 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMORE: Mobile Manipulation Rearrangement Through Grounded Language Reasoning
May 05, 2025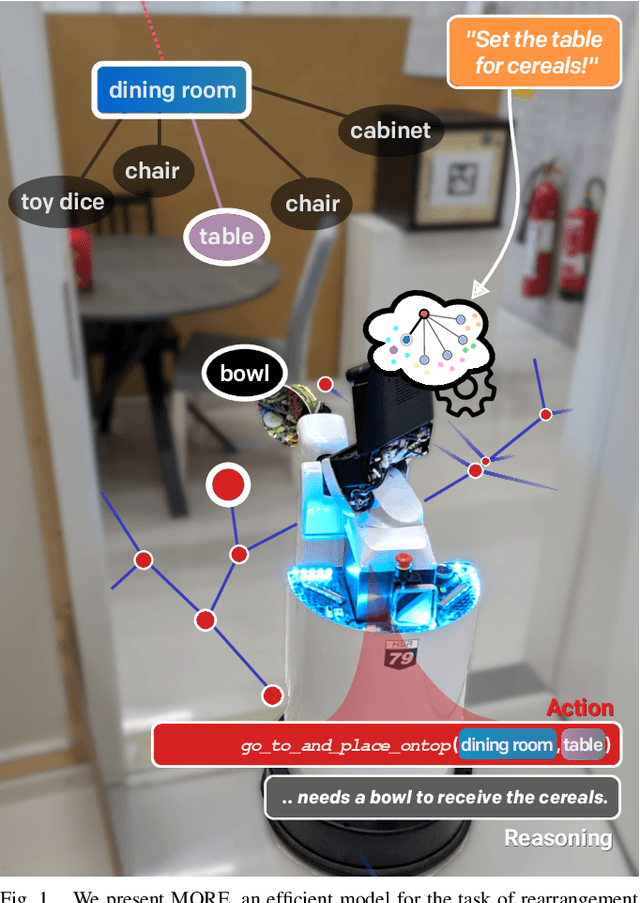
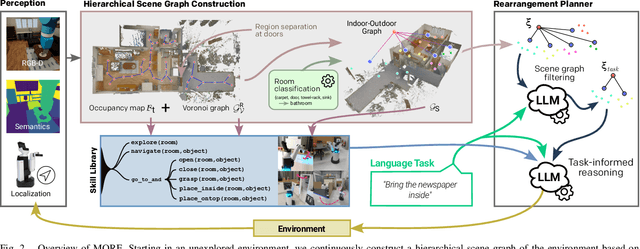
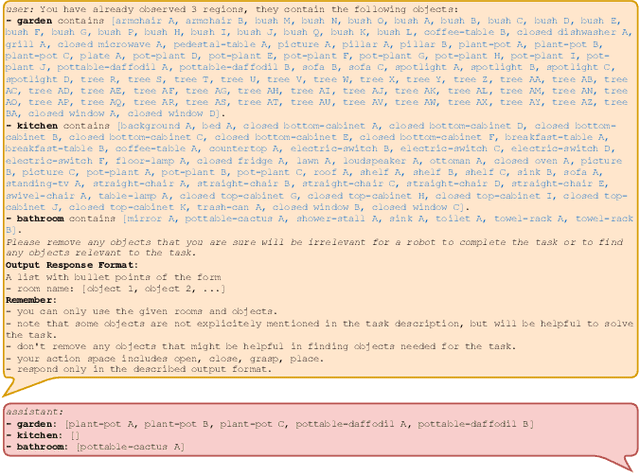
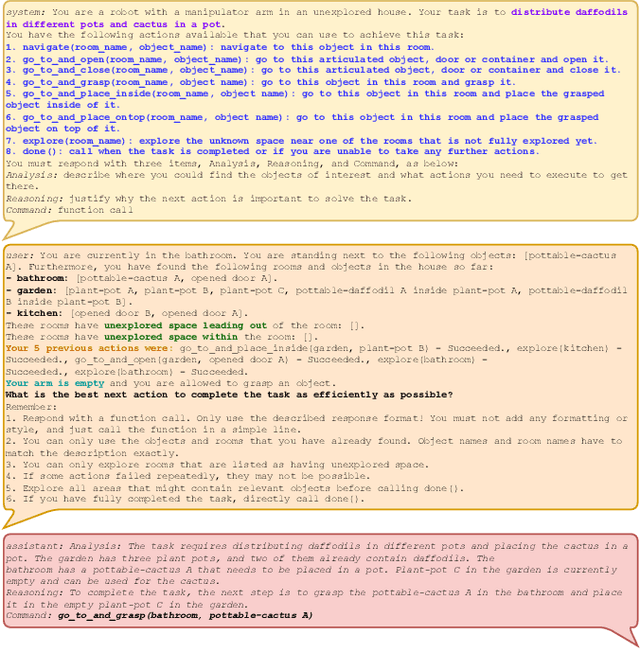
Autonomous long-horizon mobile manipulation encompasses a multitude of challenges, including scene dynamics, unexplored areas, and error recovery. Recent works have leveraged foundation models for scene-level robotic reasoning and planning. However, the performance of these methods degrades when dealing with a large number of objects and large-scale environments. To address these limitations, we propose MORE, a novel approach for enhancing the capabilities of language models to solve zero-shot mobile manipulation planning for rearrangement tasks. MORE leverages scene graphs to represent environments, incorporates instance differentiation, and introduces an active filtering scheme that extracts task-relevant subgraphs of object and region instances. These steps yield a bounded planning problem, effectively mitigating hallucinations and improving reliability. Additionally, we introduce several enhancements that enable planning across both indoor and outdoor environments. We evaluate MORE on 81 diverse rearrangement tasks from the BEHAVIOR-1K benchmark, where it becomes the first approach to successfully solve a significant share of the benchmark, outperforming recent foundation model-based approaches. Furthermore, we demonstrate the capabilities of our approach in several complex real-world tasks, mimicking everyday activities. We make the code publicly available at https://more-model.cs.uni-freiburg.de.
Task-Driven Co-Design of Mobile Manipulators
Dec 21, 2024Recent interest in mobile manipulation has resulted in a wide range of new robot designs. A large family of these designs focuses on modular platforms that combine existing mobile bases with static manipulator arms. They combine these modules by mounting the arm in a tabletop configuration. However, the operating workspaces and heights for common mobile manipulation tasks, such as opening articulated objects, significantly differ from tabletop manipulation tasks. As a result, these standard arm mounting configurations can result in kinematics with restricted joint ranges and motions. To address these problems, we present the first Concurrent Design approach for mobile manipulators to optimize key arm-mounting parameters. Our approach directly targets task performance across representative household tasks by training a powerful multitask-capable reinforcement learning policy in an inner loop while optimizing over a distribution of design configurations guided by Bayesian Optimization and HyperBand (BOHB) in an outer loop. This results in novel designs that significantly improve performance across both seen and unseen test tasks, and outperform designs generated by heuristic-based performance indices that are cheaper to evaluate but only weakly correlated with the motions of interest. We evaluate the physical feasibility of the resulting designs and show that they are practical and remain modular, affordable, and compatible with existing commercial components. We open-source the approach and generated designs to facilitate further improvements of these platforms.
