 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances and Innovations in the Multi-Agent Robotic System (MARS) Challenge
Jan 26, 2026Recent advancements in multimodal large language models and vision-languageaction models have significantly driven progress in Embodied AI. As the field transitions toward more complex task scenarios, multi-agent system frameworks are becoming essential for achieving scalable, efficient, and collaborative solutions. This shift is fueled by three primary factors: increasing agent capabilities, enhancing system efficiency through task delegation, and enabling advanced human-agent interactions. To address the challenges posed by multi-agent collaboration, we propose the Multi-Agent Robotic System (MARS) Challenge, held at the NeurIPS 2025 Workshop on SpaVLE. The competition focuses on two critical areas: planning and control, where participants explore multi-agent embodied planning using vision-language models (VLMs) to coordinate tasks and policy execution to perform robotic manipulation in dynamic environments. By evaluating solutions submitted by participants, the challenge provides valuable insights into the design and coordination of embodied multi-agent systems, contributing to the future development of advanced collaborative AI systems.
MORE: Mobile Manipulation Rearrangement Through Grounded Language Reasoning
May 05, 2025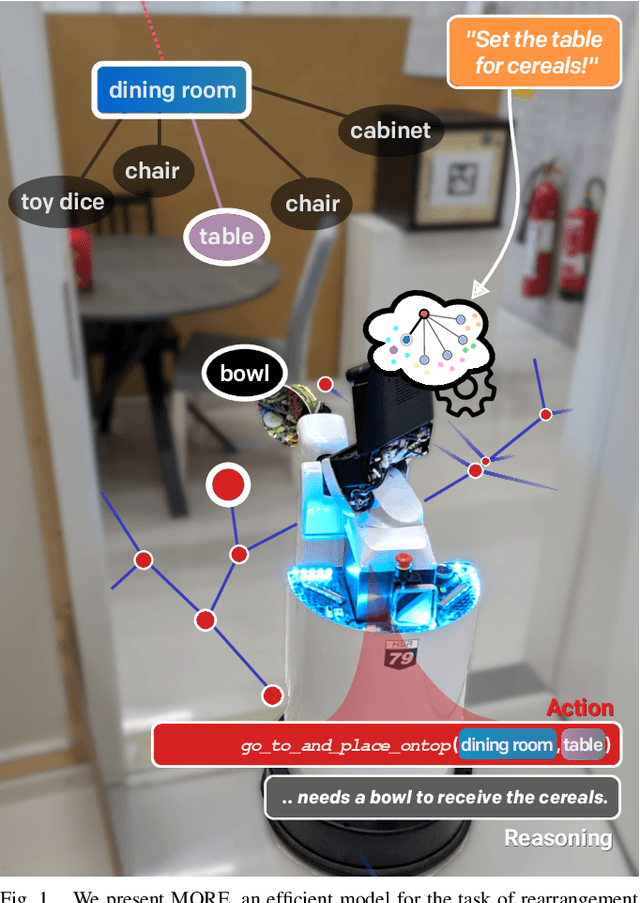
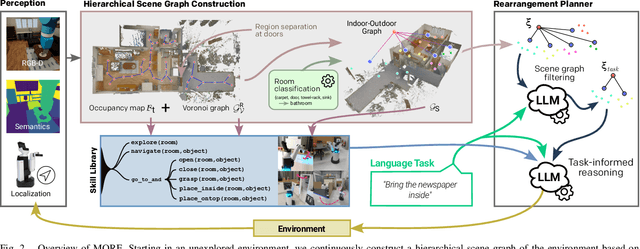
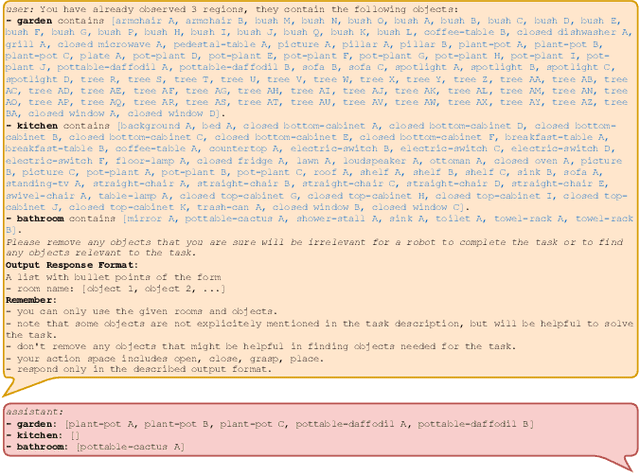
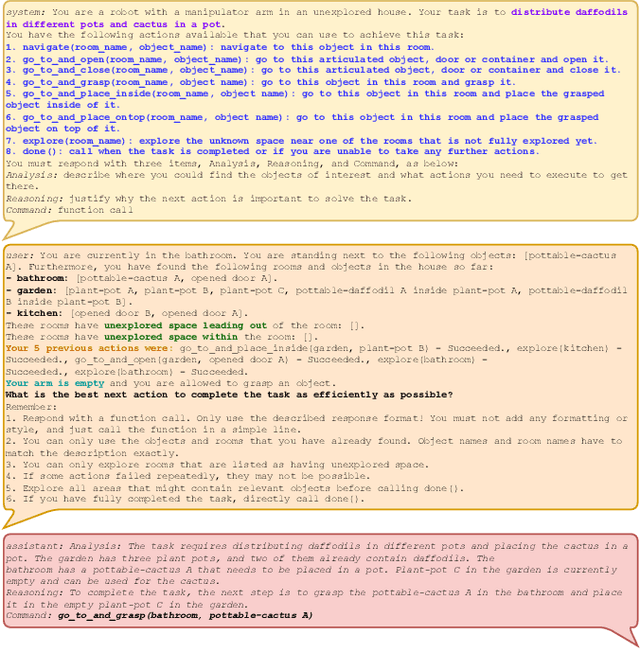
Autonomous long-horizon mobile manipulation encompasses a multitude of challenges, including scene dynamics, unexplored areas, and error recovery. Recent works have leveraged foundation models for scene-level robotic reasoning and planning. However, the performance of these methods degrades when dealing with a large number of objects and large-scale environments. To address these limitations, we propose MORE, a novel approach for enhancing the capabilities of language models to solve zero-shot mobile manipulation planning for rearrangement tasks. MORE leverages scene graphs to represent environments, incorporates instance differentiation, and introduces an active filtering scheme that extracts task-relevant subgraphs of object and region instances. These steps yield a bounded planning problem, effectively mitigating hallucinations and improving reliability. Additionally, we introduce several enhancements that enable planning across both indoor and outdoor environments. We evaluate MORE on 81 diverse rearrangement tasks from the BEHAVIOR-1K benchmark, where it becomes the first approach to successfully solve a significant share of the benchmark, outperforming recent foundation model-based approaches. Furthermore, we demonstrate the capabilities of our approach in several complex real-world tasks, mimicking everyday activities. We make the code publicly available at https://more-model.cs.uni-freiburg.de.
