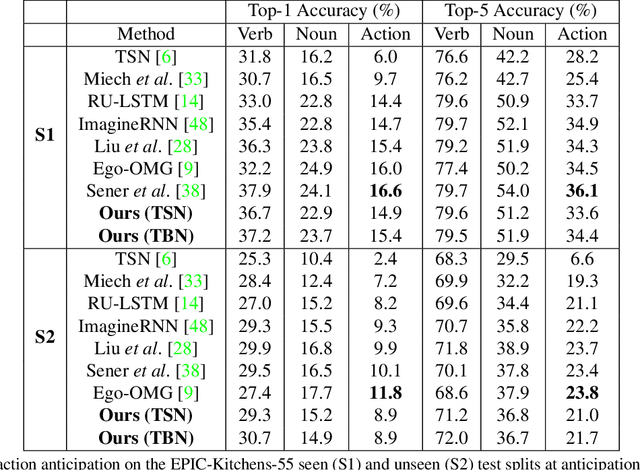

Anticipating human actions is an important task that needs to be addressed for the development of reliable intelligent agents, such as self-driving cars or robot assistants. While the ability to make future predictions with high accuracy is crucial for designing the anticipation approaches, the speed at which the inference is performed is not less important. Methods that are accurate but not sufficiently fast would introduce a high latency into the decision process. Thus, this will increase the reaction time of the underlying system. This poses a problem for domains such as autonomous driving, where the reaction time is crucial. In this work, we propose a simple and effective multi-modal architecture based on temporal convolutions. Our approach stacks a hierarchy of temporal convolutional layers and does not rely on recurrent layers to ensure a fast prediction. We further introduce a multi-modal fusion mechanism that captures the pairwise interactions between RGB, flow, and object modalities. Results on two large-scale datasets of egocentric videos, EPIC-Kitchens-55 and EPIC-Kitchens-100, show that our approach achieves comparable performance to the state-of-the-art approaches while being significantly faster.
Temporal Action Segmentation from Timestamp Supervision
Mar 26, 2021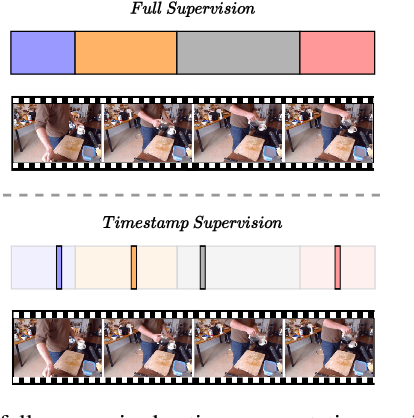
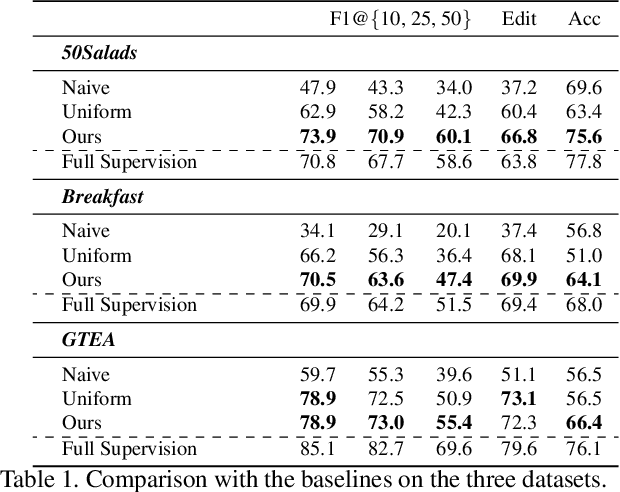
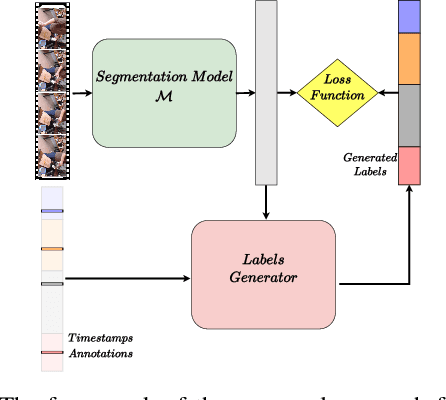
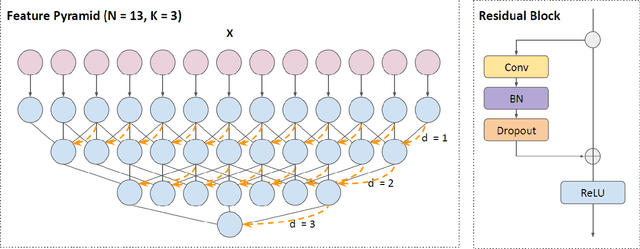
Temporal action segmentation approaches have been very successful recently. However, annotating videos with frame-wise labels to train such models is very expensive and time consuming. While weakly supervised methods trained using only ordered action lists require less annotation effort, the performance is still worse than fully supervised approaches. In this paper, we propose to use timestamp supervision for the temporal action segmentation task. Timestamps require a comparable annotation effort to weakly supervised approaches, and yet provide a more supervisory signal. To demonstrate the effectiveness of timestamp supervision, we propose an approach to train a segmentation model using only timestamps annotations. Our approach uses the model output and the annotated timestamps to generate frame-wise labels by detecting the action changes. We further introduce a confidence loss that forces the predicted probabilities to monotonically decrease as the distance to the timestamps increases. This ensures that all and not only the most distinctive frames of an action are learned during training. The evaluation on four datasets shows that models trained with timestamps annotations achieve comparable performance to the fully supervised approaches.