Perception Matters: Enhancing Embodied AI with Uncertainty-Aware Semantic Segmentation
Aug 05, 2024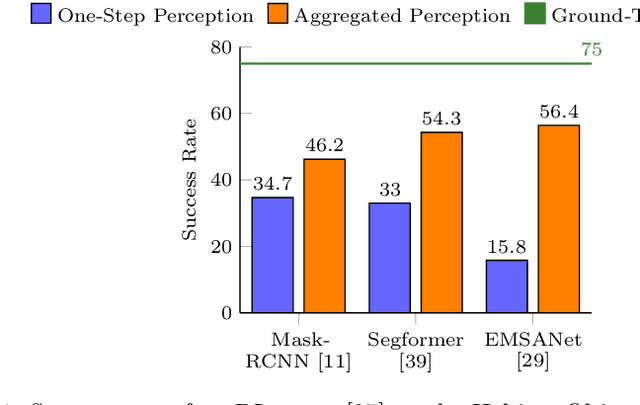

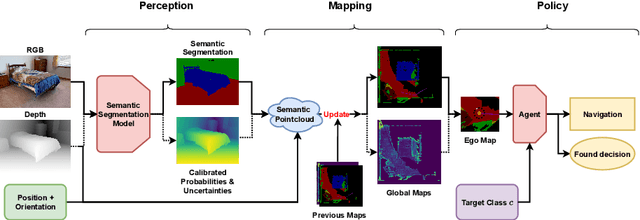
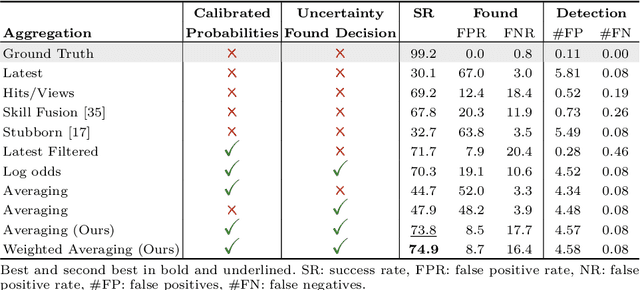
Embodied AI has made significant progress acting in unexplored environments. However, tasks such as object search have largely focused on efficient policy learning. In this work, we identify several gaps in current search methods: They largely focus on dated perception models, neglect temporal aggregation, and transfer from ground truth directly to noisy perception at test time, without accounting for the resulting overconfidence in the perceived state. We address the identified problems through calibrated perception probabilities and uncertainty across aggregation and found decisions, thereby adapting the models for sequential tasks. The resulting methods can be directly integrated with pretrained models across a wide family of existing search approaches at no additional training cost. We perform extensive evaluations of aggregation methods across both different semantic perception models and policies, confirming the importance of calibrated uncertainties in both the aggregation and found decisions. We make the code and trained models available at http://semantic-search.cs.uni-freiburg.de.
Language-Grounded Dynamic Scene Graphs for Interactive Object Search with Mobile Manipulation
Mar 14, 2024



To fully leverage the capabilities of mobile manipulation robots, it is imperative that they are able to autonomously execute long-horizon tasks in large unexplored environments. While large language models (LLMs) have shown emergent reasoning skills on arbitrary tasks, existing work primarily concentrates on explored environments, typically focusing on either navigation or manipulation tasks in isolation. In this work, we propose MoMa-LLM, a novel approach that grounds language models within structured representations derived from open-vocabulary scene graphs, dynamically updated as the environment is explored. We tightly interleave these representations with an object-centric action space. The resulting approach is zero-shot, open-vocabulary, and readily extendable to a spectrum of mobile manipulation and household robotic tasks. We demonstrate the effectiveness of MoMa-LLM in a novel semantic interactive search task in large realistic indoor environments. In extensive experiments in both simulation and the real world, we show substantially improved search efficiency compared to conventional baselines and state-of-the-art approaches, as well as its applicability to more abstract tasks. We make the code publicly available at http://moma-llm.cs.uni-freiburg.de.
Learning Hierarchical Interactive Multi-Object Search for Mobile Manipulation
Jul 12, 2023Existing object-search approaches enable robots to search through free pathways, however, robots operating in unstructured human-centered environments frequently also have to manipulate the environment to their needs. In this work, we introduce a novel interactive multi-object search task in which a robot has to open doors to navigate rooms and search inside cabinets and drawers to find target objects. These new challenges require combining manipulation and navigation skills in unexplored environments. We present HIMOS, a hierarchical reinforcement learning approach that learns to compose exploration, navigation, and manipulation skills. To achieve this, we design an abstract high-level action space around a semantic map memory and leverage the explored environment as instance navigation points. We perform extensive experiments in simulation and the real-world that demonstrate that HIMOS effectively transfers to new environments in a zero-shot manner. It shows robustness to unseen subpolicies, failures in their execution, and different robot kinematics. These capabilities open the door to a wide range of downstream tasks across embodied AI and real-world use cases.