Robotic Task Ambiguity Resolution via Natural Language Interaction
Apr 24, 2025



Language-conditioned policies have recently gained substantial adoption in robotics as they allow users to specify tasks using natural language, making them highly versatile. While much research has focused on improving the action prediction of language-conditioned policies, reasoning about task descriptions has been largely overlooked. Ambiguous task descriptions often lead to downstream policy failures due to misinterpretation by the robotic agent. To address this challenge, we introduce AmbResVLM, a novel method that grounds language goals in the observed scene and explicitly reasons about task ambiguity. We extensively evaluate its effectiveness in both simulated and real-world domains, demonstrating superior task ambiguity detection and resolution compared to recent state-of-the-art baselines. Finally, real robot experiments show that our model improves the performance of downstream robot policies, increasing the average success rate from 69.6% to 97.1%. We make the data, code, and trained models publicly available at https://ambres.cs.uni-freiburg.de.
Annotation Free Semantic Segmentation with Vision Foundation Models
Mar 14, 2024Semantic Segmentation is one of the most challenging vision tasks, usually requiring large amounts of training data with expensive pixel-level annotations. With the success of foundation models and especially vision-language models, recent works attempt to achieve zero-shot semantic segmentation while requiring either large scale training or additional image/pixel-level annotations. In this work, we build a lightweight module on top of a self-supervised pretrained vision encoder to align patch features with a pre-trained text encoder. Importantly, we generate free annotations for any semantic segmentation dataset using existing foundation models and train our alignment module cost free. We use CLIP to detect objects and SAM to generate high quality object masks. Our approach can bring language-based semantics to any pre-trained vision encoder with minimal training. Our module is lightweight, uses foundation models as a sole source of supervision and shows impressive generalization capability from little training data with no annotation.
