 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrbis: Overcoming Challenges of Long-Horizon Prediction in Driving World Models
Jul 17, 2025Existing world models for autonomous driving struggle with long-horizon generation and generalization to challenging scenarios. In this work, we develop a model using simple design choices, and without additional supervision or sensors, such as maps, depth, or multiple cameras. We show that our model yields state-of-the-art performance, despite having only 469M parameters and being trained on 280h of video data. It particularly stands out in difficult scenarios like turning maneuvers and urban traffic. We test whether discrete token models possibly have advantages over continuous models based on flow matching. To this end, we set up a hybrid tokenizer that is compatible with both approaches and allows for a side-by-side comparison. Our study concludes in favor of the continuous autoregressive model, which is less brittle on individual design choices and more powerful than the model built on discrete tokens. Code, models and qualitative results are publicly available at https://lmb-freiburg.github.io/orbis.github.io/.
Dreaming of Many Worlds: Learning Contextual World Models Aids Zero-Shot Generalization
Mar 16, 2024



Zero-shot generalization (ZSG) to unseen dynamics is a major challenge for creating generally capable embodied agents. To address the broader challenge, we start with the simpler setting of contextual reinforcement learning (cRL), assuming observability of the context values that parameterize the variation in the system's dynamics, such as the mass or dimensions of a robot, without making further simplifying assumptions about the observability of the Markovian state. Toward the goal of ZSG to unseen variation in context, we propose the contextual recurrent state-space model (cRSSM), which introduces changes to the world model of the Dreamer (v3) (Hafner et al., 2023). This allows the world model to incorporate context for inferring latent Markovian states from the observations and modeling the latent dynamics. Our experiments show that such systematic incorporation of the context improves the ZSG of the policies trained on the ``dreams'' of the world model. We further find qualitatively that our approach allows Dreamer to disentangle the latent state from context, allowing it to extrapolate its dreams to the many worlds of unseen contexts. The code for all our experiments is available at \url{https://github.com/sai-prasanna/dreaming_of_many_worlds}.
Latent Diffusion Counterfactual Explanations
Oct 10, 2023



Counterfactual explanations have emerged as a promising method for elucidating the behavior of opaque black-box models. Recently, several works leveraged pixel-space diffusion models for counterfactual generation. To handle noisy, adversarial gradients during counterfactual generation -- causing unrealistic artifacts or mere adversarial perturbations -- they required either auxiliary adversarially robust models or computationally intensive guidance schemes. However, such requirements limit their applicability, e.g., in scenarios with restricted access to the model's training data. To address these limitations, we introduce Latent Diffusion Counterfactual Explanations (LDCE). LDCE harnesses the capabilities of recent class- or text-conditional foundation latent diffusion models to expedite counterfactual generation and focus on the important, semantic parts of the data. Furthermore, we propose a novel consensus guidance mechanism to filter out noisy, adversarial gradients that are misaligned with the diffusion model's implicit classifier. We demonstrate the versatility of LDCE across a wide spectrum of models trained on diverse datasets with different learning paradigms. Finally, we showcase how LDCE can provide insights into model errors, enhancing our understanding of black-box model behavior.
Few Shot System Identification for Reinforcement Learning
Mar 30, 2021
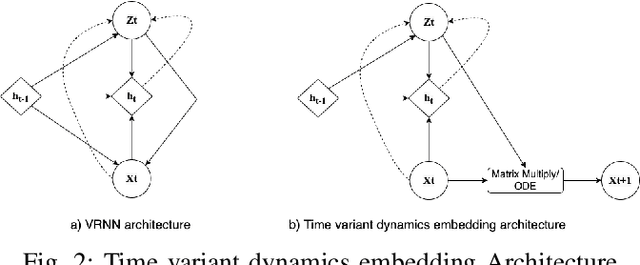
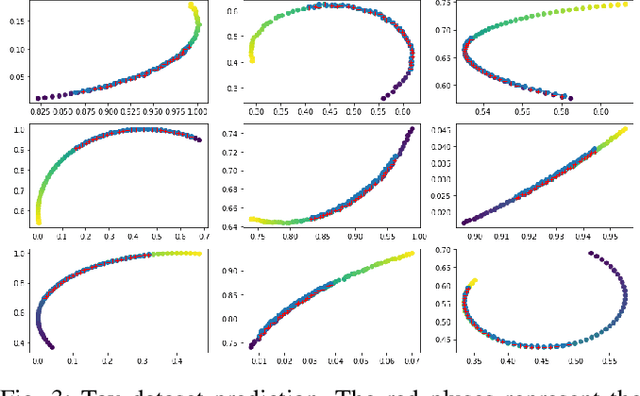
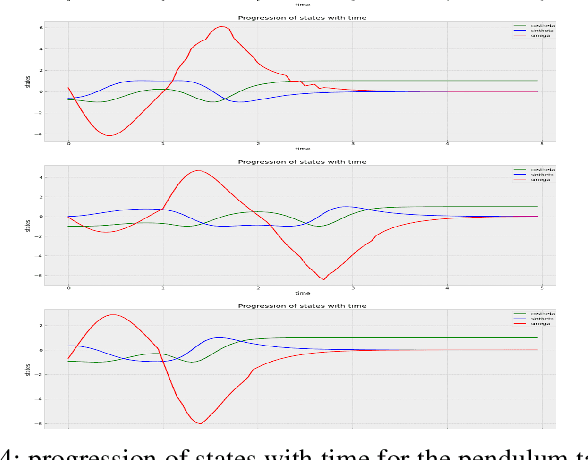
Learning by interaction is the key to skill acquisition for most living organisms, which is formally called Reinforcement Learning (RL). RL is efficient in finding optimal policies for endowing complex systems with sophisticated behavior. All paradigms of RL utilize a system model for finding the optimal policy. Modeling dynamics can be done by formulating a mathematical model or system identification. Dynamic models are usually exposed to aleatoric and epistemic uncertainties that can divert the model from the one acquired and cause the RL algorithm to exhibit erroneous behavior. Accordingly, the RL process sensitive to operating conditions and changes in model parameters and lose its generality. To address these problems, Intensive system identification for modeling purposes is needed for each system even if the model dynamics structure is the same, as the slight deviation in the model parameters can render the model useless in RL. The existence of an oracle that can adaptively predict the rest of the trajectory regardless of the uncertainties can help resolve the issue. The target of this work is to present a framework for facilitating the system identification of different instances of the same dynamics class by learning a probability distribution of the dynamics conditioned on observed data with variational inference and show its reliability in robustly solving different instances of control problems with the same model in model-based RL with maximum sample efficiency.