 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception Matters: Enhancing Embodied AI with Uncertainty-Aware Semantic Segmentation
Aug 05, 2024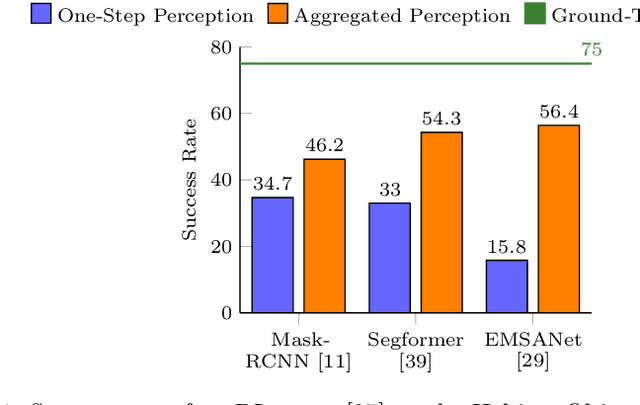

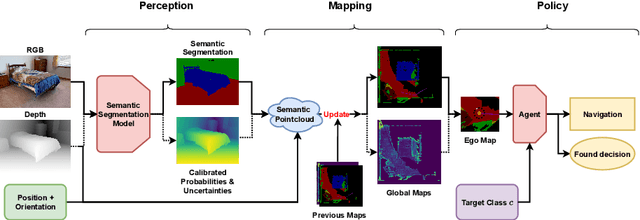
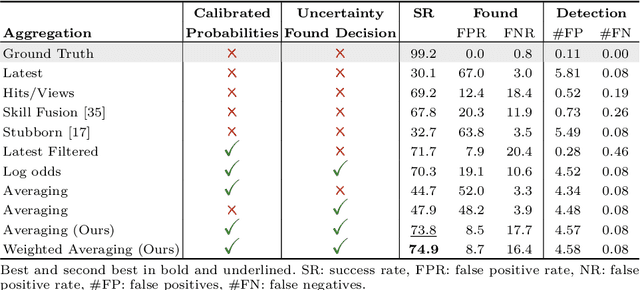
Embodied AI has made significant progress acting in unexplored environments. However, tasks such as object search have largely focused on efficient policy learning. In this work, we identify several gaps in current search methods: They largely focus on dated perception models, neglect temporal aggregation, and transfer from ground truth directly to noisy perception at test time, without accounting for the resulting overconfidence in the perceived state. We address the identified problems through calibrated perception probabilities and uncertainty across aggregation and found decisions, thereby adapting the models for sequential tasks. The resulting methods can be directly integrated with pretrained models across a wide family of existing search approaches at no additional training cost. We perform extensive evaluations of aggregation methods across both different semantic perception models and policies, confirming the importance of calibrated uncertainties in both the aggregation and found decisions. We make the code and trained models available at http://semantic-search.cs.uni-freiburg.de.
Dreaming of Many Worlds: Learning Contextual World Models Aids Zero-Shot Generalization
Mar 16, 2024