Language-Grounded Dynamic Scene Graphs for Interactive Object Search with Mobile Manipulation
Mar 14, 2024



To fully leverage the capabilities of mobile manipulation robots, it is imperative that they are able to autonomously execute long-horizon tasks in large unexplored environments. While large language models (LLMs) have shown emergent reasoning skills on arbitrary tasks, existing work primarily concentrates on explored environments, typically focusing on either navigation or manipulation tasks in isolation. In this work, we propose MoMa-LLM, a novel approach that grounds language models within structured representations derived from open-vocabulary scene graphs, dynamically updated as the environment is explored. We tightly interleave these representations with an object-centric action space. The resulting approach is zero-shot, open-vocabulary, and readily extendable to a spectrum of mobile manipulation and household robotic tasks. We demonstrate the effectiveness of MoMa-LLM in a novel semantic interactive search task in large realistic indoor environments. In extensive experiments in both simulation and the real world, we show substantially improved search efficiency compared to conventional baselines and state-of-the-art approaches, as well as its applicability to more abstract tasks. We make the code publicly available at http://moma-llm.cs.uni-freiburg.de.
FIFA: Fast Inference Approximation for Action Segmentation
Aug 09, 2021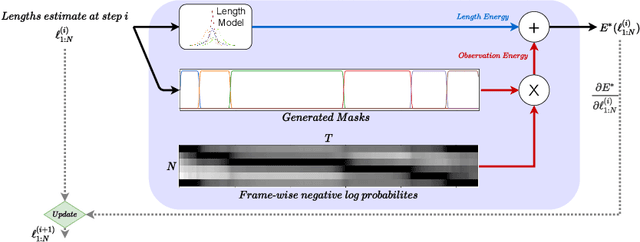
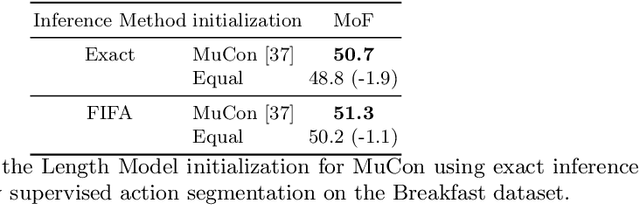
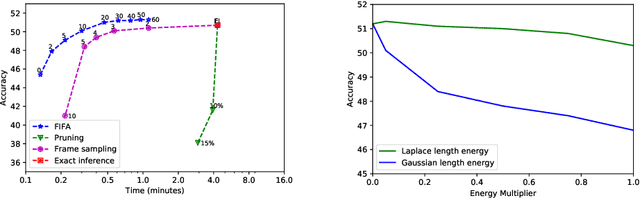
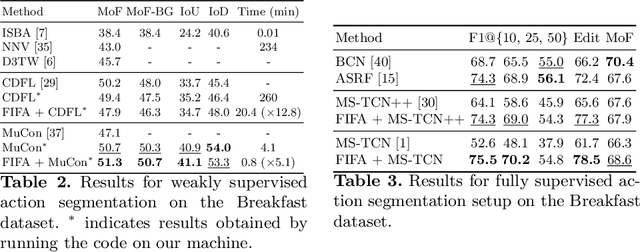
We introduce FIFA, a fast approximate inference method for action segmentation and alignment. Unlike previous approaches, FIFA does not rely on expensive dynamic programming for inference. Instead, it uses an approximate differentiable energy function that can be minimized using gradient-descent. FIFA is a general approach that can replace exact inference improving its speed by more than 5 times while maintaining its performance. FIFA is an anytime inference algorithm that provides a better speed vs. accuracy trade-off compared to exact inference. We apply FIFA on top of state-of-the-art approaches for weakly supervised action segmentation and alignment as well as fully supervised action segmentation. FIFA achieves state-of-the-art results on most metrics on two action segmentation datasets.
MIcro-Surgical Anastomose Workflow recognition challenge report
Mar 24, 2021



The "MIcro-Surgical Anastomose Workflow recognition on training sessions" (MISAW) challenge provided a data set of 27 sequences of micro-surgical anastomosis on artificial blood vessels. This data set was composed of videos, kinematics, and workflow annotations described at three different granularity levels: phase, step, and activity. The participants were given the option to use kinematic data and videos to develop workflow recognition models. Four tasks were proposed to the participants: three of them were related to the recognition of surgical workflow at three different granularity levels, while the last one addressed the recognition of all granularity levels in the same model. One ranking was made for each task. We used the average application-dependent balanced accuracy (AD-Accuracy) as the evaluation metric. This takes unbalanced classes into account and it is more clinically relevant than a frame-by-frame score. Six teams, including a non-competing team, participated in at least one task. All models employed deep learning models, such as CNN or RNN. The best models achieved more than 95% AD-Accuracy for phase recognition, 80% for step recognition, 60% for activity recognition, and 75% for all granularity levels. For high levels of granularity (i.e., phases and steps), the best models had a recognition rate that may be sufficient for applications such as prediction of remaining surgical time or resource management. However, for activities, the recognition rate was still low for applications that can be employed clinically. The MISAW data set is publicly available to encourage further research in surgical workflow recognition. It can be found at www.synapse.org/MISAW