Active Particle Filter Networks: Efficient Active Localization in Continuous Action Spaces and Large Maps
Sep 20, 2022


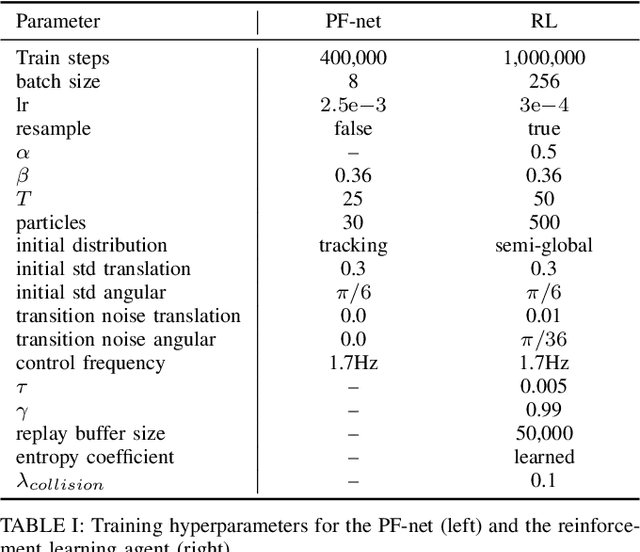
Accurate localization is a critical requirement for most robotic tasks. The main body of existing work is focused on passive localization in which the motions of the robot are assumed given, abstracting from their influence on sampling informative observations. While recent work has shown the benefits of learning motions to disambiguate the robot's poses, these methods are restricted to granular discrete actions and directly depend on the size of the global map. We propose Active Particle Filter Networks (APFN), an approach that only relies on local information for both the likelihood evaluation as well as the decision making. To do so, we couple differentiable particle filters with a reinforcement learning agent that attends to the most relevant parts of the map. The resulting approach inherits the computational benefits of particle filters and can directly act in continuous action spaces while remaining fully differentiable and thereby end-to-end optimizable as well as agnostic to the input modality. We demonstrate the benefits of our approach with extensive experiments in photorealistic indoor environments built from real-world 3D scanned apartments. Videos and code are available at http://apfn.cs.uni-freiburg.de.
N$^2$M$^2$: Learning Navigation for Arbitrary Mobile Manipulation Motions in Unseen and Dynamic Environments
Jun 17, 2022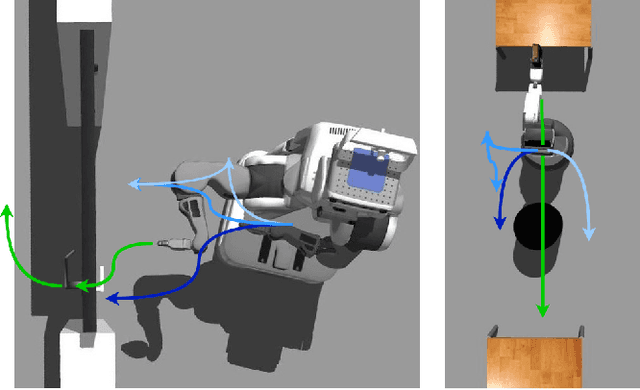
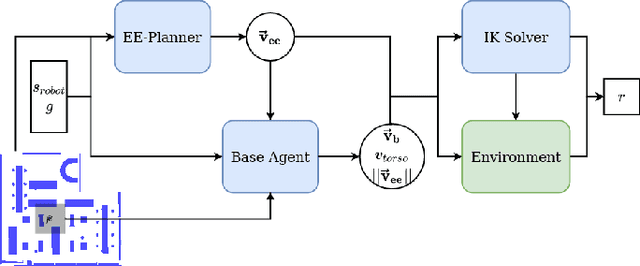


Despite its importance in both industrial and service robotics, mobile manipulation remains a significant challenge as it requires a seamless integration of end-effector trajectory generation with navigation skills as well as reasoning over long-horizons. Existing methods struggle to control the large configuration space, and to navigate dynamic and unknown environments. In previous work, we proposed to decompose mobile manipulation tasks into a simplified motion generator for the end-effector in task space and a trained reinforcement learning agent for the mobile base to account for kinematic feasibility of the motion. In this work, we introduce Neural Navigation for Mobile Manipulation (N$^2$M$^2$) which extends this decomposition to complex obstacle environments and enables it to tackle a broad range of tasks in real world settings. The resulting approach can perform unseen, long-horizon tasks in unexplored environments while instantly reacting to dynamic obstacles and environmental changes. At the same time, it provides a simple way to define new mobile manipulation tasks. We demonstrate the capabilities of our proposed approach in extensive simulation and real-world experiments on multiple kinematically diverse mobile manipulators. Code and videos are publicly available at http://mobile-rl.cs.uni-freiburg.de.
