 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose Refinement Graph Convolutional Network for Skeleton-based Action Recognition
Paper and Code
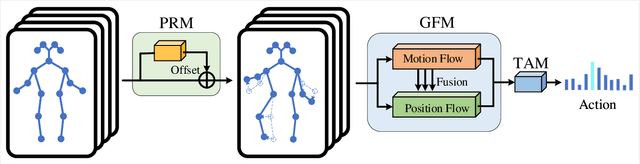
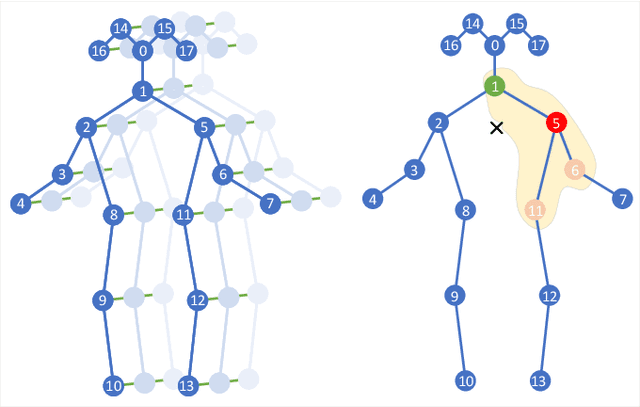
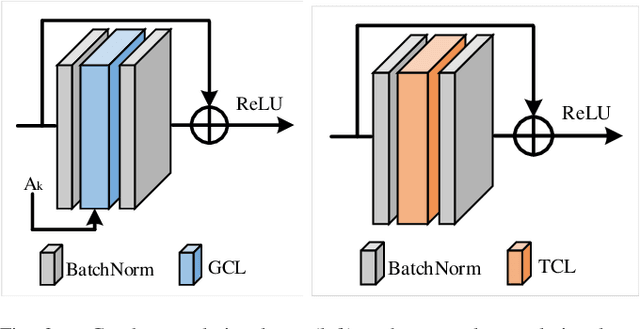
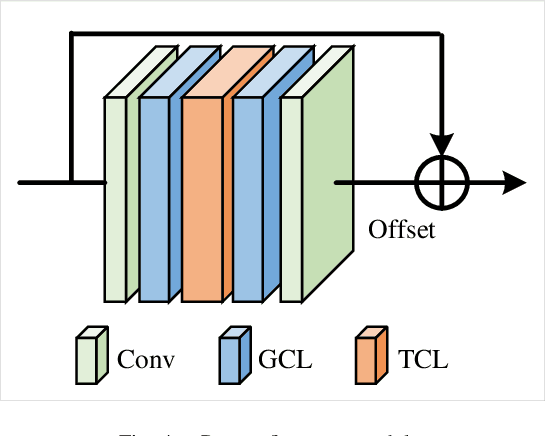
With the advances in capturing 2D or 3D skeleton data, skeleton-based action recognition has received an increasing interest over the last years. As skeleton data is commonly represented by graphs, graph convolutional networks have been proposed for this task. While current graph convolutional networks accurately recognize actions, they are too expensive for robotics applications where limited computational resources are available. In this paper, we therefore propose a highly efficient graph convolutional network that addresses the limitations of previous works. This is achieved by a parallel structure that gradually fuses motion and spatial information and by reducing the temporal resolution as early as possible. Furthermore, we explicitly address the issue that human poses can contain errors. To this end, the network first refines the poses before they are further processed to recognize the action. We therefore call the network Pose Refinement Graph Convolutional Network. Compared to other graph convolutional networks, our network requires 86\%-93\% less parameters and reduces the floating point operations by 89%-96% while achieving a comparable accuracy. It therefore provides a much better trade-off between accuracy, memory footprint and processing time, which makes it suitable for robotics applications.