Zero-shot generalization (ZSG) to unseen dynamics is a major challenge for creating generally capable embodied agents. To address the broader challenge, we start with the simpler setting of contextual reinforcement learning (cRL), assuming observability of the context values that parameterize the variation in the system's dynamics, such as the mass or dimensions of a robot, without making further simplifying assumptions about the observability of the Markovian state. Toward the goal of ZSG to unseen variation in context, we propose the contextual recurrent state-space model (cRSSM), which introduces changes to the world model of the Dreamer (v3) (Hafner et al., 2023). This allows the world model to incorporate context for inferring latent Markovian states from the observations and modeling the latent dynamics. Our experiments show that such systematic incorporation of the context improves the ZSG of the policies trained on the ``dreams'' of the world model. We further find qualitatively that our approach allows Dreamer to disentangle the latent state from context, allowing it to extrapolate its dreams to the many worlds of unseen contexts. The code for all our experiments is available at \url{https://github.com/sai-prasanna/dreaming_of_many_worlds}.
When BERT Plays the Lottery, All Tickets Are Winning
May 01, 2020
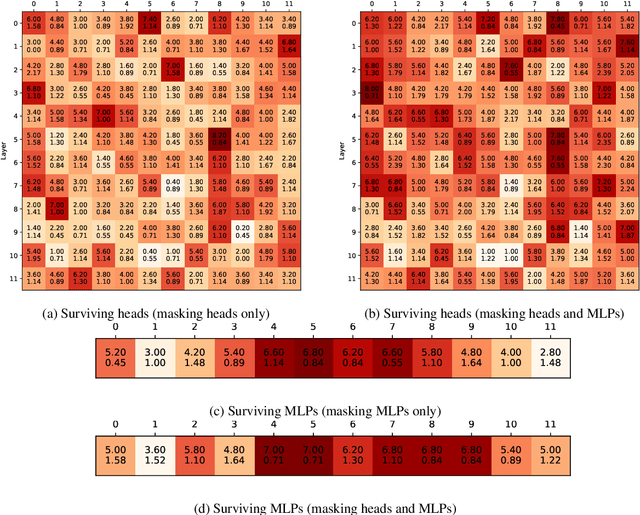
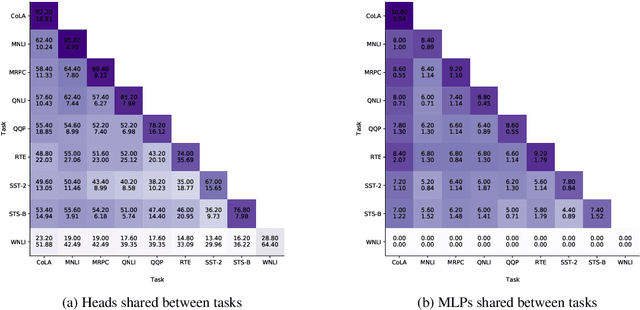
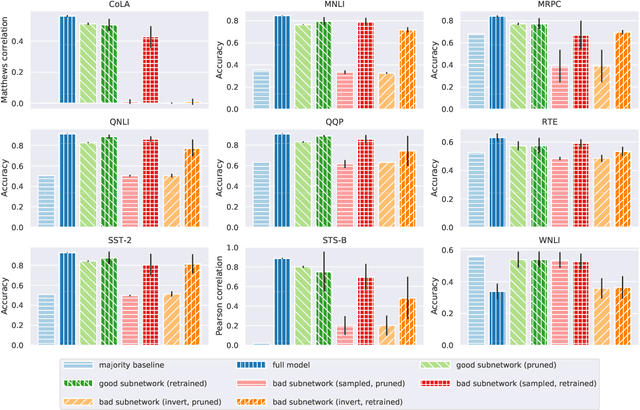
Much of the recent success in NLP is due to the large Transformer-based models such as BERT (Devlin et al, 2019). However, these models have been shown to be reducible to a smaller number of self-attention heads and layers. We consider this phenomenon from the perspective of the lottery ticket hypothesis. For fine-tuned BERT, we show that (a) it is possible to find a subnetwork of elements that achieves performance comparable with that of the full model, and (b) similarly-sized subnetworks sampled from the rest of the model perform worse. However, the "bad" subnetworks can be fine-tuned separately to achieve only slightly worse performance than the "good" ones, indicating that most weights in the pre-trained BERT are potentially useful. We also show that the "good" subnetworks vary considerably across GLUE tasks, opening up the possibilities to learn what knowledge BERT actually uses at inference time.
Zoho at SemEval-2019 Task 9: Semi-supervised Domain Adaptation using Tri-training for Suggestion Mining
Apr 06, 2019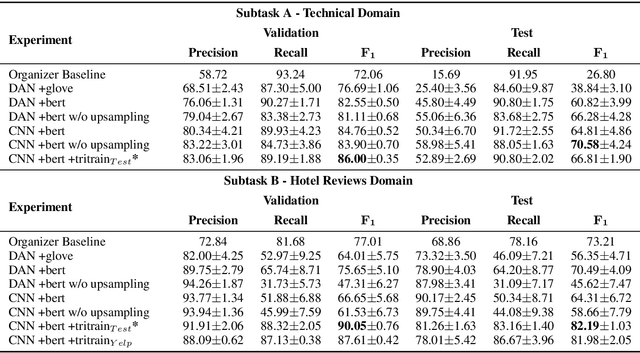


This paper describes our submission for the SemEval-2019 Suggestion Mining task. A simple Convolutional Neural Network (CNN) classifier with contextual word representations from a pre-trained language model was used for sentence classification. The model is trained using tri-training, a semi-supervised bootstrapping mechanism for labelling unseen data. Tri-training proved to be an effective technique to accommodate domain shift for cross-domain suggestion mining (Subtask B) where there is no hand labelled training data. For in-domain evaluation (Subtask A), we use the same technique to augment the training set. Our system ranks thirteenth in Subtask A with an $F_1$-score of 68.07 and third in Subtask B with an $F_1$-score of 81.94.