Learning Long-Horizon Robot Exploration Strategies for Multi-Object Search in Continuous Action Spaces
May 24, 2022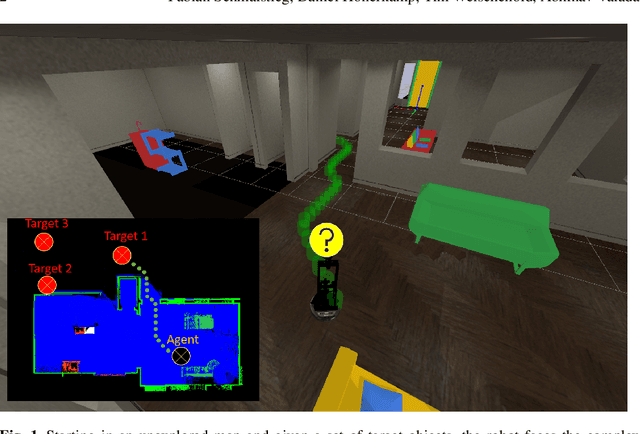
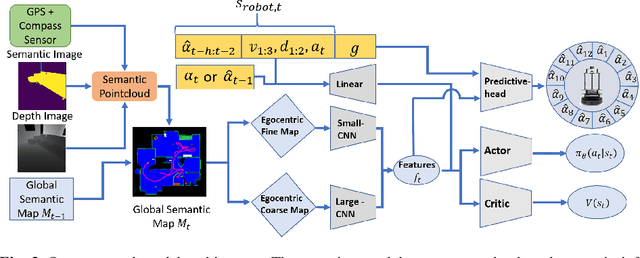
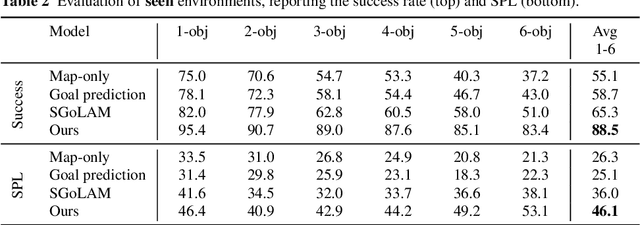
Recent advances in vision-based navigation and exploration have shown impressive capabilities in photorealistic indoor environments. However, these methods still struggle with long-horizon tasks and require large amounts of data to generalize to unseen environments. In this work, we present a novel reinforcement learning approach for multi-object search that combines short-term and long-term reasoning in a single model while avoiding the complexities arising from hierarchical structures. In contrast to existing multi-object search methods that act in granular discrete action spaces, our approach achieves exceptional performance in continuous action spaces. We perform extensive experiments and show that it generalizes to unseen apartment environments with limited data. Furthermore, we demonstrate zero-shot transfer of the learned policies to an office environment in real world experiments.
