Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZoho at SemEval-2019 Task 9: Semi-supervised Domain Adaptation using Tri-training for Suggestion Mining
Paper and Code
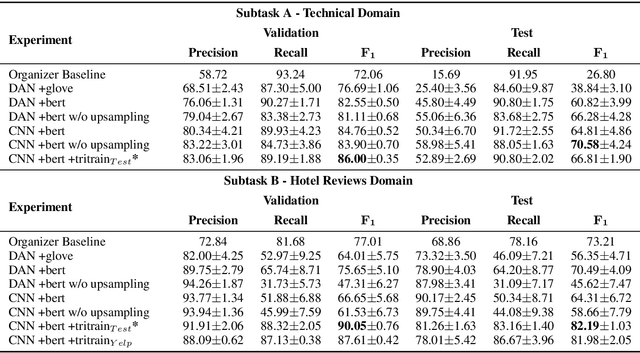


This paper describes our submission for the SemEval-2019 Suggestion Mining task. A simple Convolutional Neural Network (CNN) classifier with contextual word representations from a pre-trained language model was used for sentence classification. The model is trained using tri-training, a semi-supervised bootstrapping mechanism for labelling unseen data. Tri-training proved to be an effective technique to accommodate domain shift for cross-domain suggestion mining (Subtask B) where there is no hand labelled training data. For in-domain evaluation (Subtask A), we use the same technique to augment the training set. Our system ranks thirteenth in Subtask A with an $F_1$-score of 68.07 and third in Subtask B with an $F_1$-score of 81.94.
* NAACL 2019
View paper on