Pose Refinement Graph Convolutional Network for Skeleton-based Action Recognition
Oct 14, 2020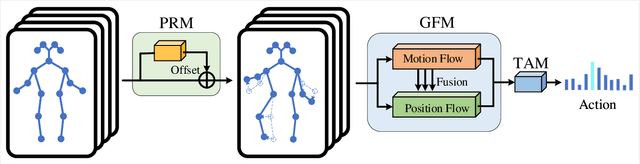
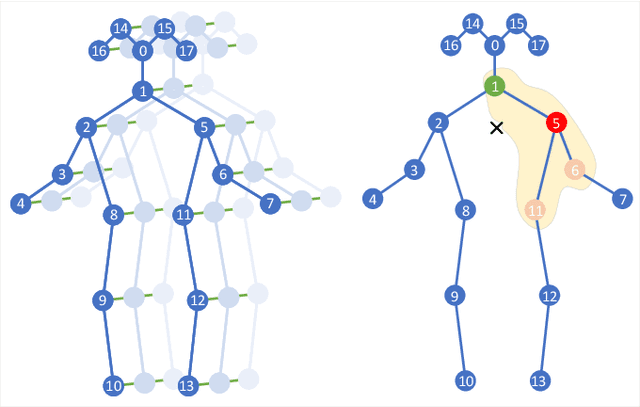
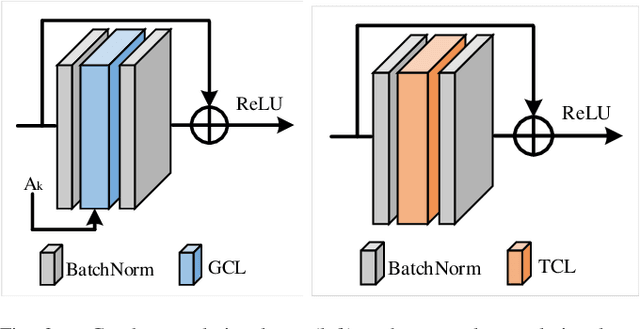
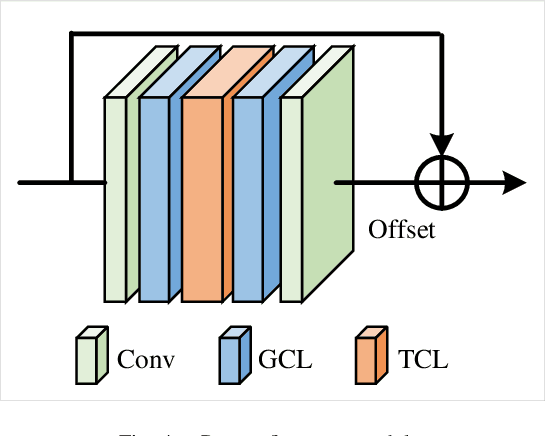
With the advances in capturing 2D or 3D skeleton data, skeleton-based action recognition has received an increasing interest over the last years. As skeleton data is commonly represented by graphs, graph convolutional networks have been proposed for this task. While current graph convolutional networks accurately recognize actions, they are too expensive for robotics applications where limited computational resources are available. In this paper, we therefore propose a highly efficient graph convolutional network that addresses the limitations of previous works. This is achieved by a parallel structure that gradually fuses motion and spatial information and by reducing the temporal resolution as early as possible. Furthermore, we explicitly address the issue that human poses can contain errors. To this end, the network first refines the poses before they are further processed to recognize the action. We therefore call the network Pose Refinement Graph Convolutional Network. Compared to other graph convolutional networks, our network requires 86\%-93\% less parameters and reduces the floating point operations by 89%-96% while achieving a comparable accuracy. It therefore provides a much better trade-off between accuracy, memory footprint and processing time, which makes it suitable for robotics applications.