Catch Me If You Hear Me: Audio-Visual Navigation in Complex Unmapped Environments with Moving Sounds
Nov 29, 2021



Audio-visual navigation combines sight and hearing to navigate to a sound-emitting source in an unmapped environment. While recent approaches have demonstrated the benefits of audio input to detect and find the goal, they focus on clean and static sound sources and struggle to generalize to unheard sounds. In this work, we propose the novel dynamic audio-visual navigation benchmark which requires to catch a moving sound source in an environment with noisy and distracting sounds. We introduce a reinforcement learning approach that learns a robust navigation policy for these complex settings. To achieve this, we propose an architecture that fuses audio-visual information in the spatial feature space to learn correlations of geometric information inherent in both local maps and audio signals. We demonstrate that our approach consistently outperforms the current state-of-the-art by a large margin across all tasks of moving sounds, unheard sounds, and noisy environments, on two challenging 3D scanned real-world environments, namely Matterport3D and Replica. The benchmark is available at http://dav-nav.cs.uni-freiburg.de.
Learning Kinematic Feasibility for Mobile Manipulation through Deep Reinforcement Learning
Jan 13, 2021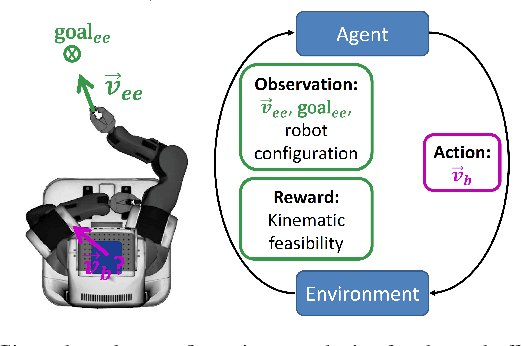
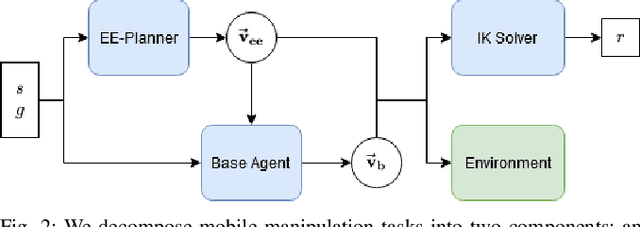
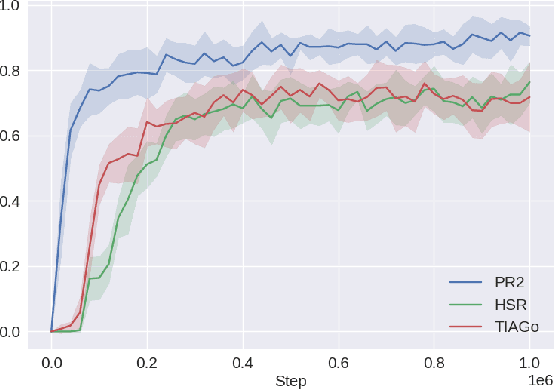
Mobile manipulation tasks remain one of the critical challenges for the widespread adoption of autonomous robots in both service and industrial scenarios. While planning approaches are good at generating feasible whole-body robot trajectories, they struggle with dynamic environments as well as the incorporation of constraints given by the task and the environment. On the other hand, dynamic motion models in the action space struggle with generating kinematically feasible trajectories for mobile manipulation actions. We propose a deep reinforcement learning approach to learn feasible dynamic motions for a mobile base while the end-effector follows a trajectory in task space generated by an arbitrary system to fulfill the task at hand. This modular formulation has several benefits: it enables us to readily transform a broad range of end-effector motions into mobile applications, it allows us to use the kinematic feasibility of the end-effector trajectory as a dense reward signal and its modular formulation allows it to generalise to unseen end-effector motions at test time. We demonstrate the capabilities of our approach on multiple mobile robot platforms with different kinematic abilities and different types of wheeled platforms in extensive simulated as well as real-world experiments.